假名化是一种去标识化技术,使用以加密方式生成的“令牌”替换敏感数据值。假名化在金融和医疗保健等行业广泛使用,有助于降低数据使用风险,缩小合规工作范围,并最大限度地减少敏感数据在系统中的暴露,同时保持数据的实用性和准确性。
敏感数据保护支持三种假名化去标识化技术,并通过将三种加密转换方法之一应用于原始敏感数据值来生成令牌。然后,将每个原始敏感值替换为相应的令牌。假名化有时称为“标记化”或“代理替换”。
假名化技术支持单向或双向令牌。单向令牌已逆向转换,而双向令牌可以逆转。由于令牌是使用对称加密创建的,因此可以生成新令牌的加密密钥也可以逆转令牌。对于不需要逆转的情况,您可以使用采用安全哈希机制的单向令牌。
了解假名化在使您的业务运营和分析工作流易于访问和使用所需的数据的同时如何帮助保护敏感数据会很有帮助。本主题介绍了假名化的概念,以及用于转换敏感数据保护支持的数据的三种加密方法。
如需了解如何实现这些假名化方法以及查看更多敏感数据保护用例,请参阅对敏感数据进行去标识化。
Sensitive Data Protection 中受支持的加密方法
敏感数据保护支持三种假名化技术,所有这些技术都使用加密密钥。以下是可用的方法:
- 使用 AES-SIV 的确定性加密:输入值替换为使用 AES-SIV 加密算法和加密密钥进行加密、使用 base64 进行编码然后加上了一个代理注释(如果指定)的值。此方法会生成哈希值,因此它不会保留字符集或输入值的长度。可以使用原始加密密钥和整个输出值(包括代理注释)对已加密的哈希值进行重标识。详细了解使用 AES-SIV 加密进行标记化的值的格式。
- 保留格式加密:输入值被替换为使用 FPE-FFX 加密算法和加密密钥加密的值,后跟代理注解(如果指定)。从设计上来说,输入值的字符集和长度都会保留在输出值中。可以使用原始加密密钥和整个输出值(包括代理注释)对已加密的值进行重标识。(有关使用此加密方法的一些重要注意事项,请参阅本主题后面的保留格式加密。)
- 加密哈希:将输入值替换为已使用基于哈希的消息身份验证代码 (HMAC)-安全哈希算法 (SHA)-256进行加密和哈希处理的值(输入值采用了加密密钥)。转换的哈希输出长度始终相同,且无法重标识。详细了解使用加密哈希进行标记的值的格式。
下表汇总了这些假名化方法。表行在表后有说明。
| 使用 AES-SIV 的确定性加密 | 保留格式加密 | 加密哈希 | |
|---|---|---|---|
| 加密类型 | AES-SIV | FPE-FFX | HMAC-SHA-256 |
| 支持的输入值 | 长度为至少 1 个字符;无字符集限制。 | 长度为至少 2 个字符;必须采用 ASCII 编码。 | 必须是字符串或整数值。 |
| 代理注释 | 可选。 | 可选。 | 无 |
| 上下文调整 | 可选。 | 可选。 | 无 |
| 保留的字符集和长度 | ✗ | ✓ | ✗ |
| 可逆转 | ✓ | ✓ | ✗ |
| 参照完整性 | ✓ | ✓ | ✓ |
- 加密类型:去标识化转换中使用的加密种类。
- 支持的输入值:输入值的最低要求。
- 代理注解:用户指定的注解,附加到加密值之前,以便向用户提供上下文,并提供信息供 Sensitive Data Protection 用于重标识去标识化的值。要对非结构化数据进行重标识,必须提供代理注释。如果使用
RecordTransformation转换结构化数据列或表格数据列,则代理注释是可选的。 - 上下文调整:对数据字段的引用,用于“调整”输入值,以便将相同的输入值去标识化为不同的输出值。使用
RecordTransformation转换结构化数据列或表格数据列时,上下文调整是可选的。如需了解详情,请参阅使用上下文调整。 - 保留的字符集和长度:无论去标识化的值是否由与原始值相同的一组字符组成,无论去标识化的值的长度是否与原始值相同。
- 可逆转:可以使用加密密钥、代理注释和任何上下文调整进行重标识。
- 参照完整性:参照完整性允许即使在对数据单独去标识化之后,也可以保持记录之间的关系。使用相同的加密密钥和上下文调整,数据表在每次转换时都将替换为相同的混淆形式,这确保了值(以及记录 - 对于结构化数据)之间的关联得以保留,甚至在表之间也是如此。
Sensitive Data Protection 中的令牌化功能的运作方式
对于敏感数据保护支持的全部三种方法,标记化的基本过程都是相同的。
第 1 步:Sensitive Data Protection 选择要标记化的数据。这样做的最常见的方法是使用内置或自定义 infoType 检测器来匹配所需的敏感数据值。如果要扫描结构化数据(例如 BigQuery 表),您还可以使用记录转换对整个数据列执行标记化。
如需详细了解这两类转换(infoType 转换和记录转换),请参阅去标识化转换。
第 2 步:使用加密密钥,敏感数据保护功能会对每个输入值进行加密。您可以通过下述三种方式之一提供此密钥:
- 使用 Cloud Key Management Service (Cloud KMS) 封装此密钥。(要最大限度地提高安全性,Cloud KMS 是首选方法。)
- 使用暂时性密钥,Sensitive Data Protection 在去标识化时生成该密钥,然后舍弃。暂时性密钥仅为每个 API 请求保持完整性。如果您需要完整性或打算重标识此数据,请勿使用该密钥类型。
- 直接采用原始文本形式。(不推荐。)
如需了解详情,请参阅本主题后面介绍的使用加密密钥部分。
第 3 步(仅加密哈希和使用 AES-SIV 的确定性加密):敏感数据保护功能使用 base64 对加密值进行编码。在使用加密哈希技术时,此编码的加密值是令牌,该过程在第 6 步中继续。对于使用 AES-SIV 的确定性加密,这种编码的加密值就是代理值,而且它只是令牌的一个组成部分。第 4 步继续执行该过程。
第 4 步(仅限使用 AES-SIV 的保留格式加密和确定性加密):敏感数据保护会向加密值添加可选代理注解。代理注释通过在您定义的描述性字符串前面加上加密代理值来帮助识别加密代理值。例如,如果没有注释,您可能无法区分可识别的电话号码、去标识化的社会保障号或其他身份号码。此外,如需重新标识使用保留格式加密或确定性加密功能进行了去标识化的非结构化数据中的值,您必须指定代理注释。(使用 RecordTransformation 转换结构化数据列或表格数据列时,不需要使用代理注释。)
第 5 步(仅使用 AES-SIV 对结构化数据的保留格式加密和确定性加密):敏感数据保护可以使用其他字段中的可选上下文来“调整”生成的令牌。这样您就可以更改令牌的范围。例如,假设您有一个营销广告系列数据库,其中包含电子邮件地址,并且您希望按广告系列 ID 为同一个“经调整的”电子邮件地址生成唯一令牌。这将允许同一用户在同一广告系列内(而不是在不同广告系列之间)联接同一用户的数据。如果使用上下文调整来创建令牌,则要逆转去标识化转换,还需要此上下文调整。使用 AES-SIV 支持上下文的保留格式加密和确定性加密。详细了解使用上下文调整。
第 6 步:敏感数据保护功能会将原始值替换为去标识化的值。
标记化值比较
本部分演示了使用本主题中讨论的三种方法去标识化后典型令牌的显示情况。敏感数据值示例是北美电话号码 (1-206-555-0123)。
使用 AES-SIV 的确定性加密
使用确定性加密和 AES-SIV 进行去标识化时,输入值(以及任何指定的上下文调整)使用 AES-SIV 和加密密钥进行加密,使用 base64 进行编码,然后可以选择加上一个代理注释(如果指定)。该方法不会保留输入值的字符集(或“字母表”)。为了生成可打印的输出,生成的值使用 base64 进行编码。
假设指定了代理 infoType,则生成的令牌采用以下格式:
SURROGATE_INFOTYPE(SURROGATE_VALUE_LENGTH):SURROGATE_VALUE
以下已添加注释的图表展示了一个示例令牌,即通过对 1-206-555-0123 值使用 AES-SIV 执行去标识化操作的输出。可选的代理 infoType 已设置为 NAM_PHONE_NUMB:

- 代理注释
- 代理 infoType(由用户定义)
- 转换后的值的字符长度
- 代理(已转换的)值
如果未指定代理注释,则生成的令牌等于转换后的值,或已添加注释的图表中的 #4。要重新标识非结构化数据,需要这整个令牌(包括代理注释)。转换结构化数据(如表)时,代理注解是可选的;敏感数据保护功能可以使用 RecordTransformation(而不使用代理注解)对整个列执行去标识化和重标识。
保留格式加密
使用保留格式加密进行去标识化时,输入值(以及任何指定的上下文调整)使用保留格式加密的 FFX 模式 ("FPE-FFX") 和加密密钥进行加密,然后可以选择加上一个代理注释(如果指定)。
与本主题中介绍的标记化方法不同,输出代理值与输入值具有相同的长度,并且不会使用 base64 进行编码。您可以定义加密值所属的字符集(或“字母表”)。您可以通过三种方式指定要在敏感数据保护的输出值中使用的字母表:
- 使用四个枚举值之一来表示第四种最常见的字符集/字母表。
- 使用 Radix 值,用于指定字母表大小。指定最小 Radix 值
2会生成仅包含0和1的字母表。指定最大 Radix 值95会生成包含全部数字字符、大写字母字符、小写字母字符和符号字符的字母表。 - 通过列出要使用的确切字符来构建字母表。例如,指定
1234567890-*会生成由仅包含数字、连字符和星号的代理值。
下表按每个字符集的枚举值 (FfxCommonNativeAlphabet)、Radix 值以及该字符集的字符列表列出了四个常见字符集。最后一行列出了完整字符集,该字符集对应于最大 Radix 值。
| 字母表/字符集名称 | Radix | 字符列表 |
|---|---|---|
NUMERIC |
10 |
0123456789 |
HEXADECIMAL |
16 |
0123456789ABCDEF |
UPPER_CASE_ALPHA_NUMERIC |
36 |
0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ |
ALPHA_NUMERIC |
62 |
0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz |
| - | 95 |
0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz~`!@#$%^&*()_-+={[}]|\:;"'<,>.?/ |
假设指定了代理 infoType,则生成的令牌采用以下格式:
SURROGATE_INFOTYPE(SURROGATE_VALUE_LENGTH):SURROGATE_VALUE
以下已添加注释的图表是 Sensitive Data Protection 去标识化操作(使用通过值为 95 的 Radix 对值 1-206-555-0123 的保留格式加密)的输出。可选的代理 infoType 已设置为 NAM_PHONE_NUMB:
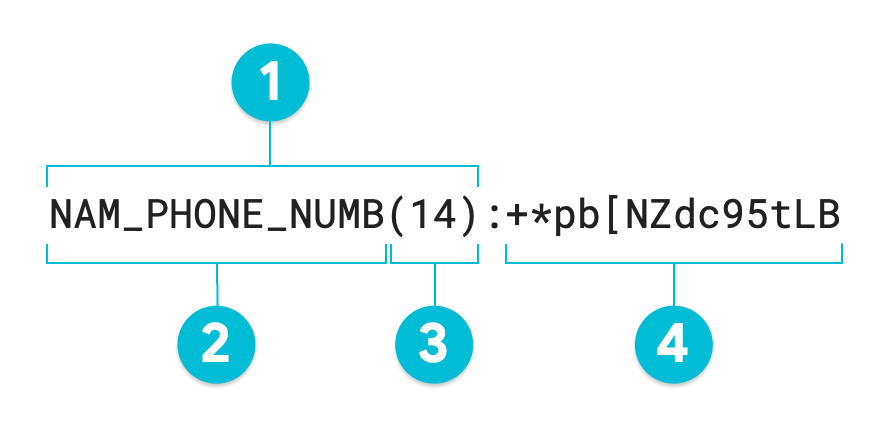
- 代理注释
- 代理 infoType(由用户定义)
- 转换后的值的字符长度
- 代理(已转换的)值 - 与输入值长度相同
如果未指定代理注释,则生成的令牌等于转换后的值,或已添加注释的图表中的 #4。要重新标识非结构化数据,需要这整个令牌(包括代理注释)。转换结构化数据(如表)时,代理注解是可选的;敏感数据保护功能可以使用 RecordTransformation(而不使用代理注解)对整个列执行去标识化和重标识。
加密哈希
借助加密哈希进行去标识化时,输入值通过 HMAC-SHA-256 和加密密钥进行哈希处理,然后使用 base64 进行编码。去标识化的值始终是统一长度,具体取决于密钥的大小。
与本主题介绍的其他标记化方法不同,加密哈希创建单向令牌。也就是说,使用加密哈希的去标识化操作无法撤消。
以下是使用加密哈希对值 1-206-555-0123 进行去标识化操作的输出。此输出是以 base64 编码表示的哈希值:
XlTCv8h0GwrCZK+sS0T3Z8txByqnLLkkF4+TviXfeZY=
使用加密密钥
对于加密密钥,有三种选项可以与敏感数据保护中的加密去标识化方法一起使用:
Cloud KMS 封装的加密密钥:这是可用于敏感数据保护去标识化方法的最安全加密密钥类型。Cloud KMS 封装的密钥由 128 位、192 位或 256 位加密密钥组成,该加密密钥已使用另一个密钥加密。您提供第一个加密密钥,然后使用 Cloud Key Management Service 存储的加密密钥进行封装。这些类型的密钥存储在 Cloud KMS 中,供日后重标识。如需详细了解如何创建和封装密钥以进行去标识化和重标识,请参阅快速入门:对敏感文本进行去标识化和重标识。
暂时性加密密钥:暂时性加密密钥是由敏感数据保护在去标识化时生成的,然后被舍弃。因此,请不要将暂时性加密密钥与要逆转的任何加密去标识化方法结合使用。暂时性加密密钥只为每个 API 请求保持完整性。如果您需要跨多个 API 请求的完整性或打算重标识数据,请勿使用此密钥类型。
未封装的加密密钥:未封装的加密密钥是 base64 编码的 128 位、192 位或 256 位原始加密密钥,该加密密钥是您在对 DLP API 的去标识化请求内提供的。您负责确保这些类型的加密密钥稍后可用于重标识。由于存在意外泄露密钥的风险,因此不推荐使用这些类型的密钥。这些密钥可用于测试,但对于生产工作负载,建议改用 Cloud KMS 封装的加密密钥。
如需详细了解使用加密密钥时的可用选项,请参阅 DLP API 参考文档中的 CryptoKey。
使用上下文调整
默认情况下,无论输出令牌是单向还是双向,所有去标识化的加密转换方法都具有参照完整性。也就是说,如果使用相同的加密密钥,则输入值始终转换为相同的加密值。在可能出现重复数据或数据模式的情况下,重标识的风险会增加。因此,为了使相同的输入值始终转换为不同的加密值,您可以指定唯一的“上下文调整”。
您可以在转换表格数据时指定上下文调整(在 DLP API 中简称 context),因为该调整实际上是指向数据列的指针,例如标识符。敏感数据保护在加密输入值时使用了上下文调整指定的字段中的值。要确保加密值始终是唯一值,请针对包含唯一标识符的调整指定一列。
请参考这个简单的示例。下表展示了若干医疗记录,其中一些记录包含重复的患者 ID。
| record_id | patient_id | icd10_code |
|---|---|---|
| 5437 | 43789 | E11.9 |
| 5438 | 43671 | M25.531 |
| 5439 | 43789 | N39.0, I25.710 |
| 5440 | 43766 | I10 |
| 5441 | 43766 | I10 |
| 5442 | 42989 | R07.81 |
| 5443 | 43098 | I50.1, R55 |
| … | … | … |
如果您指示 Sensitive Data Protection 对表中的患者 ID 进行去标识化,则默认情况下会将重复的患者 ID 去标识化为相同的值,如下表所示。例如,患者 ID“43789”的两个实例都去标识化为“47222”。(patient_id 列使用 FPE-FFX 进行假名化后显示令牌值,不包含代理注释。如需了解详情,请参阅保留格式加密。)
| record_id | patient_id | icd10_codes |
|---|---|---|
| 5437 | 47222 | E11.9 |
| 5438 | 82160 | M25.531 |
| 5439 | 47222 | N39.0, I25.710 |
| 5440 | 04452 | I10 |
| 5441 | 04452 | I10 |
| 5442 | 47826 | R07.81 |
| 5443 | 52428 | I50.1, R55 |
| … | … | … |
这意味着参照完整性的范围在整个数据集内。
要缩小范围以避免出现此行为,请指定上下文调整。您可以将任何列指定为上下文调整,但为了保证每个去标识化的值都是唯一的,请指定一个列,其中每个值都是唯一的。
假设您想要查看是否按 icd10_codes 值显示相同的患者,而不是同一患者是否出现在不同的 icd10_codes 值中。为此,请指定 icd10_codes 列作为上下文调整。
这是使用 icd10_codes 列作为上下文调整对 patient_id 列进行去标识化后的表:
| record_id | patient_id | icd10_codes |
|---|---|---|
| 5437 | 18954 | E11.9 |
| 5438 | 33068 | M25.531 |
| 5439 | 76368 | N39.0, I25.710 |
| 5440 | 29460 | I10 |
| 5441 | 29460 | I10 |
| 5442 | 23877 | R07.81 |
| 5443 | 96129 | I50.1, R55 |
| … | … | … |
请注意,第四个和第五个去标识化 patient_id 值 (29460) 是相同的,因为不仅原始 patient_id 值相同,而且两行的 icd10_codes 值也相同。由于您需要在 icd10_codes 值的范围内使用一致的患者 ID 运行分析,因此此行为正是您要查找的行为。
要完全切断 patient_id 值和 icd10_codes 值之间的参照完整性,可以改用 record_id 列作为上下文调整:
| record_id | patient_id | icd10_code |
|---|---|---|
| 5437 | 15826 | E11.9 |
| 5438 | 61722 | M25.531 |
| 5439 | 34424 | N39.0, I25.710 |
| 5440 | 02875 | I10 |
| 5441 | 52549 | I10 |
| 5442 | 17945 | R07.81 |
| 5443 | 19030 | I50.1, R55 |
| … | … | … |
请注意,表中的每个去标识化 patient_id 值现在是唯一的。
要了解如何在 DLP API 中使用上下文调整,请注意以下转换方法参考主题中 context 的用法:
- 保留格式加密:
CryptoReplaceFfxFpeConfig - 使用 AES-SIV 的确定性加密:
CryptoDeterministicConfig - 日期偏移:
DateShiftConfig