BigQuery 与 Document AI 集成,可帮助构建文档分析和生成式 AI 用例。随着数字化转型的加速,组织正在生成大量的文本和其他文档数据,所有这些数据都蕴含着巨大的潜力,可用于获取数据洞见并支持新颖的生成式 AI 应用场景。为了帮助您充分利用这些数据,我们很高兴地宣布 BigQuery 与 Document AI 之间的集成,让您能够从文档数据中提取数据洞见,并构建新的大语言模型 (LLM) 应用。
概览
BigQuery 客户现在可以创建 Document AI 自定义提取器,该提取器由 Google 的先进基础模型提供支持,客户可以根据自己的文档和元数据对其进行自定义。然后,可以使用 SQL 的简单性和强大功能,以安全且受监管的方式从 BigQuery 调用这些自定义模型,以从文档中提取结构化数据。 在此集成之前,部分客户尝试构建独立的 Document AI 流水线,这需要手动整理提取逻辑和架构。由于缺乏内置的集成功能,他们不得不开发定制的基础设施来同步和维护数据一致性。这使得每个文档分析项目都成为一项需要大量投资的重大任务。 现在,借助此集成,客户可以在 BigQuery 中为其 Document AI 自定义提取器创建远程模型,并使用这些模型大规模执行文档分析和生成式 AI,从而开启数据驱动型洞见和创新的新时代。
统一的“数据到 AI”治理体验
您可以在 Document AI 中通过以下三个步骤构建自定义提取器:
- 定义您需要从文档中提取的数据。此数据称为
document schema,与自定义提取器的每个版本一起存储,可从 BigQuery 访问。 - (可选)提供带有注释的额外文档作为提取示例。
- 基于 Document AI 中提供的基础模型,训练自定义提取器的模型。
除了需要手动训练的自定义提取器之外,Document AI 还会在处理器库中提供可直接使用的提取器,用于处理费用、收据、账单、纳税表单、政府身份证件以及众多其他场景。
然后,在准备好自定义提取器后,您可以前往 BigQuery Studio,按照以下四个步骤使用 SQL 分析文档:
- 使用 SQL 为提取器注册 BigQuery 远程模型。模型可以理解文档架构(如上所述),调用自定义提取器并解析结果。
- 使用 SQL 为存储在 Cloud Storage 中的文档创建对象表。您可以通过设置行级访问权限政策来控制表中的非结构化数据,从而限制用户对特定文档的访问权限,进而限制 AI 功能,以保护隐私和安全。
- 使用对象表中的函数
ML.PROCESS_DOCUMENT通过向 API 端点发出推理调用来提取相关字段。您还可以在函数外部使用WHERE子句过滤掉用于提取的文档。该函数会返回一个结构化表,其中每列都是一个提取的字段。 - 将提取的数据与其他 BigQuery 表联接,以合并结构化数据和非结构化数据,从而产生业务价值。
以下示例展示了用户体验:
# Create an object table in BigQuery that maps to the document files stored in Cloud Storage.
CREATE OR REPLACE EXTERNAL TABLE `my_dataset.document`
WITH CONNECTION `my_project.us.example_connection`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://my_bucket/path/*'],
metadata_cache_mode= 'AUTOMATIC',
max_staleness= INTERVAL 1 HOUR
);
# Create a remote model to register your Doc AI processor in BigQuery.
CREATE OR REPLACE MODEL `my_dataset.layout_parser`
REMOTE WITH CONNECTION `my_project.us.example_connection`
OPTIONS (
remote_service_type = 'CLOUD_AI_DOCUMENT_V1',
document_processor='PROCESSOR_ID'
);
# Invoke the registered model over the object table to parse PDF document
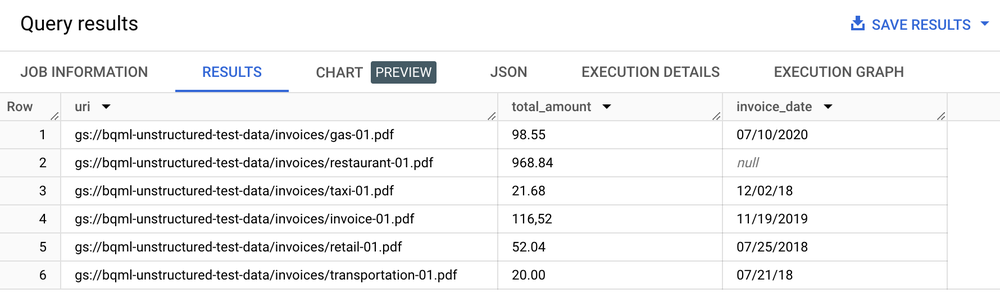
SELECT uri, total_amount, invoice_date
FROM ML.PROCESS_DOCUMENT(
MODEL `my_dataset.layout_parser`,
TABLE `my_dataset.document`,
PROCESS_OPTIONS => (
JSON '{"layout_config": {"chunking_config": {"chunk_size": 250}}}')
)
WHERE content_type = 'application/pdf';
结果表
文本分析、总结和其他文档分析用例
从文档中提取文本后,您可以通过以下几种方式执行文档分析:
- 使用 BigQuery ML 执行文本分析:BigQuery ML 支持以多种方式训练和部署嵌入模型。例如,您可以使用 BigQuery ML 来识别支持电话中的客户情绪,或将产品反馈分类为不同的类别。如果您是 Python 用户,还可以使用 BigQuery DataFrames for pandas 和类似 scikit-learn 的 API 对数据进行文本分析。
- 使用
text-embedding-004LLM 根据分块的文档生成嵌入:BigQuery 具有一个ML.GENERATE_EMBEDDING函数,该函数可调用text-embedding-004模型来生成嵌入。例如,您可以使用 Document AI 提取客户反馈,并使用 PaLM 2 总结反馈,所有操作均可通过 BigQuery SQL 完成。 - 将文档元数据与存储在 BigQuery 表中的其他结构化数据联接:
例如,您可以利用分块文档生成嵌入,并将其用于向量搜索。
# Example 1: Parse the chunked data
CREATE OR REPLACE TABLE docai_demo.demo_result_parsed AS (SELECT
uri,
JSON_EXTRACT_SCALAR(json , '$.chunkId') AS id,
JSON_EXTRACT_SCALAR(json , '$.content') AS content,
JSON_EXTRACT_SCALAR(json , '$.pageFooters[0].text') AS page_footers_text,
JSON_EXTRACT_SCALAR(json , '$.pageSpan.pageStart') AS page_span_start,
JSON_EXTRACT_SCALAR(json , '$.pageSpan.pageEnd') AS page_span_end
FROM docai_demo.demo_result, UNNEST(JSON_EXTRACT_ARRAY(ml_process_document_result.chunkedDocument.chunks, '$')) json)
# Example 2: Generate embedding
CREATE OR REPLACE TABLE `docai_demo.embeddings` AS
SELECT * FROM ML.GENERATE_EMBEDDING(
MODEL `docai_demo.embedding_model`,
TABLE `docai_demo.demo_result_parsed`
);
实现搜索和生成式 AI 用例
从文档中提取结构化文本后,您可以构建针对“大海捞针”查询优化的索引,这得益于 BigQuery 的搜索和索引功能,从而解锁强大的搜索功能。 此集成还有助于解锁新的生成式 LLM 应用,例如使用 SQL 和自定义 Document AI 模型执行文本文件处理,以进行隐私过滤、内容安全检查和令牌分块。提取的文本与其他元数据相结合,可简化微调大型语言模型所需的训练语料库的整理工作。此外,您还可以基于受监管的企业数据构建 LLM 应用场景,这些数据已通过 BigQuery 的嵌入向量生成和向量索引管理功能进行了依据化处理。通过将此索引与 Vertex AI 同步,您可以实现检索增强生成用例,从而获得更受监管且更顺畅的 AI 体验。
示例应用
如需查看使用 Document AI 连接器的端到端应用的示例,请参阅以下资源: