Mecanismos de extractores personalizados
Puedes crear extractores personalizados que se adapten específicamente a tus documentos y que se entrenen y evalúen con tus datos. Este procesador identifica y extrae entidades de tus documentos. Después, puedes usar este procesador entrenado en documentos adicionales.
Antes de empezar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. En la Google Cloud consola, en la sección Document AI, ve a la página Workbench.
En Extractor personalizado, selecciona
Crear procesador .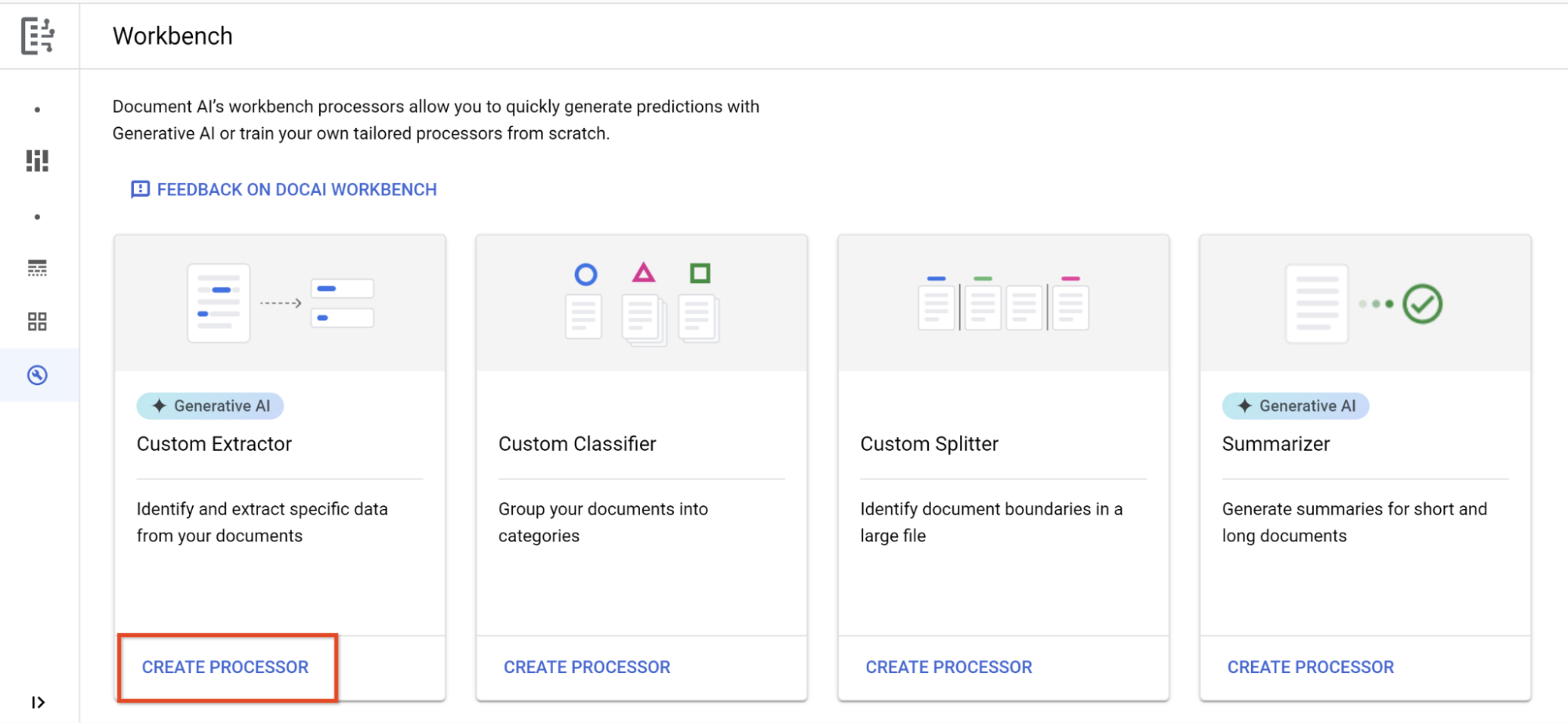
En el menú Crear procesador, escribe el nombre del procesador, como
my-custom-document-extractor.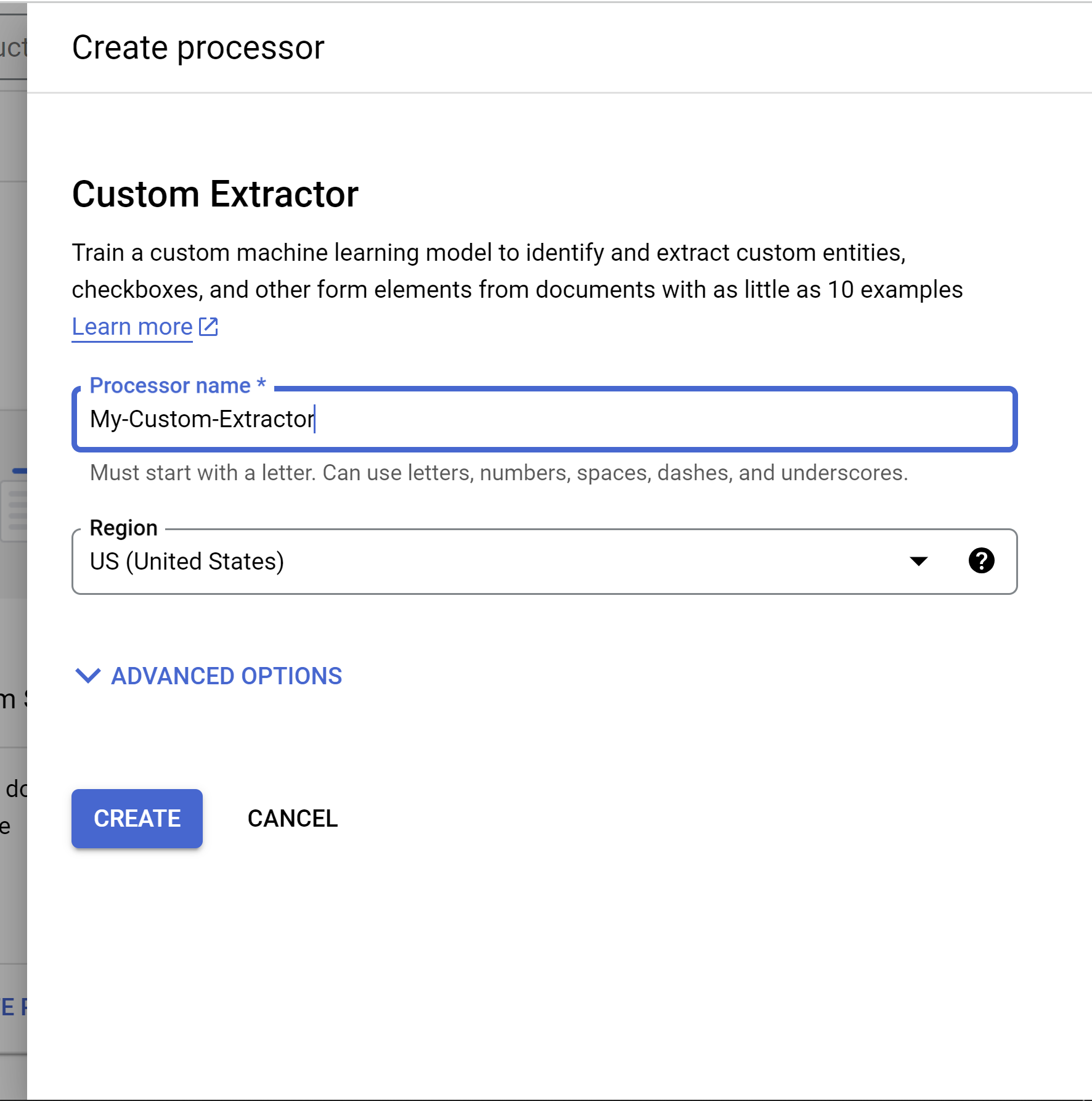
Selecciona la región más cercana.
Opcional: Abre Opciones avanzadas.
Puedes dejar que Google cree un segmento de Cloud Storage por ti o crear uno tú mismo. Para este tutorial, selecciona Almacenamiento gestionado por Google.
También puedes usar claves de encriptado gestionadas por Google o gestionadas por el cliente (CMEK). En este tutorial, seleccione Google-managed encryption key.
Selecciona Crear para crear el procesador.
Selecciona la pestaña
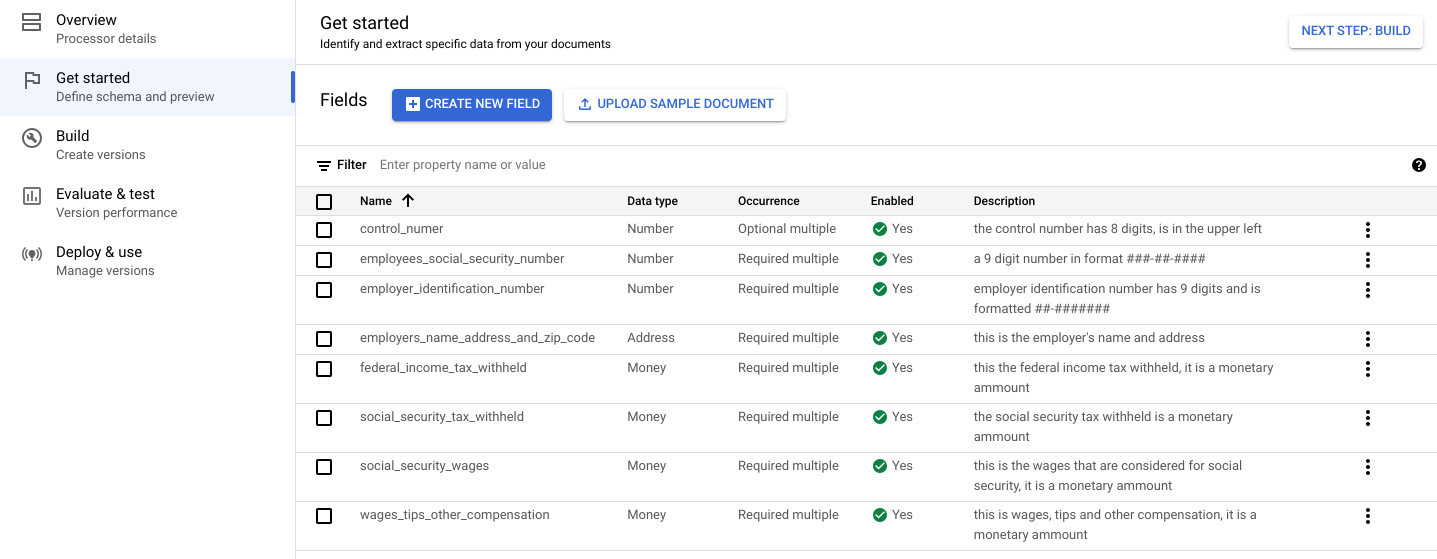
Empezar . Aparecerá el menú Campos.Seleccione Crear campo.
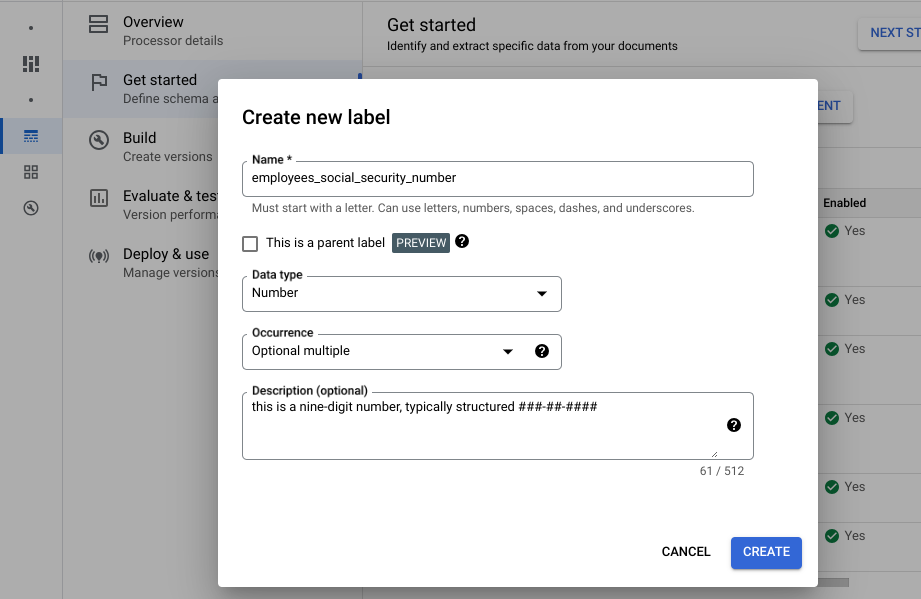
Escribe el nombre del campo. Selecciona el Tipo de datos y la Ocurrencia. Asigna a la etiqueta una descripción descriptiva y distinta. La descripción de la propiedad te permite proporcionar contexto, estadísticas y conocimientos previos adicionales para cada entidad con el fin de mejorar la precisión y el rendimiento de la extracción.
- Selecciona Crear. Consulta Definir el esquema del procesador para obtener instrucciones detalladas sobre cómo crear y editar un esquema.
Crea cada una de las siguientes etiquetas para el esquema del procesador.
Nombre Tipo de datos Occurrence control_numberNúmero Múltiple opcional employees_social_security_numberNúmero Obligatorio (múltiple) employer_identification_numberNúmero Obligatorio (múltiple) employers_name_address_and_zip_codeDirección Obligatorio (múltiple) federal_income_tax_withheldDinero Obligatorio (múltiple) social_security_tax_withheldDinero Obligatorio (múltiple) social_security_wagesDinero Obligatorio (múltiple) wages_tips_other_compensationDinero Obligatorio (múltiple) También puede crear y usar otros tipos de etiquetas en su esquema de procesador, como casillas de verificación y entidades tabulares. Por ejemplo, los formularios W-2 contienen casillas de verificación de empleado estatutario, plan de jubilación y prestación por enfermedad de terceros que también puedes añadir al esquema.
Selecciona Subir documento de muestra.
En la barra lateral, selecciona Importar documentos de Cloud Storage.
En este ejemplo, introduce el nombre del segmento en
Ruta de origen . Este enlace lleva directamente a un documento.cloud-samples-data/documentai/Custom/W2/PDF/W2_XL_input_clean_2950.pdfSelecciona Importar.
Cuando estés en la consola de etiquetado, verás que muchas de las etiquetas ya están rellenadas. Esto se debe a que el tipo de modelo de extractor personalizado predeterminado es un modelo fundacional, que puede realizar predicciones sin ejemplos, es decir, sin entrenamiento.
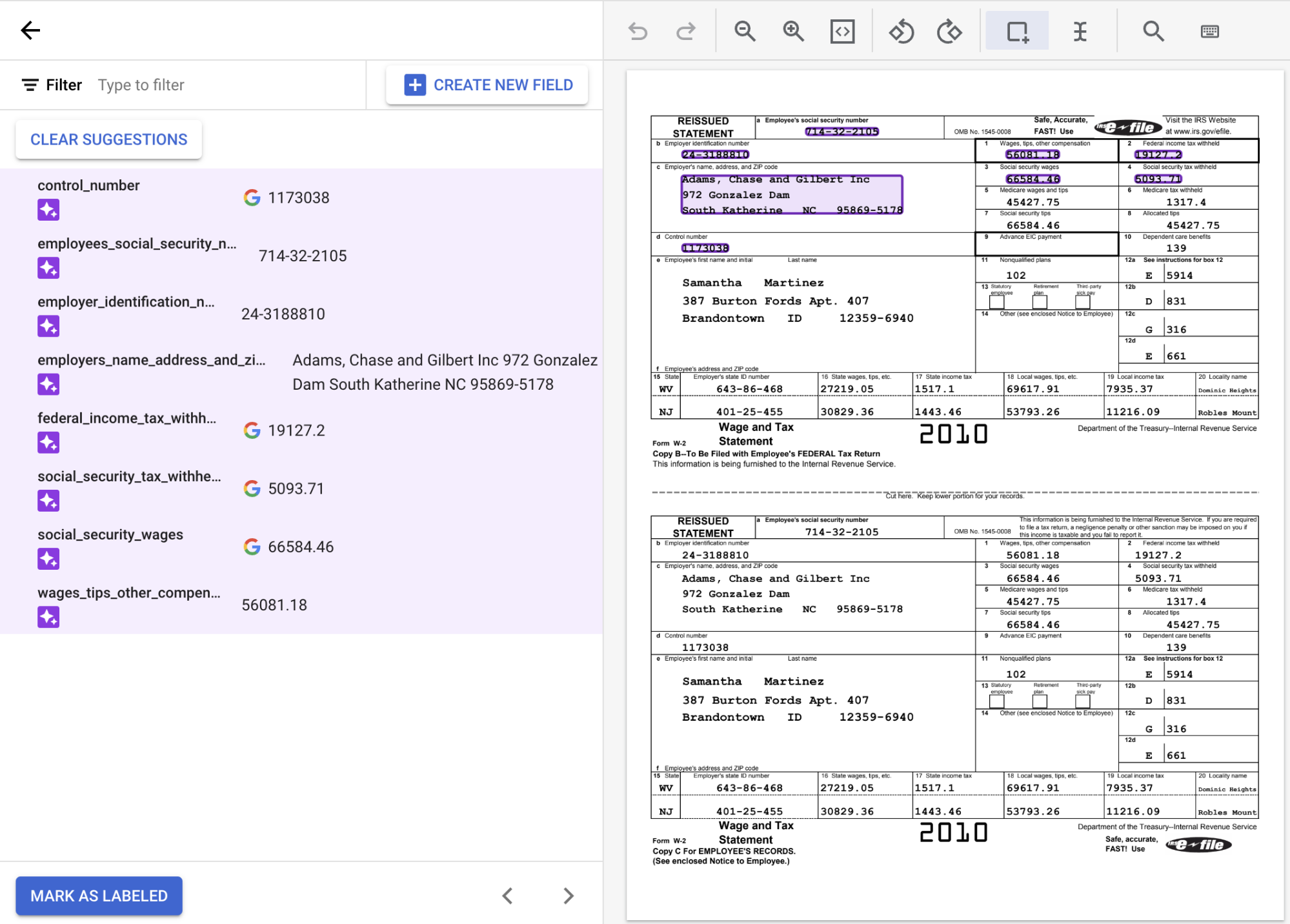
Para usar las etiquetas sugeridas, coloca el puntero sobre cada
etiqueta del panel lateral y selecciona la marca de verificación para confirmar que la etiqueta es correcta. No edites el texto, aunque el OCR lo lea de forma incorrecta.En este ejemplo, los valores de la parte inferior del documento no se han identificado automáticamente, por lo que debe etiquetarlos manualmente.
Usa los iconos de la barra de herramientas situada encima del documento para añadir etiquetas. Usa la herramienta
recuadro de selección de forma predeterminada o la herramientaSeleccionar texto para valores de varias líneas, selecciona el contenido y aplica la etiqueta.Una vez seleccionado el texto, aparecerá un menú desplegable con todos los campos (entidades) definidos para que elijas uno. En este ejemplo, se selecciona el valor de
wages_tips_other_compensationcon la herramienta de recuadro y se aplica esa etiqueta.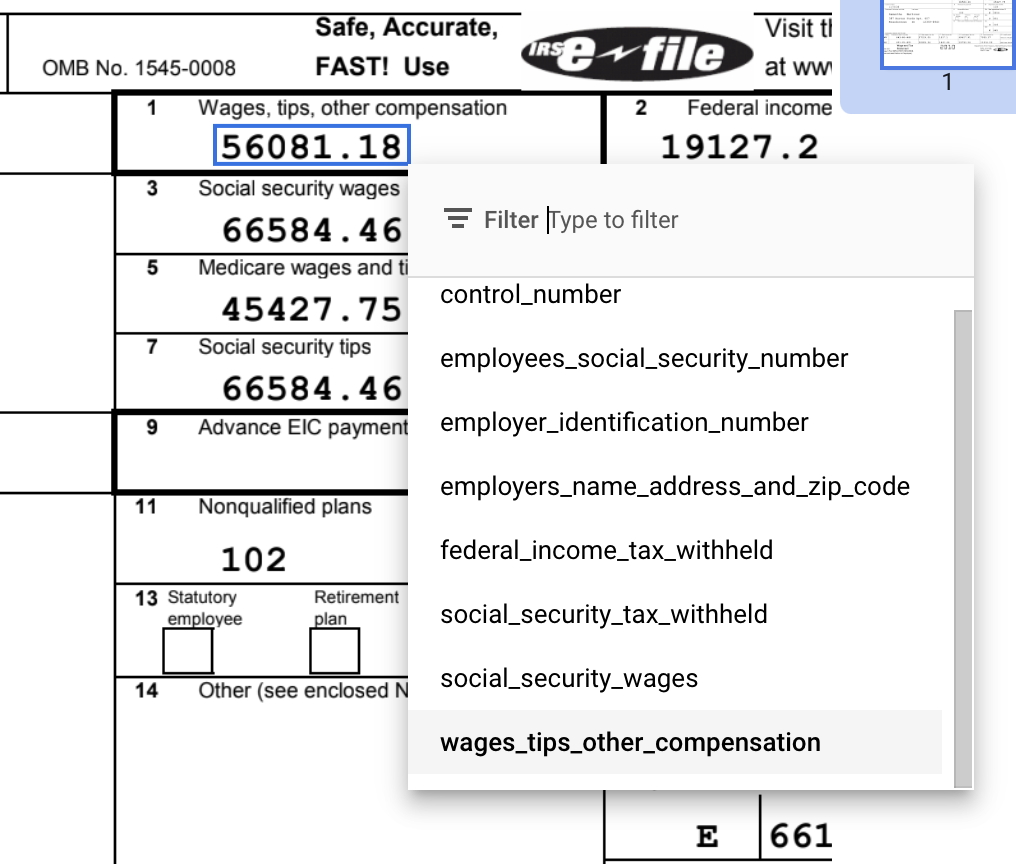
Revisa los valores de texto detectados para asegurarte de que reflejan la ubicación correcta del texto de cada campo. El documento W2 etiquetado debería tener este aspecto cuando esté completo:
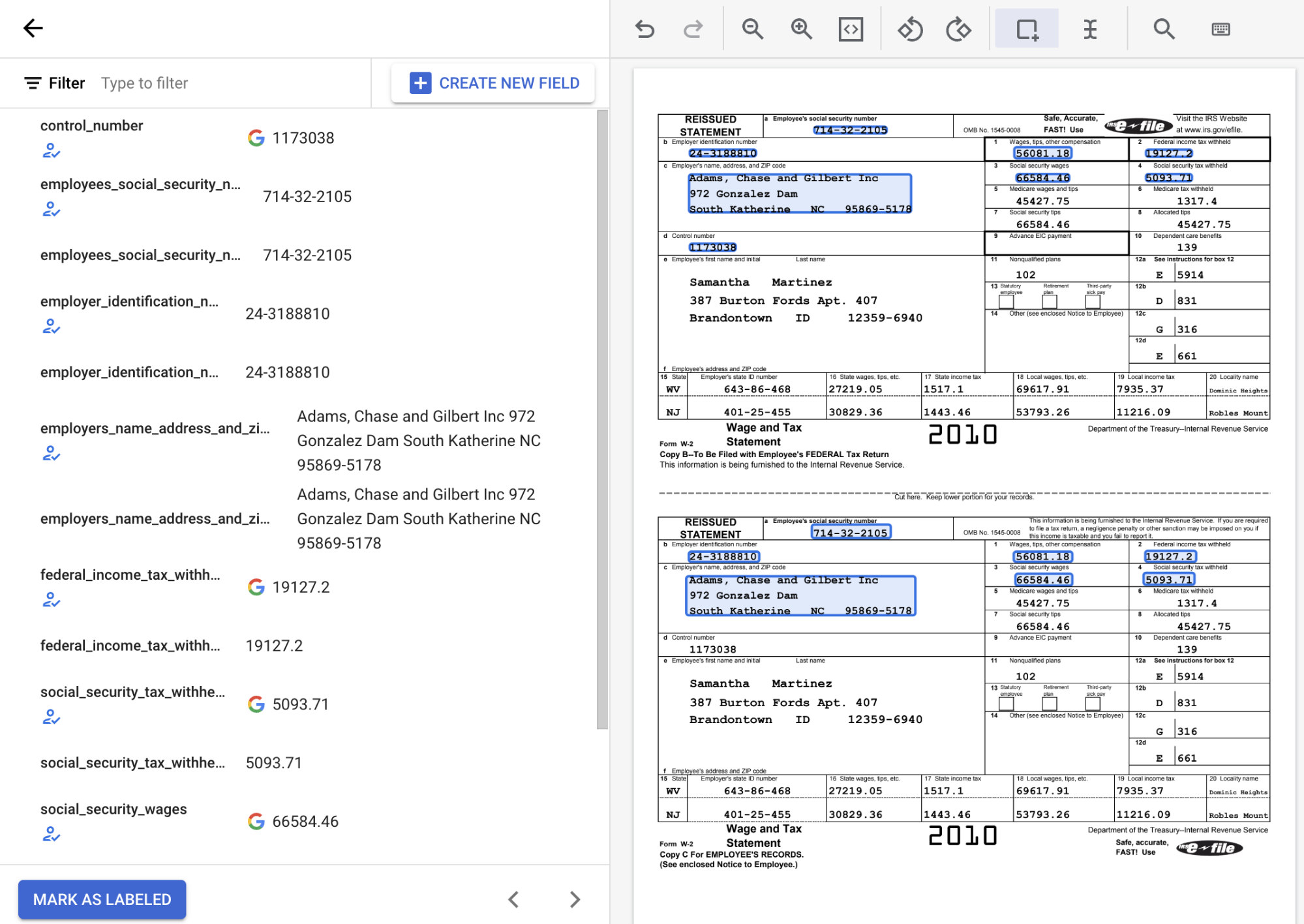
Si es necesario, puede seleccionar
Crear campo para añadir un campo al esquema desde esta página.Selecciona
Marcar como etiquetado cuando hayas terminado de anotar el documento. Se te redirigirá a la pestaña Empezar.Selecciona la pestaña
Crear .
En Llamar al modelo base, selecciona Crear nueva versión.
Escriba un nombre para la versión del procesador, como
w2-foundation-model.Selecciona Crear versión. Tarda unos minutos en crearse.
Opcional: selecciona la pestaña
Implementar y usar . En esta página, puede ver las versiones del procesador disponibles y el estado de implementación de la nueva versión.Ve a la página
Compilación .Selecciona
Importar documentos .En la barra lateral, selecciona Importar documentos de Google Cloud Storage.
Escribe el nombre del segmento que contiene tus documentos.
En la lista División de datos, seleccione División automática. De esta forma, los documentos se dividen automáticamente en un 80% para el conjunto de entrenamiento y un 20% para el conjunto de prueba.
En la sección Etiquetado automático, selecciona la casilla
Importar con etiquetado automático .Seleccione la versión del procesador del modelo fundacional para etiquetar los documentos.
Selecciona Importar y espera a que se importen los documentos. Puedes salir de esta página y volver más tarde.
Debes verificar los documentos etiquetados automáticamente antes de poder usarlos para entrenar o probar el modelo. Selecciona
Empezar a etiquetar para ver los documentos etiquetados automáticamente.Para usar las etiquetas sugeridas, coloca el puntero sobre cada
anotación y selecciona la marca de verificación para confirmar que la etiqueta es correcta. Por motivos de formación, no edites los valores si no coinciden con el texto del documento. Solo cambia el cuadro delimitador si se ha seleccionado el texto incorrecto.Selecciona
Marcar como etiquetado cuando hayas terminado de anotar el documento.Repite el proceso con cada documento etiquetado automáticamente.
Ve a la página
Compilación .Selecciona
Importar documentos .En la barra lateral, selecciona Importar documentos de Cloud Storage.
Introduce la ruta en Ruta de origen que contiene tus documentos. Este segmento debe contener documentos preetiquetados en formato JSON de documento.
En la lista División de datos, seleccione División automática. De esta forma, los documentos se dividen automáticamente en un 80% para el conjunto de entrenamiento y un 20% para el conjunto de prueba. Deje la opción Importar con etiquetado automático sin marcar.
Selecciona Importar. La importación tarda varios minutos.
- En la página Crear, puedes acceder a la consola
Gestionar conjunto de datos para ver y editar todos los documentos y etiquetas del conjunto de datos. Para obtener información sobre los requisitos del conjunto de datos, en Entrenar un modelo personalizado, selecciona Crear nueva versión o Ver todos los requisitos. No es un modelo de IA generativa. Se necesitan al menos 10 instancias de entrenamiento y 10 instancias de prueba de cada campo para un procesador basado en un modelo personalizado.
En el campo Nombre de la versión, introduce un nombre para esta versión del procesador, como
w2-custom-model.Opcional: selecciona Ver estadísticas de etiquetas para consultar información sobre las etiquetas del documento. Esto puede ayudarte a determinar tu cobertura. Selecciona Cerrar para volver a la configuración del entrenamiento.
En Método de entrenamiento del modelo, selecciona Basado en modelo.
Selecciona Iniciar formación. La preparación tarda unas horas. Puedes cerrar esta página y volver más tarde.
Opcional: selecciona la pestaña
Implementar y usar . En esta página, puede ver las versiones del procesador disponibles y el estado del entrenamiento de la nueva versión.Cuando se haya completado el entrenamiento, selecciona la pestaña
Desplegar y usar .Marca la casilla situada a la izquierda de la versión que quieras implementar y selecciona Implementar.
Selecciona Implementar en la ventana de diálogo. El despliegue tarda unos minutos.
Cuando se implementa la versión, puedes definirla como la
versión predeterminada o proporcionar el ID de la versión al procesar documentos con la API.Selecciona la pestaña
Evaluar para probar la versión del procesador. En esta página, puede ver métricas de evaluación, como la puntuación F1, la precisión y la recuperación del documento completo y de las etiquetas individuales. Para obtener más información sobre la evaluación y las estadísticas, consulta evaluate processor.Selecciona el selector
Versión y elige la versión que usa el modelo base.Descarga un documento que no se haya usado en entrenamientos ni pruebas anteriores para poder usarlo y evaluar la versión del procesador. Si usas tus propios datos, debes usar un documento específico para ello.
Selecciona
Subir documento de prueba y elige el documento que acabas de descargar. Se abrirá la página Análisis del extractor de documentos personalizado. El resultado de la pantalla muestra lo bien que se ha extraído el documento.Vuelve a probar el documento con la versión que incluye un modelo entrenado personalizado.
- Sigue los ejemplos de código que se indican en enviar una solicitud de procesamiento para usar el procesamiento online o por lotes.
- Consulta Cuotas y límites para ver el número de páginas admitidas en el procesamiento online y por lotes.
- Sigue el ejemplo de código del extractor personalizado en Gestionar la respuesta del procesamiento para obtener las entidades extraídas del procesador.
En el menú de navegación de la consola, selecciona Document AI y, a continuación, Mis procesadores. Google Cloud
Selecciona
Más acciones en la misma fila que el procesador que quieras eliminar.Selecciona Eliminar procesador, introduce el nombre del procesador y, a continuación, selecciona Eliminar de nuevo para confirmar la acción.
Crear un procesador
Definir campos de procesador
Ahora está en la página Resumen del procesador del procesador que acaba de crear.
Puede especificar los campos que quiere que extraiga el procesador y empezar a etiquetar documentos.
Subir un documento de muestra
Prueba con un documento de muestra.
Se te redirigirá a la consola de etiquetado.
Etiquetar un documento
El proceso de seleccionar texto en un documento y aplicar etiquetas se conoce como anotación o etiquetado.
Crear una versión de procesador con un modelo fundacional
Después de etiquetar un documento, puedes crear una versión de procesador con el modelo base preentrenado para extraer entidades.
Usar la IA generativa para etiquetar documentos automáticamente
El modelo base puede extraer campos de forma precisa para varios tipos de documentos, pero también puedes proporcionar datos de entrenamiento adicionales para mejorar la precisión del modelo en estructuras de documentos específicas.
El extractor personalizado usa los nombres de las etiquetas que definas y las anotaciones anteriores para que sea más rápido y fácil etiquetar documentos a gran escala con el etiquetado automático.
Importar documentos de entrenamiento preetiquetados
Opcional: Ver y gestionar el conjunto de datos
Entrenar un procesador basado en un modelo personalizado
La preparación puede tardar varias horas. Asegúrate de haber configurado el procesador con los datos y las etiquetas adecuados antes de empezar el entrenamiento.
Desplegar la versión del procesador
Evaluar y probar el procesador
Usar el procesador
Ha creado y entrenado correctamente un procesador extractor personalizado.
Puedes gestionar tus versiones de procesador entrenadas de forma personalizada igual que cualquier otra versión de procesador. Para obtener más información, consulta Gestionar versiones del procesador.
Para usar la API de Document AI, sigue estos pasos:
Limpieza
Para evitar que se apliquen cargos en tu cuenta de Google Cloud por los recursos utilizados en esta página, sigue estos pasos.
Para evitar cargos innecesarios de Google Cloud , usa la Google Cloud console para eliminar tu procesador y tu proyecto si no los necesitas.
Si has creado un proyecto para aprender a usar Document AI y ya no lo necesitas, elimínalo.
Si has usado un proyecto, elimina los recursos que hayas creado para evitar que se apliquen cargos en tu cuenta: Google Cloud
Siguientes pasos
Para obtener más información, consulta las guías.