BigQuery는 Document AI와 통합되어 문서 분석 및 생성형 AI 사용 사례를 구축하는 데 도움이 됩니다. 디지털 혁신이 가속화되면서 조직에서 방대한 양의 텍스트와 기타 문서 데이터가 생성되고 있습니다. 이러한 데이터에는 유용한 정보를 얻고 새로운 생성형 AI 사용 사례를 지원할 수 있는 엄청난 잠재력이 있습니다. 이 같은 데이터를 활용하는 데 도움이 될 BigQuery와 Document AI의 통합 소식을 전하게 되어 기쁩니다. 이번 통합으로 문서 데이터에서 유용한 정보를 추출하고 새로운 대규모 언어 모델 (LLM) 애플리케이션을 빌드할 수 있게 되었습니다.
개요
이제 BigQuery 고객은 Google의 첨단 기반 모델이 지원하는 Document AI 커스텀 추출기를 만들고 자체 문서 및 메타데이터를 토대로 이를 맞춤설정할 수 있습니다. 그런 다음 맞춤설정된 모델을 BigQuery에서 호출하여 SQL의 단순성과 성능을 활용해 문서에서 정형 데이터를 안전하고 제어 가능한 방식으로 추출할 수 있습니다. 통합 이전에는 고객들이 추출 로직과 스키마를 수동으로 선별하는 독립적인 Document AI 파이프라인을 구축하기 위해 애썼습니다. 기본 통합 기능이 없었기 때문에 동기화와 데이터 일관성 유지를 위해 맞춤형 인프라를 개발해야 했습니다. 이로 인해 각각의 문서 분석 프로젝트가 상당한 투자를 요하는 대규모 프로젝트로 변질되었습니다. 이제 이 통합으로 고객이 BigQuery에서 Document AI 커스텀 추출기를 위한 원격 모델을 만들고 사용하여 문서 분석 및 생성형 AI 작업을 대규모로 수행할 수 있게 되었습니다. 데이터 기반 통계와 혁신의 새로운 시대가 열린 것입니다.
제어 가능한 통합된 데이터에 기반한 AI 경험
Document AI에서 다음 3가지 단계를 거쳐 커스텀 추출기를 빌드할 수 있습니다.
- 문서에서 추출해야 할 데이터를 정의합니다. 이를
document schema라고 부릅니다.document schema는 커스텀 추출기의 각 버전에 저장되고 BigQuery에서 액세스할 수 있습니다. - 원하는 경우 주석이 포함된 추가 문서를 추출 샘플로 제공합니다.
- Document AI에서 제공하는 기반 모델을 토대로 커스텀 추출기에 대해 모델을 학습시킵니다.
Document AI는 수동 학습이 필요한 커스텀 추출기 외에도 프로세서 갤러리에서 비용, 영수증, 인보이스, 세금 양식, 정부 발급 신분증 등 다양한 시나리오에 맞게 즉시 사용 가능한 추출기를 제공합니다.
그런 다음 커스텀 추출기가 준비되면 BigQuery Studio로 이동하여 다음 4가지 단계로 SQL을 사용해 문서를 분석하면 됩니다.
- SQL을 사용해 추출기에 BigQuery 원격 모델을 등록합니다. 이 모델은 (위에서 만든) 문서 스키마를 이해하고, 커스텀 추출기를 호출하며, 결과를 파싱할 수 있습니다.
- SQL을 사용해 Cloud Storage에 저장된 문서의 객체 테이블을 만듭니다. 개인 정보 보호 및 보안을 위해 특정 문서에 대한 사용자의 액세스를 제한하여 AI 성능을 제한하는 행 수준 액세스 정책을 설정하면 테이블에서 비정형 데이터를 제어할 수 있습니다.
- 객체 테이블에서
ML.PROCESS_DOCUMENT함수를 사용하여 API 엔드포인트를 추론 호출하여 관련 필드를 추출합니다. 함수 밖에서WHERE절을 사용해 추출할 문서를 필터링할 수도 있습니다. 이 함수는 각 열이 추출된 필드인 구조화된 테이블을 반환합니다. - 추출된 데이터를 다른 BigQuery 테이블과 조인하여 구조화된 데이터와 구조화되지 않은 데이터를 결합해 비즈니스 가치를 창출합니다.
다음은 사용자 경험을 보여주는 예시입니다.
# Create an object table in BigQuery that maps to the document files stored in Cloud Storage.
CREATE OR REPLACE EXTERNAL TABLE `my_dataset.document`
WITH CONNECTION `my_project.us.example_connection`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://my_bucket/path/*'],
metadata_cache_mode= 'AUTOMATIC',
max_staleness= INTERVAL 1 HOUR
);
# Create a remote model to register your Doc AI processor in BigQuery.
CREATE OR REPLACE MODEL `my_dataset.layout_parser`
REMOTE WITH CONNECTION `my_project.us.example_connection`
OPTIONS (
remote_service_type = 'CLOUD_AI_DOCUMENT_V1',
document_processor='PROCESSOR_ID'
);
# Invoke the registered model over the object table to parse PDF document
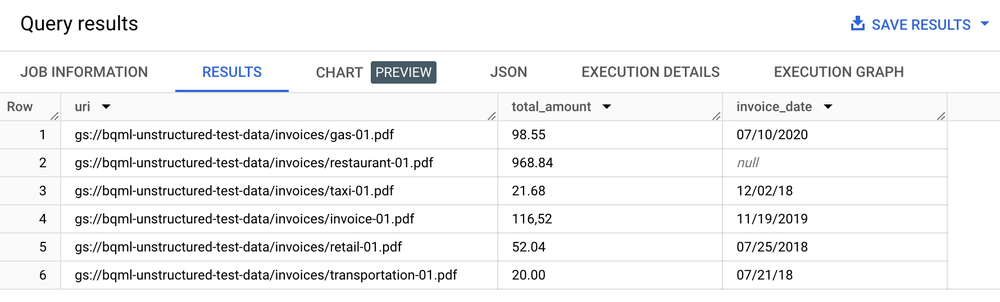
SELECT uri, total_amount, invoice_date
FROM ML.PROCESS_DOCUMENT(
MODEL `my_dataset.layout_parser`,
TABLE `my_dataset.document`,
PROCESS_OPTIONS => (
JSON '{"layout_config": {"chunking_config": {"chunk_size": 250}}}')
)
WHERE content_type = 'application/pdf';
결과 표
텍스트 분석, 요약, 기타 문서 분석 사용 사례
문서에서 텍스트를 추출한 후 몇 가지 방법으로 문서 분석을 수행할 수 있습니다.
- BigQuery ML을 사용한 텍스트 분석 수행: BigQuery ML은 다양한 방식으로 삽입 모델의 학습 및 배포를 지원합니다. 예를 들어 BigQuery ML을 사용하여 지원 통화에서 고객의 감정을 식별하거나 제품에 대한 의견을 다양한 카테고리로 분류할 수 있습니다. Python 사용자라면 데이터의 텍스트 분석을 위해 BigQuery DataFrames로 Pandas, scikit-learn 같은 API를 사용할 수도 있습니다.
text-embedding-004LLM을 사용하여 청크로 나눈 문서에서 임베딩 생성: BigQuery에는text-embedding-004모델을 호출하여 임베딩을 생성하는ML.GENERATE_EMBEDDING함수가 있습니다. 예를 들어 BigQuery SQL로 Document AI를 사용해 고객 의견을 추출하고 PaLM 2를 사용해 의견을 요약할 수 있습니다.- 문서 메타데이터를 BigQuery 테이블에 저장된 다른 구조화된 데이터와 조인합니다.
예를 들어 청크로 나눈 문서를 사용하여 임베딩을 생성하고 벡터 검색에 사용할 수 있습니다.
# Example 1: Parse the chunked data
CREATE OR REPLACE TABLE docai_demo.demo_result_parsed AS (SELECT
uri,
JSON_EXTRACT_SCALAR(json , '$.chunkId') AS id,
JSON_EXTRACT_SCALAR(json , '$.content') AS content,
JSON_EXTRACT_SCALAR(json , '$.pageFooters[0].text') AS page_footers_text,
JSON_EXTRACT_SCALAR(json , '$.pageSpan.pageStart') AS page_span_start,
JSON_EXTRACT_SCALAR(json , '$.pageSpan.pageEnd') AS page_span_end
FROM docai_demo.demo_result, UNNEST(JSON_EXTRACT_ARRAY(ml_process_document_result.chunkedDocument.chunks, '$')) json)
# Example 2: Generate embedding
CREATE OR REPLACE TABLE `docai_demo.embeddings` AS
SELECT * FROM ML.GENERATE_EMBEDDING(
MODEL `docai_demo.embedding_model`,
TABLE `docai_demo.demo_result_parsed`
);
검색 및 생성형 AI 사용 사례 구현
문서에서 구조화된 텍스트를 추출한 후에는 BigQuery의 검색 및 색인 생성 기능을 토대로 강력한 검색 기능을 활용해 모래사장에서 바늘 찾기에 가까운 쿼리에 최적화된 색인을 빌드할 수 있습니다. 또한 이 통합으로 SQL 및 커스텀 Document AI 모델을 사용하여 개인 정보 보호 필터링, 콘텐츠 안전 확인, 토큰 분할을 위한 텍스트 파일 처리를 실행하는 등 새로운 생성형 LLM 애플리케이션을 활용할 수 있습니다. 추출된 텍스트는 다른 메타데이터와 결합되어 대규모 언어 모델을 미세 조정하는 데 필요한 학습 코퍼스의 선별을 단순화해 줍니다. BigQuery의 임베딩 생성 및 벡터 색인 관리 기능을 기반으로 제어 가능한 기업 데이터에 대한 LLM 사용 사례도 구축되고 있습니다. 이 색인을 Vertex AI와 동기화하면 검색 증강 생성 사용 사례를 구현하여 제어가 더 잘 되고 더 효율적인 AI 경험을 얻을 수 있습니다.
샘플 애플리케이션
Document AI 커넥터를 사용하는 엔드 투 엔드 애플리케이션의 예시는 다음과 같습니다.