Détection des champs dérivés et des signatures
La fonctionnalité de champs dérivés en version Preview publique permet aux clients Document AI de configurer un champ à remplir par inférence ou génération intelligente en fonction du contexte du document, plutôt que par extraction directe de texte.
Cette version ajoute également une autre fonctionnalité permettant de détecter la présence de signatures dans les documents. Vous pouvez utiliser le nouveau type d'entité signature pour spécifier un schéma pour ces entités. Les entités de signature sont dérivées à l'aide d'indices visuels du document.
Champs dérivés dans l'extracteur personnalisé
L'extracteur personnalisé est compatible avec les champs dérivés dans les modèles suivants :
pretrained-foundation-model-v1.4-2025-02-05en disponibilité générale (DG)pretrained-foundation-model-v1.5-2025-05-05en tant qu'aperçupretrained-foundation-model-v1.5-pro-2025-06-20en tant qu'aperçu
Vous pouvez activer ces fonctionnalités dans l'interface utilisateur de la console lorsque vous créez ou modifiez des libellés dans le schéma de votre document.
Les champs dérivés sont une fonctionnalité puissante qui vous permet d'extraire des informations qui ne sont pas explicitement écrites dans un document. Cela vous permet de configurer un champ à remplir par inférence ou génération intelligente en fonction du contexte général du document. Cela va au-delà de l'extraction de texte rudimentaire et prend en charge les cas d'utilisation avancés, tels que :
- Déduire le pays à partir d'une adresse
- Compter le nombre total d'éléments dans un tableau.
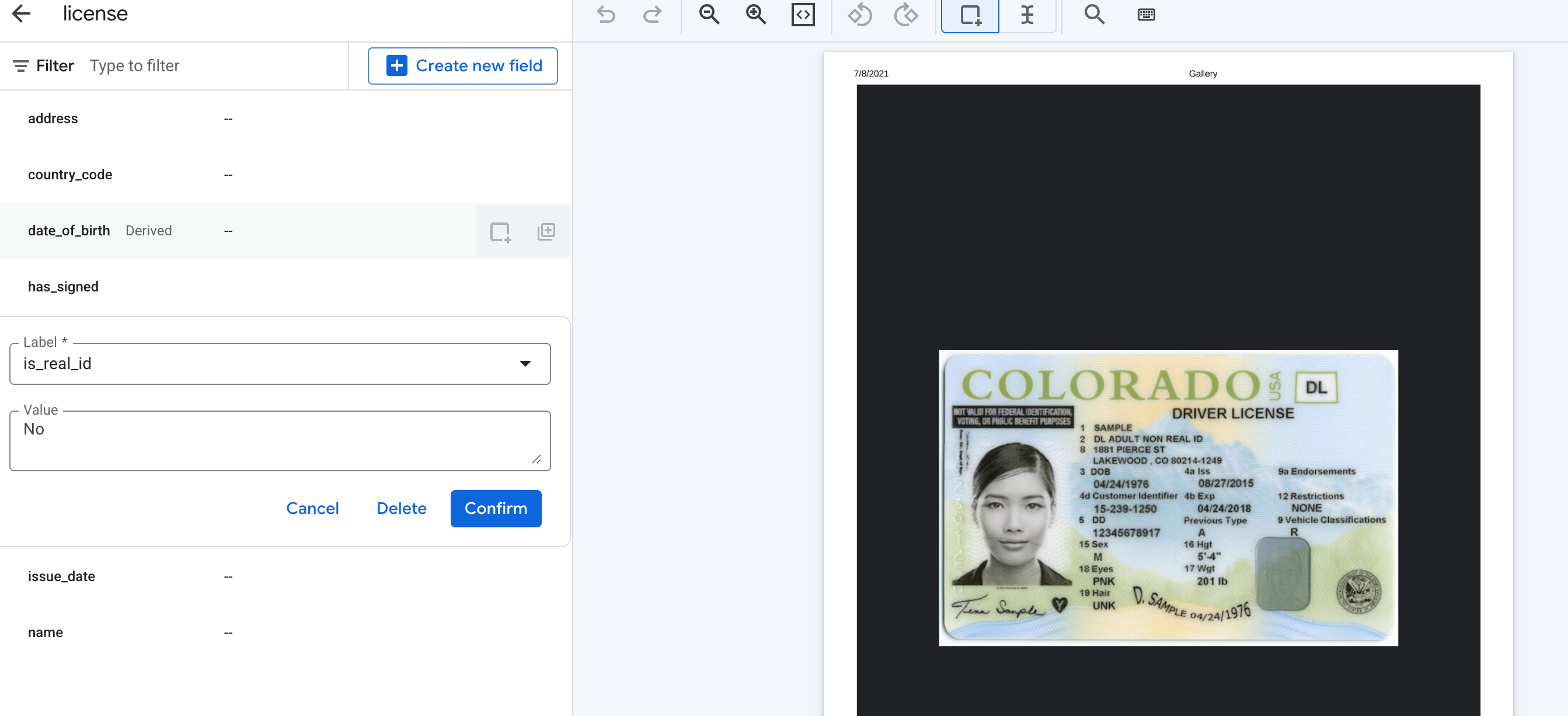
- Détecter si une carte d'identité est une "Real ID".
Exemple de création de schéma
Voici un exemple de création d'un schéma pour les champs dérivés pour de tels cas d'utilisation et le résultat attendu, à l'aide d'un permis de conduire américain.
Sélectionnez la méthode
Derivedlorsque vous créez un élément de schéma.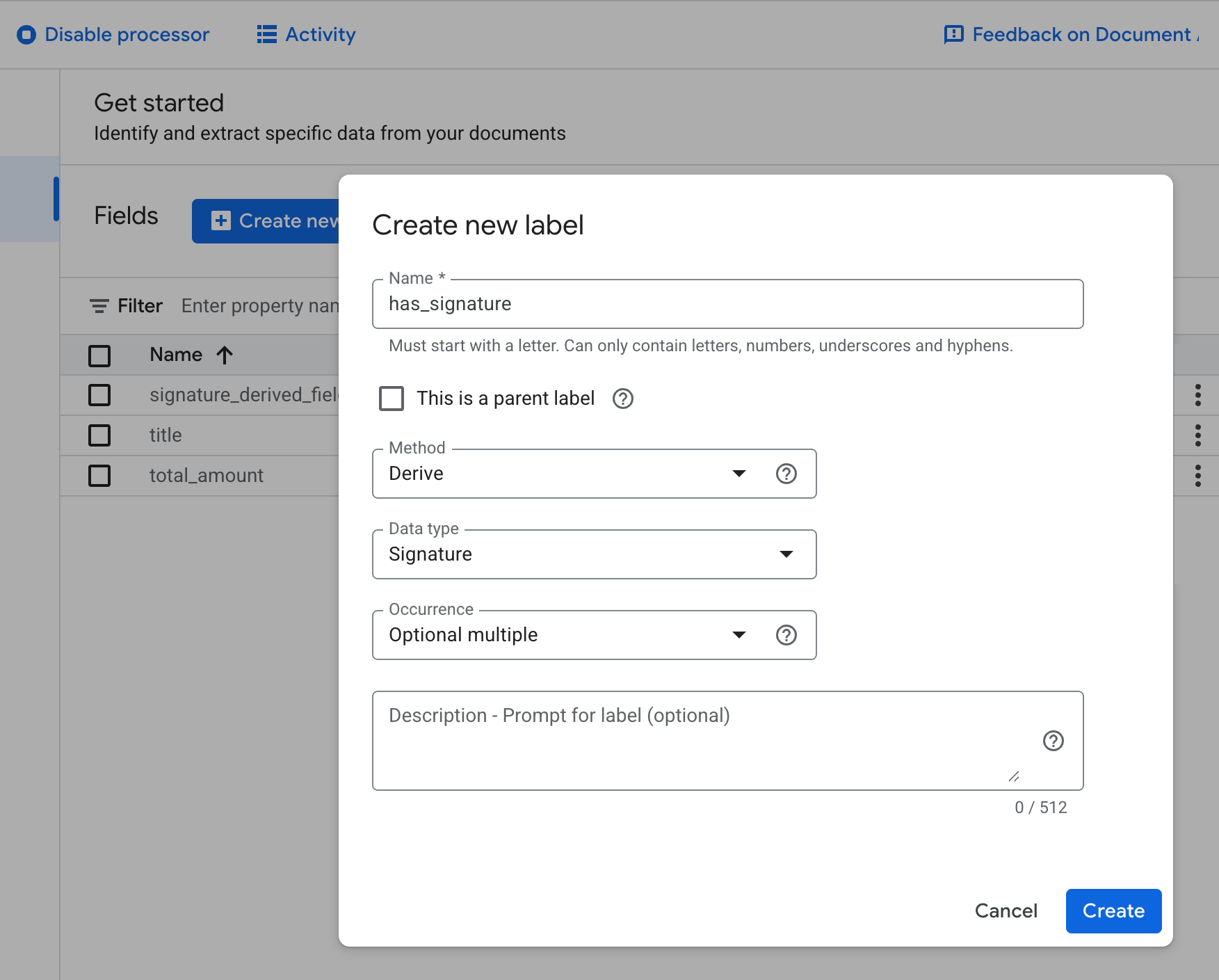
Ajoutez des libellés descriptifs pour améliorer vos performances.
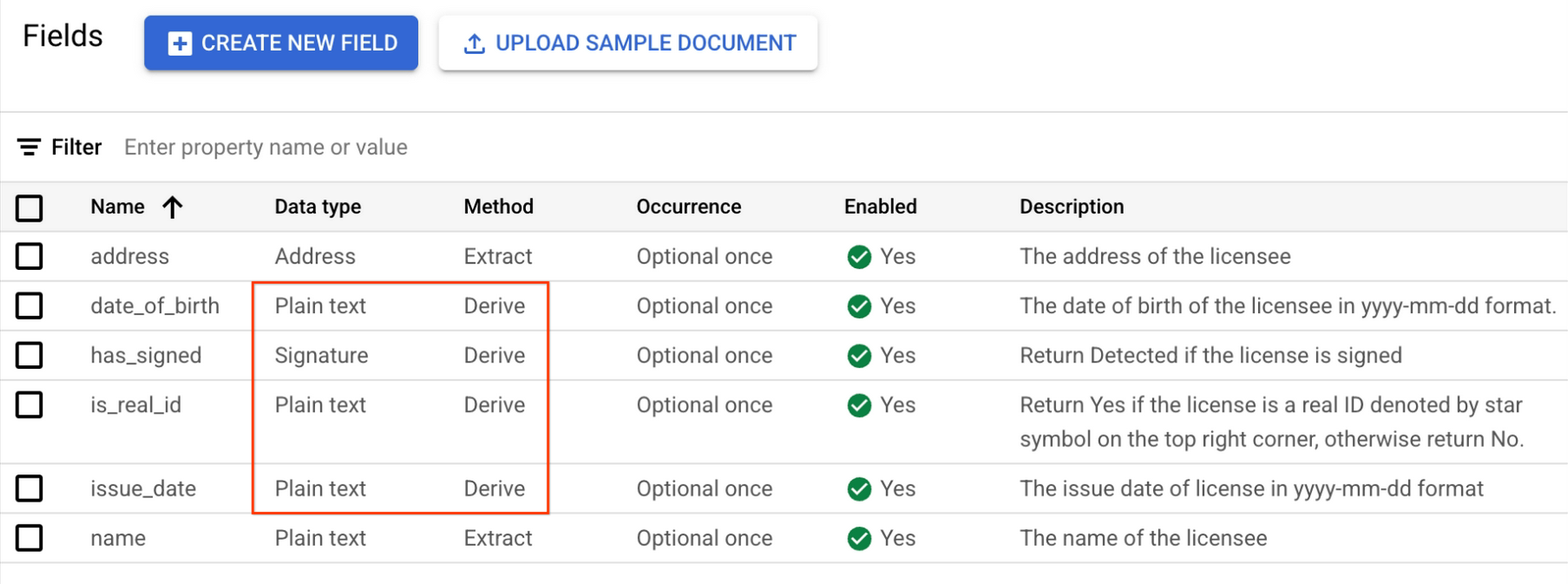
Les champs dérivés tels que les signatures ne nécessitent pas de définir des cadres de sélection lors de l'étiquetage des documents. Pour Valeur, sélectionnez Détecté.
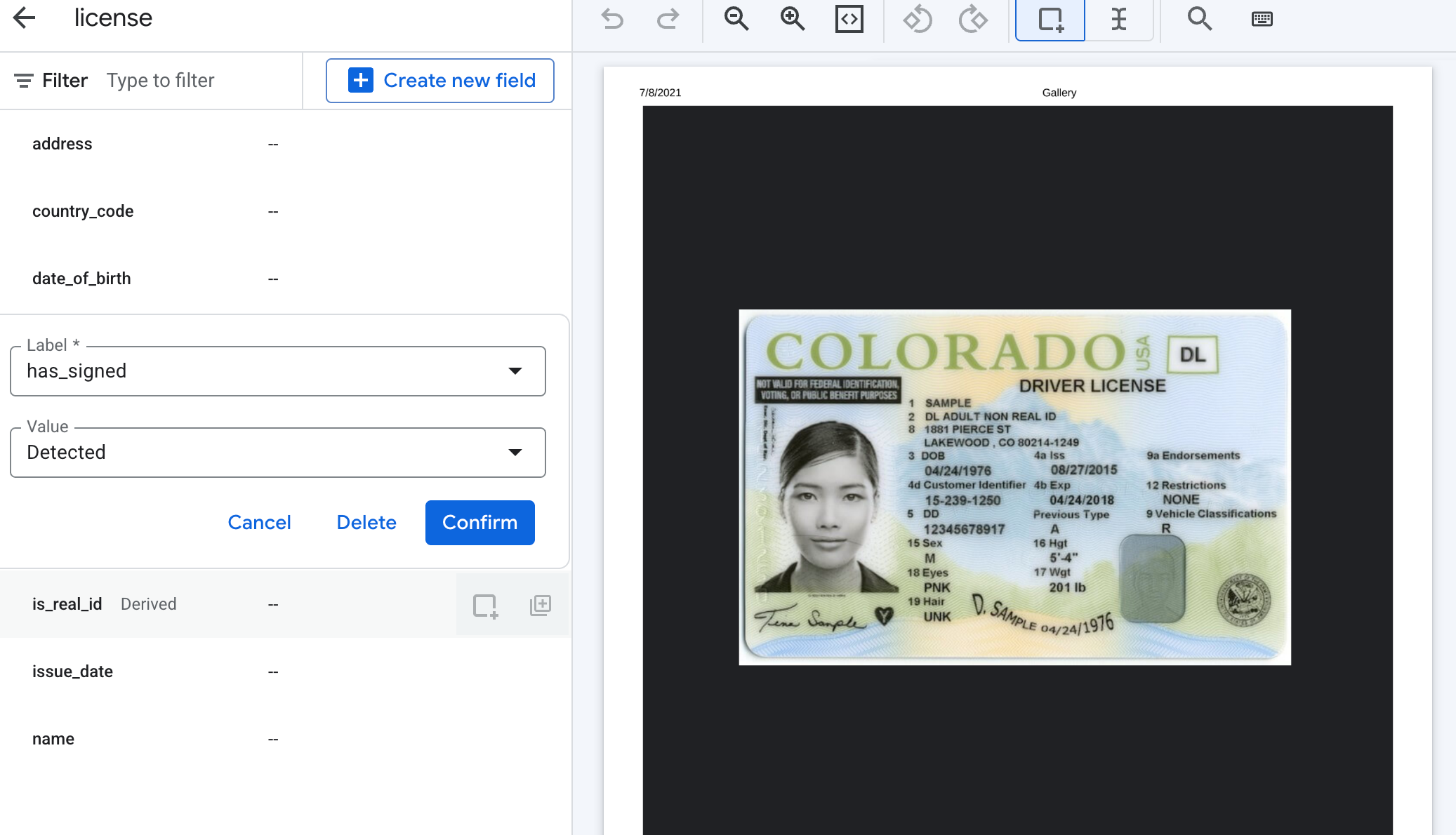
Pour les champs dérivés autres que les signatures, vous pouvez saisir n'importe quelle valeur dans le libellé afin de définir les sorties possibles.
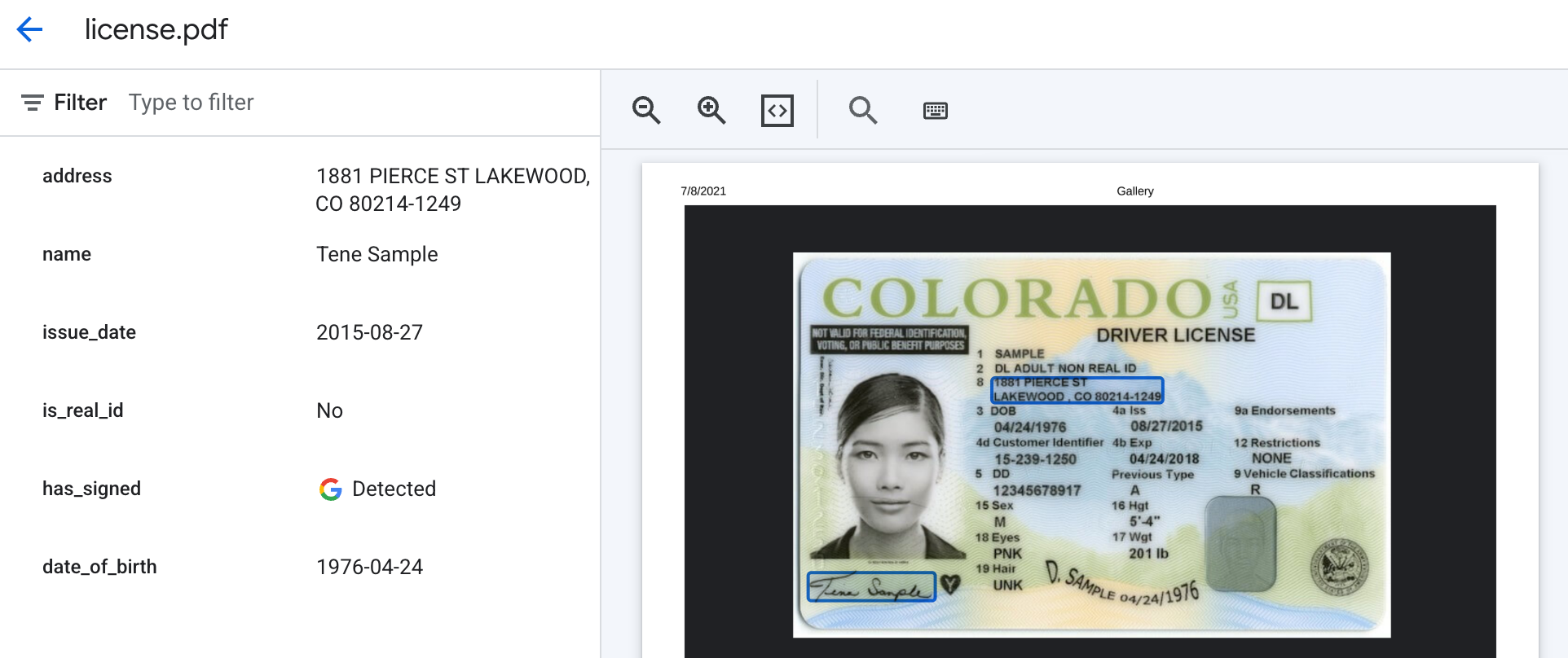
Le résultat attendu devrait ressembler à ceci, avec la présence d'une signature renvoyée sous la forme"Détectée " ou "", et les champs dérivés renvoyés sous forme de texte, comme le demande la description du libellé.
Présentation de l'extraction et de la dérivation
Lorsque vous définissez une entité dans le schéma de votre processeur, vous pouvez choisir une méthode pour renseigner sa valeur.
Extraire : il s'agit de la méthode par défaut. Il fonctionne lorsque la valeur de l'entité doit être extraite directement du texte du document. Le système identifie le texte et renseigne des champs tels que
textAnchoretpageAnchorpour indiquer son emplacement.Dérivée : cette méthode est utilisée lorsque la valeur de l'entité doit être déduite du contenu du document. Comme la valeur n'est pas directement présente dans le texte, les champs
textAnchoretpageAnchorne sont pas renseignés.
Exemple de cas d'utilisation : trouver un code de devise
Imaginez que vous devez identifier le code de devise (par exemple, USD, CAD, EUR) pour les transactions figurant dans vos documents.
Quand utiliser
Extract: si les documents contiennent systématiquement des codes ou symboles monétaires non ambigus, comme "USD" ou "€", utilisez la méthodeExtractpour trouver et extraire ce texte exact.Quand utiliser
Derived: si un document utilise un symbole ambigu comme "$" (qui peut faire référence à l'USD, au CAD, à l'AUD, etc.) ou n'en comporte aucun, utilisez la méthodeDerived. Le modèle analyse le contexte du document (par exemple, une adresse de facturation ou l'emplacement d'une entreprise) pour déduire le code de devise ISO 4217 correct.
Bonnes pratiques de configuration
Pour obtenir les meilleurs résultats avec les champs dérivés, nous vous recommandons vivement d'écrire une description claire et instructive pour la propriété dans votre schéma lors de l'étiquetage. Cela permet de guider le modèle dans sa tâche de dérivation.
Dans l'exemple de code de devise, vous pouvez créer un champ nommé currency_code et fournir la description suivante : "Trouvez le code de devise ISO 4217 des valeurs de montant dans le document, en utilisant les signaux contextuels présents dans le document, comme les symboles de devise et les adresses."
Limites
Les champs dérivés sont générés pour chaque page. Cela signifie que les cas d'utilisation nécessitant des informations provenant de plusieurs pages ne sont pas entièrement pris en charge. Par exemple, si vous configurez un champ dérivé pour résumer un document, il génère un résumé distinct pour chaque page au lieu d'un résumé cohérent pour l'ensemble du document. Cette limitation s'applique à tous les champs dont la valeur doit être dérivée à l'aide d'informations multipages.
Détection de signatures dans un extracteur personnalisé
L'extracteur personnalisé de Document AI est compatible avec la détection de signatures dans les modèles d'extracteur personnalisé pretrained-foundation-model-v1.4-2025-02-05 et pretrained-foundation-model-v1.5-2025-05-05. Vous pouvez activer cette fonctionnalité dans l'interface utilisateur de la console lorsque vous créez ou modifiez des libellés dans le schéma de votre document.
La détection de signature est une fonctionnalité qui vous permet de déterminer si une signature est présente dans vos documents. Cette fonctionnalité vérifie l'existence d'une signature en analysant les indices visuels, plutôt qu'en extrayant le texte.
Fonctionnement de la détection de signature
Pour activer cette fonctionnalité, un type de données signature est disponible lorsque vous définissez le schéma de votre processeur. Le comportement du processeur dépend de la présence ou non d'une signature dans le document.
Si une signature est trouvée, l'extracteur renvoie une entité de signature dans sa réponse.
Pour un champ nommé has_signed, l'objet de réponse présente la structure suivante :
"has_signed": {
"mention_text": "Detected",
"confidence": <confidence_score_between 0 to 1>,
"normalized_value": {
"text": "Detected",
"signature_value": true
}
}
Si aucune signature n'est trouvée, l'entité n'est pas renvoyée dans la réponse du processeur.
Configurer et définir les exigences clés
Pour configurer la détection de signatures :
- Définissez le schéma : dans le schéma de votre processeur, ajoutez une entité pour la signature que vous souhaitez détecter.
- Définissez le type de données : sélectionnez "Signature" comme type de données pour cette nouvelle entité.
- Définissez la méthode sur "derived" : les entités avec le type de données
signaturene peuvent utiliser que la méthodeDerived. Comme le modèle déduit la présence de la signature visuellement, il n'extrait pas de valeur textuelle. Par conséquent, les champs tels quetextAnchoretpageAnchorne sont pas renseignés pour les entités de signature.
Exemple d'utilisation
Imaginez que vous traitiez des contrats et que vous deviez vérifier qu'ils ont été signés.
Vous pouvez créer un champ de schéma nommé is_contract_signed et définir son type de données sur signature. Lorsque vous traitez un contrat signé, la réponse inclut une entité is_contract_signed, confirmant la présence de la signature. Si aucune signature n'est présente, cette entité est absente de la réponse. Cela vous permet de signaler rapidement les documents non signés pour examen.
Étapes suivantes
Découvrez comment surentraîner un outil de traitement spécialisé.