Muitas organizações implantam data warehouses na nuvem para armazenar informações confidenciais. Assim, elas podem analisar os dados para vários fins comerciais. Neste documento, descrevemos como é possível implementar o framework de controles de chave dos Recursos de gerenciamento de dados do Cloud (CDMC, na sigla em inglês), gerenciado pelo Enterprise Data Management Council, em um data warehouse do BigQuery.
O Framework de controles de chave do CDMC foi publicado principalmente para provedores de serviços de nuvem e de tecnologia. O framework descreve 14 controles principais que os provedores podem implementar para permitir que os clientes gerenciem e controlem dados confidenciais na nuvem com eficiência. Os controles foram escritos pelo CDMC Working Group, com mais de 300 profissionais participando de mais de 100 empresas. Ao escrever o framework, o CDMC Working Group considerou muitos dos requisitos legais e regulatórios.
Essa arquitetura de referência do BigQuery e do Data Catalog foi avaliada e certificada em relação ao framework de controles de chave do CDMC como uma solução de nuvem certificada do CDMC. A arquitetura de referência usa vários serviços e recursos do Google Cloud , bem como bibliotecas públicas, para implementar os controles de chave CDMC e a automação recomendada. Neste documento, explicamos como é possível implementar os principais controles para ajudar a proteger dados confidenciais em um data warehouse do BigQuery.
Arquitetura
A arquitetura de referência Google Cloud a seguir está alinhada às especificações de teste do framework de controles de chaves vMC v1.1.1. Os números no diagrama representam os principais controles abordados com os serviços do Google Cloud .

A arquitetura de referência é baseada no esquema de data warehouse seguro, que fornece uma arquitetura que ajuda a proteger um data warehouse do BigQuery que inclui informações confidenciais. No diagrama anterior, os projetos na parte superior do diagrama (em cinza) fazem parte do blueprint do data warehouse seguro, e o projeto de governança de dados (em azul) inclui os serviços adicionados para atender aos requisitos do framework dos controles de chave do CDMC. Para implementar o framework do CDMC Key Controls, a arquitetura estende o projeto de governança de dados. O projeto de governança de dados fornece controles como classificação, gerenciamento do ciclo de vida e gerenciamento da qualidade de dados. O projeto também fornece uma maneira de auditar a arquitetura e gerar relatórios sobre as descobertas.
Para mais informações sobre como implementar essa arquitetura de referência, consulte a Arquitetura de referência doGoogle Cloud CDMC no GitHub.
Visão geral da estrutura de controles de chave do CDMC
A tabela a seguir resume o framework de controles de chave do CDMC (em inglês).
| # | Controle de chave CDMC | Requisito de controle do CDMC |
|---|---|---|
| 1 | Compliance do controle de dados | Os casos de negócios de gerenciamento de dados na nuvem são definidos e regidos. Todos os recursos de dados que contêm dados confidenciais precisam ser monitorados para conformidade com os controles de chave do CDMC, usando métricas e notificações automatizadas. |
| 2 | A propriedade dos dados é estabelecida para dados migrados e gerados na nuvem | O campo Propriedade em um catálogo de dados precisa ser preenchido para todos os dados confidenciais ou informado a um fluxo de trabalho definido. |
| 3 | A automação e o fornecimento de dados são regidos e apoiados pela automação | É preciso preencher um registro de fontes de dados autoritativas e pontos de provisionamento de todos os recursos de dados que contenham dados confidenciais. Caso contrário, eles precisarão ser informados a um fluxo de trabalho definido. |
| 4 | Soberania de dados e movimentação de dados entre países são gerenciadas | A soberania de dados e o movimento internacional de dados confidenciais precisam ser gravados, auditados e controlados de acordo com a política definida. |
| 5 | Os catálogos de dados são implementados, usados e interoperáveis. | O catálogo precisa ser automatizado para todos os dados no ponto de criação ou ingestão, com consistência em todos os ambientes. |
| 6 | As classificações de dados são definidas e usadas | A classificação precisa ser automatizada para todos os dados no momento da criação ou do processamento e estar sempre ativada. A classificação é automatizada para:
|
| 7 | Os direitos de dados são gerenciados, aplicados e rastreados | Esse controle exige o seguinte:
|
| 8 | O acesso, o uso e os resultados éticos dos dados são gerenciados | A finalidade de consumo de dados precisa ser fornecida para todos os contratos de compartilhamento de dados que envolvem dados confidenciais. O propósito precisa especificar o tipo de dados exigido e, para organizações globais, o escopo do país ou da entidade legal. |
| 9 | Os dados são protegidos e os controles são evidenciados. | Esse controle exige o seguinte:
|
| 10 | Uma estrutura de privacidade de dados é definida e operacional | As avaliações de impacto da proteção de dados (DPIAs, na sigla em inglês) precisam ser acionadas automaticamente para todos os dados pessoais de acordo com a jurisdição deles. |
| 11 | O ciclo de vida dos dados é planejado e gerenciado | A retenção, o arquivamento e a limpeza de dados precisam ser gerenciados de acordo com uma programação de retenção definida. |
| 12 | A qualidade dos dados é gerenciada | A medição da qualidade de dados precisa ser ativada para dados confidenciais com métricas distribuídas quando disponíveis. |
| 13 | Os princípios de gerenciamento de custos são estabelecidos e aplicados | Os princípios de design técnico são estabelecidos e aplicados. As métricas de custo diretamente associadas ao uso, ao armazenamento e à movimentação de dados precisam estar disponíveis no catálogo. |
| 14 | A procedência dos dados e a linhagem são compreendidas | As informações de linhagem de dados precisam estar disponíveis para todos os dados confidenciais. Essas informações precisam incluir, pelo menos, a fonte de onde os dados foram ingeridos ou em que foram criados em um ambiente de nuvem. |
1. Compliance do controle de dados
Esse controle exige que você use métricas para verificar se todos os dados confidenciais são monitorados para conformidade com esse framework.
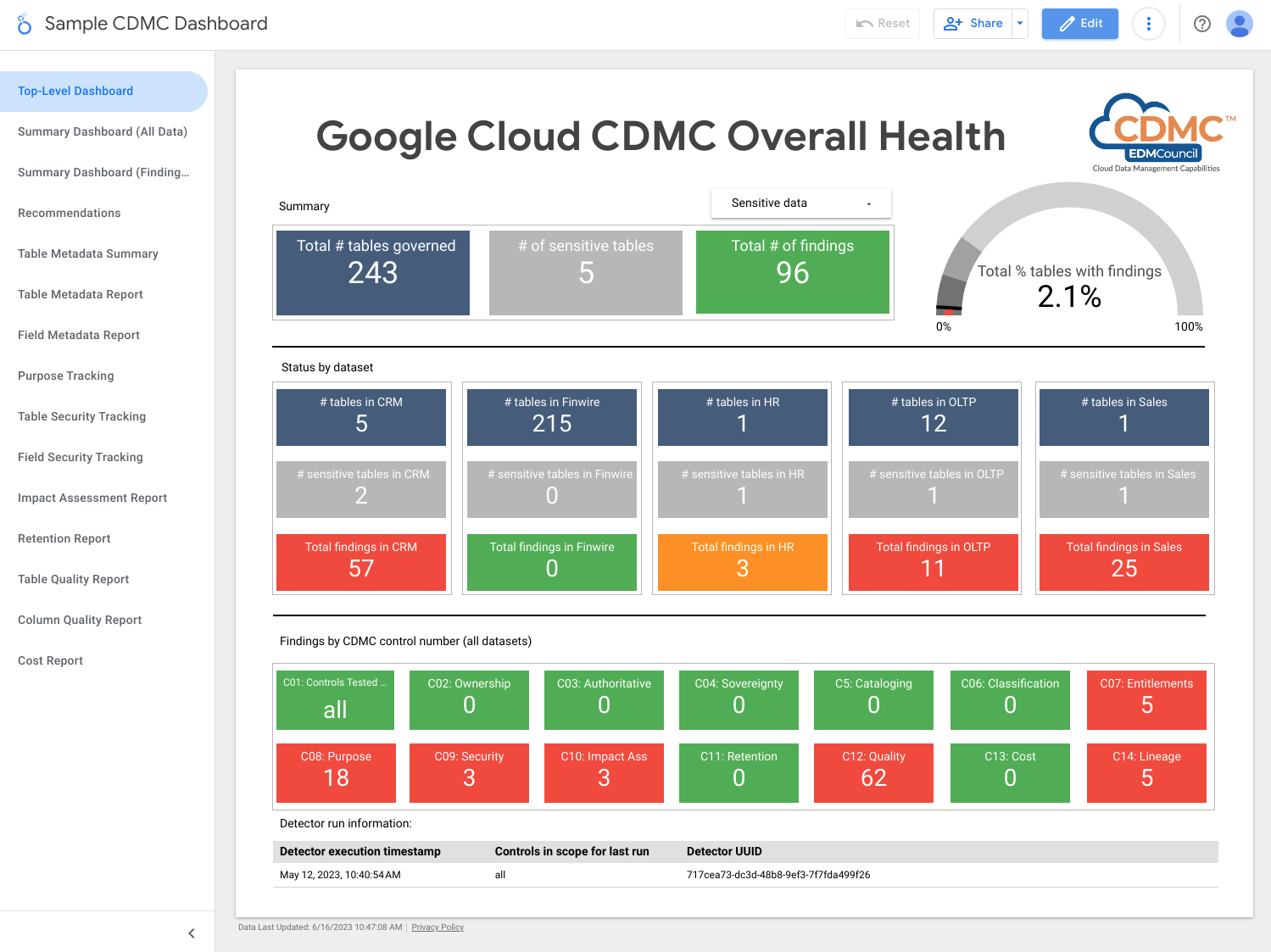
A arquitetura usa métricas que mostram até que ponto cada controle principal está operacional. A arquitetura também inclui painéis que indicam quando as métricas não atendem aos limites definidos.
A arquitetura inclui detectores que publicam descobertas e recomendações de correção quando os recursos de dados não atendem a um controle de chave. Essas descobertas e recomendações estão no formato JSON e são publicadas em um tópico do Pub/Sub para distribuição aos assinantes. Integre o balcão de atendimento interno ou as ferramentas de gerenciamento ao tópico do Pub/Sub para que os incidentes sejam criados automaticamente no sistema de tíquetes.
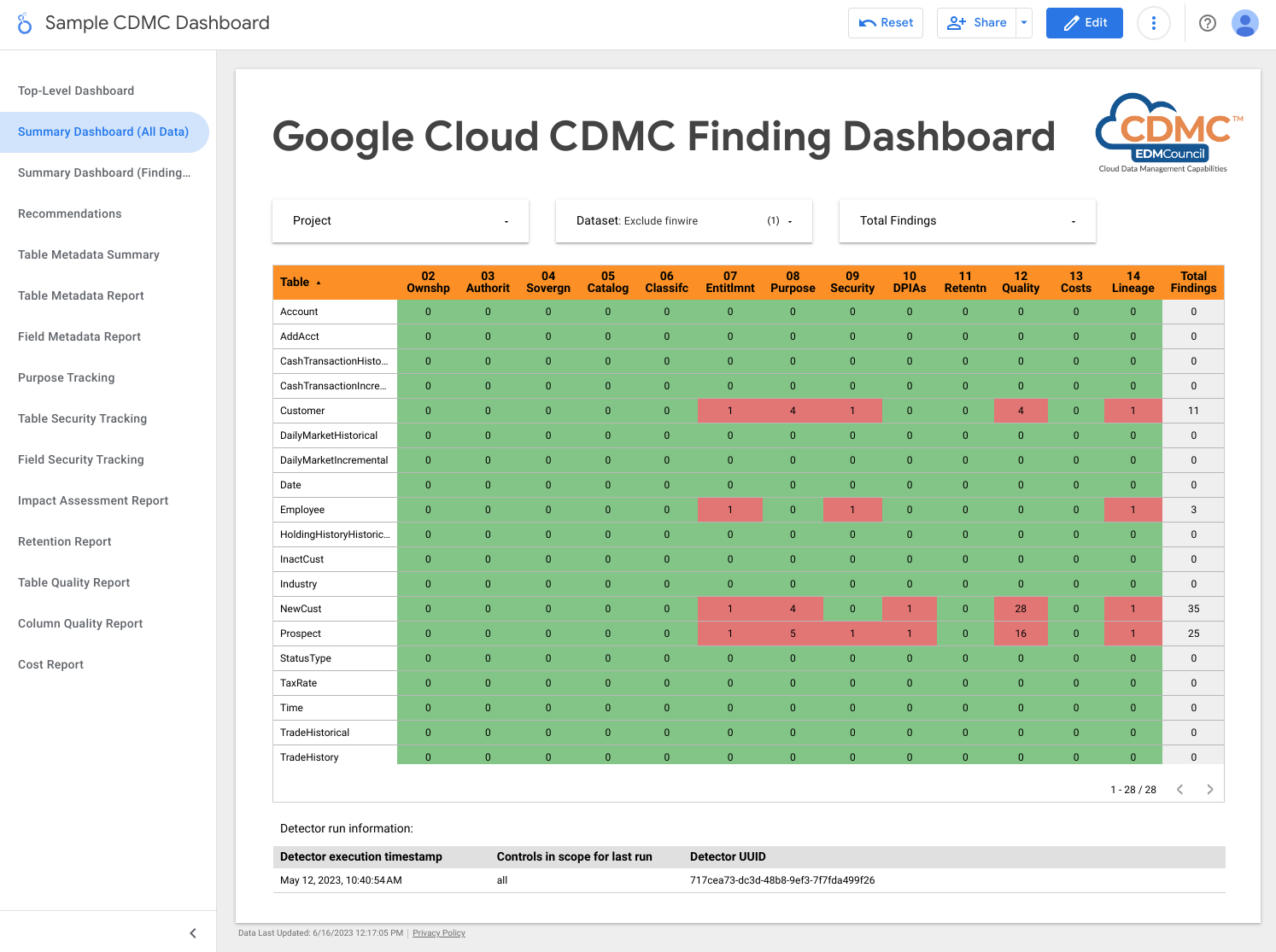
A arquitetura usa o Dataflow para criar um exemplo de assinante dos eventos de descobertas, que são armazenados em uma instância do BigQuery executada no projeto de governança de dados. Usando várias visualizações fornecidas, é possível consultar os dados usando o BigQuery Studio no console do Google Cloud . Também é possível criar relatórios usando o Looker Studio ou outras ferramentas de Business Intelligence compatíveis com o BigQuery. Os relatórios que podem ser visualizados incluem:
- Resumo das descobertas da última execução
- Detalhes das descobertas da última execução
- Metadados da última execução
- Últimos recursos de dados executados no escopo
- Estatísticas do conjunto de dados da última execução
O diagrama a seguir mostra os serviços que se aplicam a esse controle.

Para atender aos requisitos desse controle, a arquitetura usa os seguintes serviços:
- O Pub/Sub publica descobertas.
- O Dataflow carrega as descobertas em uma instância do BigQuery.
- O BigQuery armazena os dados das descobertas e fornece visualizações resumidas.
- O Looker Studio oferece painéis e relatórios.
A captura de tela a seguir mostra um exemplo de painel de resumo do Looker Studio.
A captura de tela a seguir mostra um exemplo de visualização das descobertas por recurso de dados.
2. A propriedade dos dados é estabelecida para dados migrados e gerados na nuvem
Para atender aos requisitos desse controle, a arquitetura analisa automaticamente os dados no data warehouse do BigQuery e adiciona tags de classificação que indicam que os proprietários são identificados para todos os dados confidenciais.
O Data Catalog processa dois tipos de metadados: técnicos e comerciais. Para um determinado projeto, o Data Catalog cataloga automaticamente conjuntos de dados, tabelas e visualizações do BigQuery e preenche os metadados técnicos. A sincronização entre o catálogo e os recursos de dados é mantida quase em tempo real.
A arquitetura usa o Tag Engine para adicionar as seguintes tags de metadados comerciais a um modelo de tag CDMC controls no Data Catalog:
is_sensitive: se o recurso de dados contém dados confidenciais. Consulte o Controle 6 para classificação de dados.owner_name: o proprietário dos dadosowner_email: o endereço de e-mail do proprietário
As tags são preenchidas com padrões armazenados em uma tabela de referência do BigQuery no projeto de governança de dados.
Por padrão, a arquitetura define os metadados de propriedade no nível da tabela, mas é possível alterar a arquitetura para que os metadados sejam definidos no nível da coluna. Para mais informações, consulte Tags e modelos de tags do Data Catalog.
O diagrama a seguir mostra os serviços que se aplicam a esse controle.

Para atender aos requisitos desse controle, a arquitetura usa os seguintes serviços:
- Dois data warehouses do BigQuery: um armazena os dados confidenciais e o outro armazena os padrões de propriedade do recursode dados.
- O Data Catalog armazena metadados de propriedade por meio de modelos de tag e tags.
- Duas instâncias do Cloud Run da seguinte maneira:
- Uma instância executa o Report Engine, que verifica se as tags são aplicadas e publica os resultados.
- Outra instância executa o mecanismo de tags, que marca os dados no data warehouse protegido.
- O Pub/Sub publica descobertas.
Para detectar problemas relacionados a esse controle, a arquitetura verifica se os dados confidenciais são atribuídos a uma tag de nome do proprietário.
3. A automação e o fornecimento de dados são regidos e apoiados pela automação
Esse controle requer a classificação de recursos de dados e um registro de dados de fontes autorizadas e distribuidores autorizados. A arquitetura usa o Data Catalog para adicionar a tag is_authoritative ao modelo de tag CDMC
controls. Essa tag define se o recurso de dados é oficial.
O Data Catalog cataloga conjuntos de dados, tabelas e visualizações do BigQuery com metadados técnicos e comerciais. Os metadados técnicos são
preenchidos automaticamente e incluem o URL do recurso, que é o local do
ponto de provisionamento. Os metadados comerciais são definidos no arquivo de configuração do Tag Engine e incluem a tag is_authoritative.
Durante a próxima execução programada, o Tag Engine preenche a tag is_authoritative no modelo de tag CDMC controls a partir de valores padrão armazenados em uma tabela de referência no BigQuery.
O diagrama a seguir mostra os serviços que se aplicam a esse controle.

Para atender aos requisitos desse controle, a arquitetura usa os seguintes serviços:
- Dois data warehouses do BigQuery: um armazena os dados confidenciais e o outro armazena os padrões da fonte autoritativa do recurso de dados.
- O Data Catalog armazena metadados de origem confiáveis por meio de tags.
- Duas instâncias do Cloud Run da seguinte maneira:
- Uma instância executa o Report Engine, que verifica se as tags são aplicadas e publica os resultados.
- Outra instância executa o mecanismo de tags, que marca os dados no data warehouse protegido.
- O Pub/Sub publica descobertas.
Para detectar problemas relacionados a esse controle, a arquitetura verifica se os dados confidenciais são atribuídos à tag de origem autorizada.
4. Soberania de dados e movimentação de dados entre países são gerenciadas
Esse controle requer que a arquitetura inspecione o registro de dados em busca de requisitos de armazenamento específicos da região e imponha regras de uso. Um relatório descreve a localização geográfica dos recursos de dados.
A arquitetura usa o Data Catalog para adicionar a tag approved_storage_location ao modelo de tag CDMC controls. Essa tag define a localização geográfica em que o recurso de dados pode ser armazenado.
O local real dos dados é armazenado como metadados técnicos nos detalhes da tabela do BigQuery. O BigQuery não permite que os administradores alterem o local de um conjunto de dados ou tabela. Em vez disso, se os administradores quiserem alterar o local dos dados, precisarão copiar o conjunto de dados.
A restrição de Serviço de política da organização dos locais de recursos define as Google Cloud regiões em que é possível armazenar dados. Por padrão,
a arquitetura define a restrição no projeto de dados confidenciais, mas você
pode defini-la no nível da organização ou da pasta, se preferir. O App Engine replica os locais permitidos no modelo de tag do Data Catalog e armazena o local na tag approved_storage_location. Se você ativar o nível Premium do Security Command Center e alguém atualizar a restrição do Serviço de políticas da organização sobre os locais dos recursos, o Security Command Center vai gerar descobertas de vulnerabilidade para recursos armazenados fora da política atualizada.
O Access Context Manager define a localização geográfica em que os usuários precisam estar para que possam acessar os recursos de dados. Usando níveis de acesso, é possível especificar de quais regiões as solicitações podem vir. Em seguida, adicione a política de acesso ao perímetro do VPC Service Controls para o projeto de dados confidenciais.
Para acompanhar a movimentação de dados, o BigQuery mantém uma trilha de auditoria completa para cada job e consulta em cada conjunto de dados. A trilha de auditoria é armazenada na visualização Jobs do esquema de informações do BigQuery.
O diagrama a seguir mostra os serviços que se aplicam a esse controle.

Para atender aos requisitos desse controle, a arquitetura usa os seguintes serviços:
- O serviço de políticas da organização define e aplica a restrição de locais de recursos.
- O Access Context Manager define os locais de onde os usuários podem acessar os dados.
- Dois data warehouses do BigQuery: um armazena os dados confidenciais e o outro hospeda uma função remota que é usada para inspecionar a política de localização.
- O Data Catalog armazena locais de armazenamento aprovados como tags.
- Duas instâncias do Cloud Run da seguinte maneira:
- Uma instância executa o Report Engine, que verifica se as tags são aplicadas e publica os resultados.
- Outra instância executa o mecanismo de tags, que marca os dados no data warehouse protegido.
- O Pub/Sub publica descobertas.
- O Cloud Logging grava os registros de auditoria.
- O Security Command Center gera relatórios sobre todas as descobertas relacionadas à localização de recursos ou ao acesso a dados.
Para detectar problemas relacionados a esse controle, a arquitetura inclui uma descoberta para determinar se a tag de locais aprovados inclui o local dos dados confidenciais.
5. Os catálogos de dados são implementados, usados e interoperáveis.
Esse controle requer a existência de um catálogo de dados e que a arquitetura possa verificar recursos novos e atualizados para adicionar metadados conforme necessário.
Para atender aos requisitos desse controle, a arquitetura usa o Data Catalog. O Data Catalog registra automaticamente os recursos doGoogle Cloud , incluindo conjuntos de dados, tabelas e visualizações do BigQuery. Quando você cria uma nova tabela no BigQuery, o Data Catalog registra automaticamente os metadados técnicos e o esquema da nova tabela. Quando você atualiza uma tabela no BigQuery, o Data Catalog atualiza as entradas quase instantaneamente.
O diagrama a seguir mostra os serviços que se aplicam a esse controle.

Para atender aos requisitos desse controle, a arquitetura usa os seguintes serviços:
- Dois data warehouses do BigQuery: um armazena os dados confidenciais e o outro armazena os dados não confidenciais.
- O Data Catalog armazena os metadados técnicos para tabelas e campos.
Por padrão, nessa arquitetura, o Data Catalog armazena metadados técnicos do BigQuery. Se necessário, você pode integrar o Data Catalog a outras fontes de dados.
6. As classificações de dados são definidas e usadas
Essa avaliação exige que os dados sejam classificados com base na confidencialidade, por exemplo, se são PIIs, se identificam clientes ou se atendem a algum outro padrão definido pela sua organização. Para atender aos requisitos desse controle, a arquitetura cria um relatório de recursos de dados e a confidencialidade deles. Você pode usar esse relatório para verificar se as configurações de sensibilidade estão corretas. Além disso, cada novo recurso de dados ou alteração em um recurso de dados resulta em uma atualização do catálogo de dados.
As classificações são armazenadas na tag sensitive_category no modelo de tag do Data Catalog no nível da tabela e da coluna. Uma
tabela de referência de classificação permite classificar os tipos de informações (infoTypes)
de proteção de dados sensíveis
disponíveis, com classificações mais altas para conteúdos mais sensíveis.
A fim de atender aos requisitos desse controle, a arquitetura usa a proteção de dados confidenciais, o Data Catalog e o Tag Engine para adicionar as seguintes tags às colunas de dados confidenciais nas tabelas do BigQuery:
is_sensitive: se o recurso de dados contém informações confidenciaissensitive_category: a categoria dos dados. Uma destas:- Informações de identificação pessoal confidenciais
- Informações de identificação pessoal
- Informações pessoais confidenciais
- Informações pessoais
- Informações públicas
Você pode alterar as categorias de dados para atender aos seus requisitos. Por exemplo, é possível adicionar a classificação Material não público (MNPI, na sigla em inglês).
Depois que a proteção de dados confidenciais
inspeciona os dados,
o Tag Engine lê as tabelas DLP results por recurso para compilar as descobertas. Se uma tabela contiver colunas com um ou mais infoTypes confidenciais, o infoType mais importante será determinado e as colunas confidenciais e a tabela inteira serão marcadas como a categoria com a classificação mais alta. O Tag Engine também atribui uma tag de política correspondente à coluna e a tag booleana is_sensitive à tabela.
Use o Cloud Scheduler para automatizar a inspeção da Proteção de dados sensíveis.
O diagrama a seguir mostra os serviços que se aplicam a esse controle.

Para atender aos requisitos desse controle, a arquitetura usa os seguintes serviços:
- Quatro data warehouses do BigQuery armazenam as seguintes informações:
- Dados confidenciais
- Informações sobre os resultados da proteção de dados confidenciais
- Dados de referência de classificação de dados
- Informações de exportação da tag
- O Data Catalog armazena as tags de classificação.
- A proteção de dados confidenciais inspeciona os recursos quanto a infoTypes confidenciais.
- O Compute Engine executa o script "Inspecionar conjuntos de dados", que aciona um job de proteção de dados confidenciais para cada conjunto de dados do BigQuery.
- Duas instâncias do Cloud Run da seguinte maneira:
- Uma instância executa o Report Engine, que verifica se as tags são aplicadas e publica os resultados.
- Outra instância executa o mecanismo de tags, que marca os dados no data warehouse protegido.
- O Pub/Sub publica descobertas.
Para detectar problemas relacionados a esse controle, a arquitetura inclui as seguintes descobertas:
- Se os dados confidenciais são atribuídos a uma tag de categoria sensível.
- Se os dados confidenciais são atribuídos a uma tag de tipo de confidencialidade no nível da coluna.
7. Os direitos de dados são gerenciados, aplicados e rastreados
Por padrão, somente criadores e proprietários recebem direitos e acesso a dados confidenciais. Além disso, esse controle exige que a arquitetura acompanhe todo o acesso a dados confidenciais.
Para atender aos requisitos desse controle, a arquitetura usa a taxonomia de tags de política cdmc
sensitive data classification no BigQuery para controlar o acesso a colunas que contêm dados confidenciais nas tabelas do BigQuery. A taxonomia inclui as seguintes tags de política:
- Informações de identificação pessoal confidenciais
- Informações de identificação pessoal
- Informações pessoais confidenciais
- Informações pessoais
As tags de política permitem controlar quem pode visualizar colunas confidenciais nas tabelas do BigQuery. A arquitetura associa essas tags de política para
classificações de confidencialidade derivadas de infoTypes da proteção
de dados confidenciais. Por exemplo, a tag de política sensitive_personal_identifiable_information e a categoria confidencial são associadas às infoTypes, como AGE, DATE_OF_BIRTH, PHONE_NUMBER e EMAIL_ADDRESS.
A arquitetura usa o Identity and Access Management (IAM) para gerenciar grupos, usuários e contas de serviço que exigem acesso aos dados. As permissões do IAM são concedidas a um determinado recurso para acesso no nível da tabela. Além disso, o acesso no nível da coluna com base em tags de política permite o acesso refinado a recursos de dados confidenciais. Por padrão, os usuários não têm acesso a colunas que tenham tags de política definidas.
Para garantir que apenas usuários autenticados possam acessar dados, oGoogle Cloud usa o Cloud Identity, que pode ser federado com seus provedores de identidade atuais para autenticar usuários.
Esse controle também exige que a arquitetura verifique regularmente os recursos de dados que não têm direitos definidos. O detector, gerenciado pelo Cloud Scheduler, verifica os seguintes cenários:
- Um recurso de dados inclui uma categoria sensível, mas não há uma tag de política relacionada.
- Uma categoria não corresponde à tag de política.
Quando esses cenários acontecem, o detector gera descobertas que são publicadas pelo Pub/Sub e, em seguida, são gravadas na tabela events no BigQuery pelo Dataflow. Em seguida, você pode distribuir as descobertas para a ferramenta de correção, conforme descrito em 1. Conformidade com o controle de dados.
O diagrama a seguir mostra os serviços que se aplicam a esse controle.

Para atender aos requisitos desse controle, a arquitetura usa os seguintes serviços:
- Um data warehouse do BigQuery armazena os dados confidenciais e as vinculações de tags de política para controles de acesso refinados.
- O IAM gerencia o acesso.
- O Data Catalog armazena as tags no nível da tabela e na coluna para a categoria sensível.
- Duas instâncias do Cloud Run da seguinte maneira:
- Uma instância executa o Report Engine, que verifica se as tags são aplicadas e publica os resultados.
- Outra instância executa o mecanismo de tags, que marca os dados no data warehouse protegido.
Para detectar problemas relacionados a esse controle, a arquitetura verifica se os dados confidenciais têm uma tag de política correspondente.
8. O acesso, o uso e os resultados éticos dos dados são gerenciados
Esse controle exige que a arquitetura armazene contratos de compartilhamento de dados do provedor de dados e dos consumidores de dados, incluindo uma lista de finalidades de consumo aprovadas. A finalidade de consumo para os dados confidenciais é então mapeada para os direitos armazenados no BigQuery usando rótulos de consulta.
Quando um consumidor consulta dados confidenciais no BigQuery, ele precisa especificar uma finalidade válida que corresponda ao direito dele (por exemplo, SET @@query_label = “use:3”;).
A arquitetura usa o Data Catalog para adicionar as seguintes tags ao modelo de tag CDMC controls. Essas tags representam o contrato de compartilhamento de dados com o provedor de dados:
approved_use: o uso aprovado ou os usuários do recurso de dadossharing_scope_geography: a lista de locais geográficos em que o recurso de dados pode ser compartilhadosharing_scope_legal_entity: a lista de entidades que podem compartilhar o recurso de dados
Um data warehouse separado do BigQuery inclui o conjunto de dados entitlement_management com as seguintes tabelas:
provider_agreement: o contrato de compartilhamento de dados com o provedor de dados, incluindo a entidade legal combinada e o escopo geográfico. Esses dados são os padrões das tagsshared_scope_geographyesharing_scope_legal_entity.consumer_agreement: o contrato de compartilhamento de dados com o consumidor de dados, incluindo a entidade legal combinada e o escopo geográfico. Cada contrato está associado a uma vinculação do IAM para o recurso de dados.use_purpose: a finalidade de consumo, como a descrição de uso e as operações permitidas para o recurso de dados.data_asset: informações sobre o recurso de dados, como o nome do recurso e detalhes sobre o proprietário dos dados.
Para auditar contratos de compartilhamento de dados, o BigQuery mantém uma trilha de auditoria completa para cada job e consulta em cada conjunto de dados. A trilha de auditoria é armazenada na visualização Jobs do esquema de informações do BigQuery. Depois de associar um rótulo de consulta a uma sessão e executar consultas dentro da sessão, você pode coletar registros de auditoria para consultas com esse rótulo. Para mais informações, consulte a referência do registro de auditoria do BigQuery.
O diagrama a seguir mostra os serviços que se aplicam a esse controle.

Para atender aos requisitos desse controle, a arquitetura usa os seguintes serviços:
- Dois data warehouses do BigQuery: um armazena os dados confidenciais e o outro armazena os dados de direito, que incluem os acordos de compartilhamento de dados entre provedor e consumidor e a finalidade de uso aprovada.
- O Data Catalog armazena as informações do contrato de compartilhamento de dados do provedor como tags.
- Duas instâncias do Cloud Run da seguinte maneira:
- Uma instância executa o Report Engine, que verifica se as tags são aplicadas e publica os resultados.
- Outra instância executa o mecanismo de tags, que marca os dados no data warehouse protegido.
- O Pub/Sub publica descobertas.
Para detectar problemas relacionados a esse controle, a arquitetura inclui as seguintes descobertas:
- Se há uma entrada para um recurso de dados no conjunto de dados
entitlement_management. - Se uma operação é executada em uma tabela confidencial com um caso de uso expirado (por exemplo, o
valid_until_datenoconsumer_agreement tableexpirou). - Se uma operação é executada em uma tabela confidencial com uma chave de rótulo incorreta.
- Se uma operação é executada em uma tabela confidencial com um valor de rótulo de caso de uso em branco ou não aprovado.
- Se uma tabela confidencial é consultada com um método de operação não aprovado (por exemplo,
SELECTouINSERT). - Se a finalidade registrada especificada pelo consumidor ao consultar os dados confidenciais corresponde ao contrato de compartilhamento de dados.
9. Os dados são protegidos e os controles são evidenciados.
Esse controle requer a implementação da desidentificação e criptografia de dados para ajudar a proteger dados confidenciais e fornecer um registro desses controles.
Essa arquitetura se baseia na segurança padrão do Google, que inclui criptografia em repouso. Além disso, a arquitetura permite que você gerencie suas próprias chaves usando chaves de criptografia gerenciadas pelo cliente (CMEK, na sigla em inglês). O Cloud KMS permite que você criptografe seus dados com chaves de criptografia compatíveis com software ou módulos de segurança de hardware validados pelo FIPS 140-2 nível 3 (HSMs, na sigla em inglês).
A arquitetura usa o mascaramento de dados dinâmico no nível da coluna configurado por tags de política e armazena dados confidenciais em um perímetro separado do VPC Service Controls. Também é possível adicionar a desidentificação no nível do aplicativo, que pode ser implementada no local ou como parte do pipeline de ingestão de dados.
Por padrão, a arquitetura implementa a criptografia CMEK com HSMs, mas também é compatível com o Gerenciador de chaves externas do Cloud (Cloud EKM).
A tabela a seguir descreve o exemplo de política de segurança que a arquitetura implementa para a região us-central1. É possível adaptar a política para atender aos seus requisitos, incluindo a adição de políticas diferentes para regiões distintas.
| Sensibilidade de dados | Método de criptografia padrão | Outros métodos de criptografia permitidos | Método de desidentificação padrão | Outros métodos de desidentificação permitidos |
|---|---|---|---|---|
| Informações públicas | Criptografia padrão | Tudo | Nenhum | Tudo |
| Informações de identificação pessoal confidenciais | CMEK com HSM | EKM | Anular | Hash ou valor de mascaramento padrão SHA-256 |
| Informações de identificação pessoal | CMEK com HSM | EKM | Hash SHA-256 | Valor de mascaramento padrão ou nulo |
| Informações pessoais confidenciais | CMEK com HSM | EKM | Valor de mascaramento padrão | hash SHA-256 ou nulo |
| Informações pessoais | CMEK com HSM | EKM | Valor de mascaramento padrão | hash SHA-256 ou nulo |
A arquitetura usa o Data Catalog para adicionar a tag encryption_method ao modelo de tag CDMC controls no nível da tabela. O encryption_method define o método de criptografia usado pelo recurso de dados.
Além disso, a arquitetura cria uma tag security policy template para identificar qual método de desidentificação é aplicado a um campo específico. A arquitetura usa o platform_deid_method aplicado com a máscara de dados dinâmica. É possível adicionar app_deid_method e preenchê-lo usando os
pipelines de ingestão de dados do Dataflow e da proteção de dados confidenciais incluídos no
blueprint de data warehouse seguro.
O diagrama a seguir mostra os serviços que se aplicam a esse controle.

Para atender aos requisitos desse controle, a arquitetura usa os seguintes serviços:
- Duas instâncias opcionais do Dataflow: uma realiza a desidentificação no nível do aplicativo e a outra realiza a reidentificação.
- Três data warehouses do BigQuery: um armazena os dados confidenciais, um armazena os dados não confidenciais e o terceiro armazena a política de segurança.
- O Data Catalog armazena os modelos de tag de criptografia e desidentificação.
- Duas instâncias do Cloud Run da seguinte maneira:
- Uma instância executa o Report Engine, que verifica se as tags são aplicadas e publica os resultados.
- Outra instância executa o mecanismo de tags, que marca os dados no data warehouse protegido.
- O Pub/Sub publicou as descobertas.
Para detectar problemas relacionados a esse controle, a arquitetura inclui as seguintes descobertas:
- O valor da tag do método de criptografia não corresponde aos métodos de criptografia permitidos para a sensibilidade e localização especificadas.
- Uma tabela contém colunas confidenciais, mas a tag de modelo de política de segurança contém um método de desidentificação inválido no nível da plataforma.
- Uma tabela contém colunas confidenciais, mas a tag do modelo de política de segurança está ausente.
10. Uma estrutura de privacidade de dados é definida e operacional
Esse controle exige que a arquitetura inspecione o catálogo de dados e as classificações para determinar se é necessário criar um relatório de avaliação de impacto da proteção de dados (DPIA, na sigla em inglês) ou um relatório de avaliação de impacto da privacidade (PIA, na sigla em inglês). As avaliações de privacidade variam significativamente entre regiões e reguladores. Para determinar se uma avaliação de impacto é necessária, a arquitetura precisa considerar a residência dos dados e a residência do titular dos dados.
A arquitetura usa o Data Catalog para adicionar as seguintes tags ao modelo de tag Impact assessment.
subject_locations: o local dos sujeitos referidos pelos dados neste recurso.is_dpia: se uma avaliação de impacto da privacidade de dados (DPIA, na sigla em inglês) foi concluída para esse recurso.is_pia: se uma avaliação de impacto de privacidade (PIA, na sigla em inglês) foi concluída para esse recurso.impact_assessment_reports: link externo para onde o relatório de avaliação de impacto está armazenado.most_recent_assessment: a data da avaliação de impacto mais recente.oldest_assessment: a data da primeira avaliação de impacto.
O Tag Engine adiciona essas tags a cada recurso de dados confidenciais, conforme definido pelo controle 6. O detector valida essas tags em uma tabela de políticas no BigQuery, que inclui combinações válidas de residência de dados, local do objeto, confidencialidade dos dados (por exemplo, se é PII) e que tipo de avaliação de impacto (seja PIA ou DPIA) é obrigatório.
O diagrama a seguir mostra os serviços que se aplicam a esse controle.

Para atender aos requisitos desse controle, a arquitetura usa os seguintes serviços:
- Quatro data warehouses do BigQuery armazenam as seguintes informações:
- Dados confidenciais
- Dados não confidenciais
- Política de avaliação de impacto e carimbos de data/hora de direitos
- Exportações de tags usadas para o painel
- O Data Catalog armazena os detalhes da avaliação de impacto em tags nos modelos de tag.
- Duas instâncias do Cloud Run da seguinte maneira:
- Uma instância executa o Report Engine, que verifica se as tags são aplicadas e publica os resultados.
- Outra instância executa o mecanismo de tags, que marca os dados no data warehouse protegido.
- O Pub/Sub publica descobertas.
Para detectar problemas relacionados a esse controle, a arquitetura inclui as seguintes descobertas:
- Os dados confidenciais existem sem um modelo de avaliação de impacto.
- Os dados confidenciais existem sem um link para um relatório de DPIA ou PIA.
- As tags não atendem aos requisitos na tabela de políticas.
- A avaliação de impacto é mais antiga do que o direito aprovado mais recentemente para o recurso de dados na tabela de contratos do consumidor.
11. O ciclo de vida dos dados é planejado e gerenciado
Esse controle requer a capacidade de inspecionar todos os recursos de dados para determinar se uma política de ciclo de vida dos dados existe e se está em conformidade.
A arquitetura usa o Data Catalog para adicionar as seguintes tags ao modelo de tag CDMC controls.
retention_period: o tempo, em dias, para reter a tabela.expiration_action: arquivar ou limpar a tabela quando o período de armazenamento terminar
Por padrão, a arquitetura usa o seguinte período de armazenamento e ação de expiração:
| Categoria de dados | Período de armazenamento em dias | Ação de expiração |
|---|---|---|
| Informações de identificação pessoal confidenciais | 60 | Remover |
| Informações de identificação pessoal | 90 | Arquivo |
| Informações pessoais confidenciais | 180 | Arquivo |
| Informações pessoais | 180 | Arquivo |
O Record Manager, um recurso de código aberto do BigQuery, automatiza a limpeza e o arquivamento de tabelas do BigQuery com base nos valores de tag acima e em um arquivo de configuração. O procedimento de limpeza define uma data de validade em uma tabela e cria uma tabela de snapshot com um prazo de validade definido na configuração do Gerenciador de registros. Por padrão, o prazo de validade é de 30 dias. Durante o período de exclusão reversível, é possível recuperar a tabela. O procedimento de arquivamento cria uma tabela externa para cada tabela do BigQuery que passa pelo período de armazenamento. A tabela é armazenada no Cloud Storage no formato parquet e atualizada para uma tabela BigLake que permite que o arquivo externo seja marcado com metadados no Data Catalog.
O diagrama a seguir mostra os serviços que se aplicam a esse controle.

Para atender aos requisitos desse controle, a arquitetura usa os seguintes serviços:
- Dois data warehouses do BigQuery: um armazena os dados confidenciais e o outro armazena a política de retenção de dados.
- Duas instâncias do Cloud Storage, uma fornece armazenamento de arquivos e os outros armazenamentos.
- O Data Catalog armazena o período e a ação de retenção em modelos de tag e nas tags.
- Duas instâncias do Cloud Run, uma executa o Gerenciador de registros e a outra implanta os detectores.
- Três instâncias do Cloud Run da seguinte maneira:
- Uma instância executa o Report Engine, que verifica se as tags são aplicadas e publica os resultados.
- Outra instância executa o mecanismo de tags, que marca os dados no data warehouse protegido.
- Outra instância executa o Gerenciador de registros, que automatiza a limpeza e o arquivamento de tabelas do BigQuery.
- O Pub/Sub publica descobertas.
Para detectar problemas relacionados a esse controle, a arquitetura inclui as seguintes descobertas:
- Para recursos confidenciais, verifique se o método de retenção está alinhado com a política de localização do recurso.
- Para recursos confidenciais, verifique se o período de armazenamento está alinhado com a política de localização do recurso.
12. A qualidade dos dados é gerenciada
Esse controle requer a capacidade de medir a qualidade dos dados com base na criação de perfil de dados ou métricas definidas pelo usuário.
A arquitetura inclui a capacidade de definir regras de qualidade de dados para um valor individual ou agregado e atribuir limites a uma coluna específica da tabela. Ele inclui modelos de tag para precisão e integridade. O Data Catalog adiciona as seguintes tags a cada modelo de tag:
column_name: o nome da coluna à qual a métrica se aplicametric: o nome da métrica ou da regra de qualidaderows_validated: o número de linhas validadassuccess_percentage: a porcentagem de valores que satisfazem a métrica.acceptable_threshold: o limite aceitável para esta métricameets_threshold: se o Índice de qualidade (o valorsuccess_percentage) atende ao limite aceitávelmost_recent_run: o horário mais recente em que a métrica ou a regra de qualidade foi executada
O diagrama a seguir mostra os serviços que se aplicam a esse controle.

Para atender aos requisitos desse controle, a arquitetura usa os seguintes serviços:
- Três data warehouses do BigQuery: um armazena os dados confidenciais, um armazena os não confidenciais e o terceiro armazena as métricas da regra de qualidade.
- O Data Catalog armazena os resultados de qualidade de dados em tags e modelos de tag.
- O Cloud Scheduler define quando o Cloud Data Quality Engine é executado.
- Três instâncias do Cloud Run da seguinte maneira:
- Uma instância executa o Report Engine, que verifica se as tags são aplicadas e publica os resultados.
- Outra instância executa o mecanismo de tags, que marca os dados no data warehouse protegido.
- A terceira instância executa o Cloud Data Quality Engine.
- O Cloud Data Quality Engine define regras de qualidade de dados e programa verificações de qualidade de dados para tabelas e colunas.
- O Pub/Sub publica descobertas.
Um painel do Looker Studio mostra os relatórios de qualidade de dados nos níveis da tabela e da coluna.
Para detectar problemas relacionados a esse controle, a arquitetura inclui as seguintes descobertas:
- Os dados são confidenciais, mas nenhum modelo de tag de qualidade de dados é aplicado (correção e integridade).
- Os dados são confidenciais, mas a tag de qualidade de dados não é aplicada à coluna confidencial.
- Os dados são confidenciais, mas os resultados de qualidade de dados não estão dentro do limite definido na regra.
- Os dados não são confidenciais e os resultados de qualidade de dados não estão dentro do limite definido pela regra.
Como alternativa ao Cloud Data Quality Engine, configure as tarefas de qualidade de dados do Dataplex Universal Catalog.
13. Os princípios de gerenciamento de custos são estabelecidos e aplicados
Esse controle requer a capacidade de inspecionar recursos de dados para confirmar o uso do custo, com base nos requisitos da política e na arquitetura de dados. As métricas de custo devem ser abrangentes, e não apenas limitadas ao uso e à movimentação do armazenamento.
A arquitetura usa o Data Catalog para adicionar as seguintes tags ao modelo de tag cost_metrics.
total_query_bytes_billed: número total de bytes de consulta que foram cobrados por esse recurso de dados desde o início do mês atual.total_storage_bytes_billed: número total de bytes de armazenamento que foram faturados por esse recurso de dados desde o início do mês atual.total_bytes_transferred: soma de bytes transferidos entre regiões neste recurso de dados.estimated_query_cost: custo estimado da consulta, em dólares americanos, para o recurso de dados do mês atual.estimated_storage_cost: custo de armazenamento estimado, em dólares americanos, para o recurso de dados do mês atual.estimated_egress_cost: saída estimada em dólares americanos para o mês atual em que o recurso de dados foi usado como tabela de destino.
A arquitetura exporta informações de preços do Cloud Billing para uma tabela do BigQuery chamada cloud_pricing_export.
O diagrama a seguir mostra os serviços que se aplicam a esse controle.

Para atender aos requisitos desse controle, a arquitetura usa os seguintes serviços:
- O Cloud Billing fornece informações de faturamento.
- O Data Catalog armazena as informações de custo em tags e modelos de tag.
- O BigQuery armazena as informações de preços exportadas e as informações do histórico do job de consulta pela visualização integrada INFORMATION_SCHEMA.
- Duas instâncias do Cloud Run da seguinte maneira:
- Uma instância executa o Report Engine, que verifica se as tags são aplicadas e publica os resultados.
- Outra instância executa o mecanismo de tags, que marca os dados no data warehouse protegido.
- O Pub/Sub publica descobertas.
Para detectar problemas relacionados a esse controle, a arquitetura verifica se os recursos de dados confidenciais existem sem ter métricas de custo associadas a eles.
14. A procedência dos dados e a linhagem são compreendidas
Esse controle requer a capacidade de inspecionar a rastreabilidade do ativo de dados a partir da sua origem e quaisquer alterações na linhagem do ativo de dados.
Para manter as informações sobre a procedência e a linhagem dos dados, a arquitetura usa os recursos integrados da linhagem de dados no Data Catalog. Além disso, os scripts de ingestão de dados definem a fonte final e a adicionam como um nó extra ao gráfico de linhagem de dados.
Para atender aos requisitos desse controle, a arquitetura usa o Data Catalog para adicionar a tag ultimate_source ao modelo de tag CDMC
controls. A tag ultimate_source define a origem desse
recurso de dados.
O diagrama a seguir mostra os serviços que se aplicam a esse controle.

Para atender aos requisitos desse controle, a arquitetura usa os seguintes serviços:
- Dois data warehouses do BigQuery: um armazena os dados confidenciais e o outro armazena os dados de origem finais.
- O Data Catalog armazena a origem final em tags e modelos de tag.
- Os scripts de ingestão de dados carregam os dados do Cloud Storage, definem a origem final e adicionam a origem ao gráfico de linhagem de dados.
- Duas instâncias do Cloud Run da seguinte maneira:
- Uma instância executa o Report Engine, que verifica se as tags são aplicadas e publica os resultados.
- Outra instância executa o mecanismo de tags, que marca os dados no data warehouse protegido.
- O Pub/Sub publica descobertas.
Para detectar problemas relacionados a esse controle, a arquitetura inclui as seguintes verificações:
- Os dados confidenciais são identificados sem a tag de origem final.
- O gráfico de linhagem não é preenchido para recursos de dados confidenciais.
Referência da tag
Nesta seção, descrevemos os modelos e tags usados por essa arquitetura para atender aos requisitos dos controles de chave do CDMC.
Modelos de tag de controle CDMC no nível da tabela
A tabela a seguir lista as tags que fazem parte do modelo de tag de controle do CDMC e que são aplicadas às tabelas.
| Tag | ID da tag | Controle de chave aplicável |
|---|---|---|
| Local de armazenamento aprovado | approved_storage_location |
4 |
| Uso aprovado | approved_use |
8 |
| E-mail do proprietário dos dados | data_owner_email |
2 |
| Nome do proprietário dos dados | data_owner_name |
2 |
| Método de criptografia | encryption_method |
9 |
| Ação de expiração | expiration_action |
11 |
| É autoritativo | is_authoritative |
3 |
| É confidencial | is_sensitive |
6 |
| Categoria sensível | sensitive_category |
6 |
| Geografia do escopo de compartilhamento | sharing_scope_geography |
8 |
| Entidade legal do escopo de compartilhamento | sharing_scope_legal_entity |
8 |
| Período de retenção | retention_period |
11 |
| Fonte máxima | ultimate_source |
14 |
Modelo de tag de avaliação de impacto
A tabela a seguir lista as tags que fazem parte do modelo da tag de avaliação de impacto e são aplicadas às tabelas.
| Tag | ID da tag | Controle de chave aplicável |
|---|---|---|
| Locais do assunto | subject_locations |
10 |
| É avaliação de impacto da DPIA | is_dpia |
10 |
| Avaliação do impacto da PIA | is_pia |
10 |
| Relatórios de avaliação de impacto | impact_assessment_reports |
10 |
| Avaliação de impacto mais recente | most_recent_assessment |
10 |
| Avaliação de impacto mais antiga | oldest_assessment |
10 |
Modelo de tag de métricas de custo
A tabela a seguir lista as tags que fazem parte do modelo de métricas de custo e que são aplicadas às tabelas.
| Tag | Guia ID | Controle de chave aplicável |
|---|---|---|
| Custo estimado da consulta | estimated_query_cost |
13 |
| Custo de armazenamento estimado | estimated_storage_cost |
13 |
| Custo estimado de saída | estimated_egress_cost |
13 |
| Total de bytes de consulta cobrados | total_query_bytes_billed |
13 |
| Total de bytes de armazenamento cobrados | total_storage_bytes_billed |
13 |
| Total de bytes transferidos | total_bytes_transferred |
13 |
Modelo de tag de confidencialidade de dados
A tabela a seguir lista as tags que fazem parte do modelo de tag de confidencialidade de dados e que são aplicadas aos campos.
| Tag | ID da tag | Controle de chave aplicável |
|---|---|---|
| Campo confidencial | sensitive_field |
6 |
| Tipo sensível | sensitive_category |
6 |
Modelo de tag de política de segurança
A tabela a seguir lista as tags que fazem parte do modelo de tag de política de segurança e são aplicadas aos campos.
| Tag | ID da tag | Controle de chave aplicável |
|---|---|---|
| Método de desidentificação do aplicativo | app_deid_method |
9 |
| Método de desidentificação da plataforma | platform_deid_method |
9 |
Modelos de tag de qualidade de dados
A tabela a seguir lista as tags que fazem parte dos modelos de tag de integridade de dados e correção e que são aplicadas aos campos.
| Tag | ID da tag | Controle de chave aplicável |
|---|---|---|
| Limite aceitável | acceptable_threshold |
12 |
| Nome da coluna | column_name |
12 |
| Atende ao limite | meets_threshold |
12 |
| Métrica | metric |
12 |
| Execução mais recente | most_recent_run |
12 |
| Linhas validadas | rows_validated |
12 |
| Porcentagem de sucesso | success_percentage |
12 |
Tags de política de CDMC no nível do campo
A tabela a seguir lista as tags de política que fazem parte da taxonomia de tags da política de classificação de dados confidenciais do CDMC e que são aplicadas aos campos. Essas tags de política restringem o acesso no nível do campo e permitem a desidentificação de dados no nível da plataforma.
| Classificação de dados | Nome da tag | Controle de chave aplicável |
|---|---|---|
| Informações de identificação pessoal | personal_identifiable_information |
7 |
| Informações pessoais | personal_information |
7 |
| Informações de identificação pessoal confidenciais | sensitive_personal_identifiable_information |
7 |
| Informações pessoais confidenciais | sensitive_personal_data |
7 |
Metadados técnicos pré-preenchidos
A tabela a seguir lista os metadados técnicos sincronizados por padrão no Data Catalog para todos os recursos de dados do BigQuery.
| Metadados | Controle de chave aplicável |
|---|---|
| Tipo de recurso | — |
| Horário da criação | — |
| Data de vencimento | 11 |
| Local | 4 |
| URL do recurso | 3 |
A seguir
- Saiba mais sobre o CDMC.
- Leia sobre os controles de segurança usados pelo esquema de data warehouse seguro.
- Descubra o Data Catalog.
- Saiba mais sobre o Dataplex Universal Catalog.
- Saiba mais sobre o Tag Engine.
- Implemente esta solução usando a Google Cloud arquitetura de referência do CDMC no GitHub.