이 페이지에서는 조직 또는 폴더에서 BigQuery 데이터를 프로파일링하는 비용을 추정하는 방법에 대해 설명합니다. 프로젝트에 대한 추정치를 만들려면 단일 프로젝트의 데이터 프로파일링 비용 추정을 참고하세요.
BigQuery 데이터 프로파일링에 관한 자세한 내용은 BigQuery 데이터의 데이터 프로필을 참고하세요.
개요
데이터 프로필 생성을 시작하기 전에 추정을 실행하여 보유한 BigQuery 데이터 양 및 데이터를 프로파일링하는 데 드는 비용을 파악할 수 있습니다. 추정을 실행하려면 추정치를 만듭니다.
추정치를 만들 때 프로파일링할 데이터가 포함된 리소스(조직, 폴더 또는 프로젝트)를 지정합니다. 필터를 설정하여 데이터 선택을 미세 조정할 수 있습니다. 민감한 정보 보호에서 테이블을 프로파일링하기 전에 충족해야 하는 조건을 설정할 수도 있습니다. 민감한 정보 보호는 개발자가 추정을 만들 때의 데이터 모양, 크기, 유형에 대한 추정치를 기반으로 합니다.
각 추정치에는 리소스에서 발견된 일치하는 테이블 수, 해당 모든 테이블의 총 크기, 리소스를 한 번만 프로파일링하는 데 드는 추정 비용과 같은 세부정보가 포함됩니다.
가격 책정 방식에 관한 자세한 내용은 데이터 프로파일링 가격 책정을 참고하세요.
추정 가격 책정
추정치를 만드는 것은 무료입니다.
보관
각 추정치는 28일 후 자동으로 삭제됩니다.
제한사항
조직이나 폴더에 VPC 서비스 제어 서비스 경계로 보호되는 프로젝트가 있으면 민감한 정보 보호에서 리소스의 BigQuery 데이터 양을 적게 계산할 수 있습니다. 서비스 경계가 있는 경우 각 서비스 경계에 대한 추정치를 독립적으로 만듭니다.
시작하기 전에
데이터 프로파일링 추정 비용을 만들고 관리하는 데 필요한 권한을 얻으려면 관리자에게 조직 또는 폴더에 대한 DLP 관리자 (roles/dlp.admin) IAM 역할을 부여해 달라고 요청하세요.
역할 부여에 대한 자세한 내용은 프로젝트, 폴더, 조직에 대한 액세스 관리를 참조하세요.
커스텀 역할이나 다른 사전 정의된 역할을 통해 필요한 권한을 얻을 수도 있습니다.
추정치 만들기
데이터 프로필 추정치 만들기 페이지로 이동합니다.
조직을 선택합니다.
다음 섹션에서는 데이터 프로필 추정치 만들기 페이지의 단계에 대한 자세한 내용을 제공합니다. 각 섹션의 끝에서 계속을 클릭합니다.
스캔할 리소스 선택
다음 중 하나를 수행합니다.- 조직에 대한 추정치를 만들려면 전체 조직 스캔을 선택합니다.
- 폴더의 예상치를 만들려면 선택한 폴더 스캔을 선택합니다. 그런 다음 찾아보기를 클릭하고 폴더를 선택합니다.
입력 필터 및 조건
조직 또는 폴더의 모든 BigQuery 테이블을 추정치에 포함하려면 이 섹션을 건너뛸 수 있습니다.이 섹션에서는 추정치에 포함하거나 제외할 데이터의 특정 하위 집합을 지정하는 필터를 만듭니다. 추정치에 포함하는 하위 집합의 경우 하위 집합의 테이블이 추정치에 포함되기 위해 충족해야 하는 조건도 지정합니다.
필터 및 조건을 설정하려면 다음 단계를 따르세요.
- 필터 및 조건 추가를 클릭합니다.
필터 섹션에서 추정치 범위에 속하는 테이블을 지정하는 하나 이상의 필터를 정의합니다.
다음 중 하나 이상을 지정합니다.
- 하나 이상의 프로젝트를 지정하는 프로젝트 ID 또는 정규 표현식
- 하나 이상의 데이터 세트를 지정하는 데이터 세트 ID 또는 정규 표현식
- 하나 이상의 테이블을 지정하는 테이블 ID 또는 정규 표현식
정규 표현식은 RE2 구문을 따라야 합니다.
예를 들어 프로젝트의 모든 테이블을 필터에 포함하려면 프로젝트의 ID를 지정하고 다른 두 필드는 비워 둡니다.
필터를 더 추가해야 하면 필터 추가를 클릭하여 이 단계를 반복합니다.
필터로 정의된 데이터의 하위 집합을 추정치에서 제외해야 하는 경우 추정치에 일치하는 테이블 포함을 사용 중지합니다. 이 옵션을 사용 중지하면 이 섹션의 나머지 부분에 설명된 조건이 숨겨집니다.
선택사항: 조건 섹션에서 추정치에 포함되기 위해 일치하는 테이블이 충족해야 하는 조건을 지정합니다. 이 단계를 건너뛰면 민감한 정보 보호에 크기 및 기간과 관계없이 필터와 일치하는 지원되는 테이블이 모두 포함됩니다.
다음 옵션을 구성합니다.
최소 조건: 추정치에서 작은 테이블이나 새 테이블을 제외하려면 최소 행 수 또는 테이블 기간을 설정합니다.
시간 조건: 이전 테이블을 제외하려면 시간 조건을 사용 설정합니다. 그런 다음 날짜와 시간을 선택합니다. 해당 날짜 이전에 생성된 테이블은 추정치에서 제외됩니다.
예를 들어 시간 조건을 5/4/22, 11:59 PM으로 설정하면 민감한 정보 보호는 2022년 5월 4일 오후 11시 59분까지 생성된 모든 테이블을 추정치에서 제외합니다.
프로파일링할 테이블: 추정치에 포함할 테이블 유형을 지정하려면 지정된 유형의 테이블만 포함을 선택합니다. 그런 다음 포함할 테이블 유형을 선택합니다.
이 조건을 사용 설정하지 않거나 테이블 유형을 선택하지 않으면 민감한 정보 보호에서 지원되는 모든 테이블을 추정치에 포함합니다.
다음과 같은 구성이 있다고 가정해 시다.
최소 조건
- 최소 행 수: 10개
- 최소 기간: 24시간
시간 조건
- 타임스탬프: 5/4/22, 11:59 PM
프로파일링할 테이블
지정된 유형의 테이블만 포함 옵션이 선택되어 있습니다. 테이블 유형 목록에서 BigLake 테이블 프로파일링만 선택됩니다.
이 경우 민감한 정보 보호는 2022년 5월 4일 오후 11시 59분까지 생성된 테이블을 제외합니다. 민감한 정보 보호는 이 날짜와 시간 이후에 생성된 테이블 중에서 행이 10개이거나 최소 24시간이 지난 BigLake 테이블만 프로파일링합니다.
완료를 클릭합니다.
필터와 조건을 더 추가하려면 필터 및 조건 추가를 클릭하고 이전 단계를 반복합니다.
필터 및 조건 목록의 마지막 항목은 항상 기본 필터 및 조건 라벨이 지정된 항목입니다. 이 기본 설정은 사용자가 생성한 필터 및 조건과 일치하지 않는 선택한 리소스(조직 또는 폴더)의 테이블에 적용됩니다.
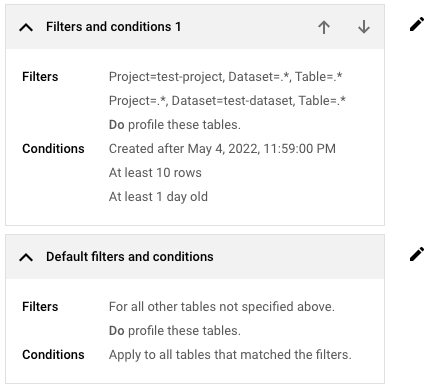
기본 필터 및 조건을 조정하려면 필터 및 조건 수정을 클릭하고 필요에 따라 설정을 조정합니다.
서비스 에이전트 컨테이너 및 결제 관리
이 섹션에서는 서비스 에이전트 컨테이너로 사용할 프로젝트를 지정합니다. Sensitive Data Protection에서 새 프로젝트를 자동으로 만들도록 하거나 개발자가 기존 프로젝트를 선택할 수 있습니다.
새로 만든 서비스 에이전트를 사용하거나 기존 항목을 사용하는지에 관계없이 프로파일링할 데이터에 대해 읽기 액세스가 있는지 확인합니다.
프로젝트 자동 생성
조직에서 프로젝트를 만드는 데 필요한 권한이 없는 경우 기존 프로젝트를 선택하거나 필요한 권한을 획득해야 합니다. 필요한 권한에 관한 자세한 내용은 조직 또는 폴더 수준에서 데이터 프로필을 작업하는 데 필요한 역할을 참고하세요.
서비스 에이전트 컨테이너로 사용할 프로젝트를 자동으로 만들려면 다음 단계를 따르세요.
- 서비스 에이전트 컨테이너 필드에서 제안된 프로젝트 ID를 검토하고 필요에 따라 수정합니다.
- 만들기를 클릭합니다.
- 선택사항: 기본 프로젝트 이름을 업데이트합니다.
검색과 관련 없는 작업을 포함하여 이 새 프로젝트와 관련된 모든 청구 가능 작업의 요금이 청구될 계정을 선택합니다.
만들기를 클릭합니다.
Sensitive Data Protection이 새 프로젝트를 만듭니다. 이 프로젝트 내 서비스 에이전트는 Sensitive Data Protection 및 기타 API에 인증하는 데 사용됩니다.
기존 프로젝트 선택
기존 프로젝트를 서비스 에이전트 컨테이너로 선택하려면 서비스 에이전트 컨테이너 필드를 클릭하고 프로젝트를 선택합니다.
추정치를 저장할 위치 설정
리소스 위치 목록에서 이 추정치를 저장할 리전을 선택합니다.
추정치를 저장하도록 선택한 경우 스캔되는 데이터에 영향을 주지 않습니다. 또한 데이터 프로필이 나중에 저장되는 위치에는 영향을 주지 않습니다. 데이터는 데이터가 저장된 리전과 동일한 리전에서 스캔됩니다(BigQuery에 설정됨). 자세한 내용은 데이터 상주 고려사항을 참조하세요.
설정을 검토하고 만들기를 클릭합니다.
민감한 정보 보호에서 추정치를 만들어 추정치 목록에 추가합니다. 그런 다음 추정을 실행합니다.
리소스의 데이터 양에 따라 추정을 완료하는 데 최대 24시간이 걸릴 수 있습니다. 그동안 민감한 정보 보호 페이지를 닫고 나중에 다시 확인할 수 있습니다. 추정치가 준비되면 Google Cloud console에 알림이 표시됩니다.
추정 비용 보기
추정 목록으로 이동합니다.
확인하려는 추정치를 클릭합니다. 추정치에는 다음이 포함됩니다.
- 리소스의 테이블 수에서 필터 및 조건을 통해 제외한 테이블을 뺀 값입니다.
- 테이블에 해당하는 총 데이터 양입니다.
- 매달 이 정도의 데이터를 프로파일링하는 데 필요한 구독 단위 수입니다.
- 초기 검색 비용으로 발견된 테이블을 프로파일링하는 데 드는 대략적인 비용입니다. 이 추정치는 현재 데이터의 스냅샷만 기반으로 하며 특정 기간 동안 데이터가 얼마나 증가하는지는 고려하지 않습니다.
- 6개월, 12개월 또는 24개월 미만의 테이블만 프로파일링하기 위한 추가 비용 추정치입니다. 이러한 추가 추정치는 데이터 범위를 더 제한하는 경우 데이터 프로파일링 비용을 관리하는 데 얼마나 도움이 되는지 보여주기 위한 것입니다.
- 월별 BigQuery 사용량이 이번 달 사용량과 동일하다고 가정할 때 데이터 프로파일링에 소요되는 월별 추정 비용입니다.
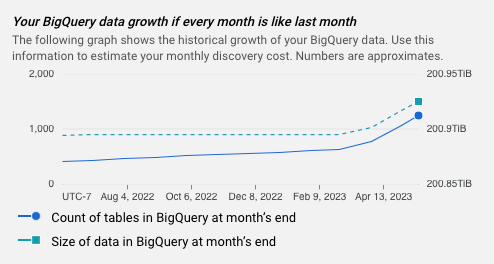
- 시간 경과에 따른 BigQuery의 증가를 보여주는 그래프
- 설정한 구성 세부정보입니다.
그래프 추정
각 추정치에는 BigQuery 데이터의 과거 증가 추세를 보여주는 그래프가 포함됩니다. 이 정보를 사용하여 월별 데이터 프로파일링 비용을 추정할 수 있습니다.
다음 단계
- 데이터 프로파일링 가격 책정 알아보기
- BigQuery 데이터의 데이터 프로필 자세히 알아보기
- 조직 또는 폴더의 데이터를 프로파일링하는 방법을 알아보세요.
- 단일 프로젝트의 데이터 프로파일링 방법 알아보기