Questo argomento descrive in dettaglio come creare un job di ispezione di Sensitive Data Protection e come pianificare i job di ispezione ricorrenti creando un trigger per i job. Per una procedura dettagliata rapida su come creare un nuovo trigger per un job utilizzando l'interfaccia utente di Sensitive Data Protection, consulta la guida rapida: creazione di un trigger per un job di Sensitive Data Protection.
Informazioni sui job di ispezione e sugli attivatori di job
Quando Sensitive Data Protection esegue una scansione di ispezione per identificare i dati sensibili, ogni scansione viene eseguita come job. La funzionalità Protezione dei dati sensibili crea ed esegue una risorsa di job ogni volta che le chiedi di ispezionare i tuoi Google Cloud repository di archiviazione, inclusi i bucket Cloud Storage, le tabelle BigQuery, i tipi di Datastore e i dati esterni.
Pianifica i job di scansione di ispezione di Sensitive Data Protection creando trigger per i job. Un trigger per i job automatizza la creazione di job di Sensitive Data Protection su base periodica e può essere eseguito anche su richiesta.
Per scoprire di più su job e trigger di job in Sensitive Data Protection, consulta la pagina concettuale Job e trigger di job.
Creare un nuovo job di ispezione
Per creare un nuovo job di ispezione di Sensitive Data Protection:
Console
Nella sezione Protezione dei dati sensibili della console Google Cloud, vai alla pagina Crea job o trigger.
Vai a Crea job o trigger di job
La pagina Crea job o trigger di job contiene le seguenti sezioni:
Scegli dati di input
Nome
Inserisci un nome per il job. Puoi utilizzare lettere, numeri e trattini. Assegnare un nome al job è facoltativo. Se non inserisci un nome, Sensitive Data Protection assignerà al job un identificatore numerico univoco.
Località
Dal menu Tipo di archiviazione, scegli il tipo di repository in cui sono archiviati i dati da eseguire la scansione:
- Cloud Storage: inserisci l'URL del bucket da eseguire la scansione o scegli Includi/escludi dal menu Tipo di località e poi fai clic su Sfoglia per accedere al bucket o alla sottocartella da eseguire la scansione. Seleziona la casella di controllo Esegui la scansione della cartella in modo ricorsivo per eseguire la scansione della directory specificata e di tutte le directory contenute. Lascialo selezionato per eseguire la scansione solo della directory specificata e non di directory più profonde.
- BigQuery: inserisci gli identificatori del progetto, del set di dati e della tabella da eseguire la scansione.
- Datastore: inserisci gli identificatori del progetto, dello spazio dei nomi (facoltativo) e del tipo che vuoi eseguire la scansione.
- Ibrida: puoi aggiungere etichette obbligatorie, etichette facoltative e opzioni per la gestione dei dati tabulari. Per ulteriori informazioni, consulta Tipi di metadati che puoi fornire.
Campionamento
Il campionamento è un modo facoltativo per risparmiare risorse in caso di volumi elevati di dati.
In Campionamento, puoi scegliere se eseguire la scansione di tutti i dati selezionati o eseguire il campionamento dei dati analizzando una determinata percentuale. Il campionamento funziona in modo diverso a seconda del tipo di repository di archiviazione sottoposto a scansione:
- Per BigQuery, puoi campionare un sottoinsieme delle righe selezionate totali, corrispondente alla percentuale di file da includere nella scansione.
- Per Cloud Storage, se un file supera le dimensioni specificate in Dimensione massima in byte da scansionare per file, la funzionalità Protezione dei dati sensibili lo scansiona fino a quella dimensione massima e poi passa al file successivo.
Per attivare il campionamento, scegli una delle seguenti opzioni dal primo menu:
- Inizia il campionamento dall'alto: Sensitive Data Protection avvia la scansione parziale all'inizio dei dati. Per BigQuery, la scansione inizia dalla prima riga. Per Cloud Storage, la scansione viene avviata all'inizio di ogni file e viene interrotta quando Sensitive Data Protection ha eseguito la scansione fino alla dimensione massima del file specificata.
- Inizia il campionamento da un punto casuale: Sensitive Data Protection avvia la scansione parziale in una posizione casuale all'interno dei dati. Per BigQuery, la scansione viene avviata in una riga casuale. Per Cloud Storage, questa impostazione si applica solo ai file che superano le dimensioni massime specificate. Sensitive Data Protection analizza i file di dimensioni inferiori a quelle massime nella loro interezza e i file di dimensioni superiori a quelle massime fino al massimo consentito.
Per eseguire una scansione parziale, devi anche scegliere la percentuale di dati da analizzare. Utilizza il cursore per impostare la percentuale.
Puoi anche restringere i file o i record da scansionare in base alla data. Per scoprire come, consulta Pianifica di seguito in questo argomento.
Configurazione avanzata
Quando crei un job per l'analisi dei bucket Cloud Storage o delle tabelle BigQuery, puoi restringere la ricerca specificando una configurazione avanzata. Nello specifico, puoi configurare:
- File (solo Cloud Storage): i tipi di file da cercare, tra cui file di testo, binari e immagini.
- Campi di identificazione (solo BigQuery): identificatori univoci delle righe all'interno della tabella.
- Per Cloud Storage, se un file supera le dimensioni specificate in Dimensione massima in byte da scansionare per file, la funzionalità Protezione dei dati sensibili lo scansiona fino a quella dimensione massima e poi passa al file successivo.
Per attivare il campionamento, scegli la percentuale di dati da analizzare. Utilizza il cursore per impostare la percentuale. Poi, scegli una delle seguenti opzioni dal primo menu:
- Inizia il campionamento dall'alto: Sensitive Data Protection avvia la scansione parziale all'inizio dei dati. Per BigQuery, la scansione inizia dalla prima riga. Per Cloud Storage, la scansione viene avviata all'inizio di ogni file e viene interrotta quando Sensitive Data Protection ha eseguito la scansione fino a qualsiasi dimensione massima del file specificata (vedi sopra).
- Inizia il campionamento da un punto casuale: Sensitive Data Protection avvia la scansione parziale in una posizione casuale all'interno dei dati. Per BigQuery, la scansione viene avviata in una riga casuale. Per Cloud Storage, questa impostazione si applica solo ai file che superano le dimensioni massime specificate. Sensitive Data Protection analizza i file di dimensioni inferiori a quelle massime nella loro interezza e i file di dimensioni superiori a quelle massime fino al massimo consentito.
File
Per i file archiviati in Cloud Storage, puoi specificare i tipi da includere nella scansione in File.
Puoi scegliere tra file binari, di testo, di immagini, CSV, TSV, Microsoft Word, Microsoft Excel,
Microsoft PowerPoint, PDF e Apache Avro. Per un elenco esaustivo delle estensioni di file che Sensitive Data Protection può analizzare nei bucket Cloud Storage, consulta FileType.
Se scegli Binario, Sensitive Data Protection esegue la scansione dei file di tipi non riconosciuti.
Campi identificativi
Per le tabelle in BigQuery, nel campo Campi di identificazione, puoi indicare a Sensitive Data Protection di includere i valori delle colonne della chiave principale della tabella nei risultati. In questo modo puoi ricollegare i risultati alle righe della tabella che li contengono.
Inserisci i nomi delle colonne che identificano in modo univoco ogni riga all'interno della tabella. Se necessario, utilizza la notazione a punti per specificare i campi nidificati. Puoi aggiungere tutti i campi che vuoi.
Devi anche attivare l'azione Salva in BigQuery per esportare i risultati in BigQuery. Quando i risultati vengono esportati in BigQuery, ogni risultato contiene i rispettivi valori dei campi di identificazione. Per ulteriori informazioni, consulta
identifyingFields.
Configura il rilevamento
Nella sezione Configura il rilevamento puoi specificare i tipi di dati sensibili che vuoi cercare. Il completamento di questa sezione è facoltativo. Se salti questa sezione, Sensitive Data Protection cercherà un insieme predefinito di infoType nei tuoi dati.
Modello
Se vuoi, puoi utilizzare un modello Sensitive Data Protection per riutilizzare le informazioni di configurazione specificate in precedenza.
Se hai già creato un modello da utilizzare, fai clic sul campo Nome modello per visualizzare un elenco dei modelli di ispezione esistenti. Scegli o digita il nome del modello che vuoi utilizzare.
Per ulteriori informazioni sulla creazione di modelli, vedi Creare modelli di ispezione di Sensitive Data Protection.
InfoType
I rilevatori di infoType trovano dati sensibili di un determinato tipo. Ad esempio, il rilevatore di infoType integrato di Sensitive Data Protection US_SOCIAL_SECURITY_NUMBER trova i numeri di previdenza sociale statunitensi. Oltre ai rilevatori di infoType integrati, puoi creare i tuoi rilevatori di infoType personalizzati.
In InfoType, scegli il rilevatore di infoType corrispondente a un tipo di dati che vuoi cercare. Ti consigliamo di non lasciare vuota questa sezione. In questo modo, Sensitive Data Protection eseguirà la scansione dei dati con un insieme predefinito di infoType, che potrebbe includere infoType non necessari. Per ulteriori informazioni su ciascun rilevatore, consulta la guida di riferimento per i rilevatori di infoType.
Per saperne di più su come gestire gli infoType integrati e personalizzati in questa sezione, consulta Gestire gli infoType tramite la console Google Cloud.
Set di regole di ispezione
I set di regole di ispezione ti consentono di personalizzare i rilevatori di infoType integrati e personalizzati utilizzando le regole di contesto. I due tipi di regole di ispezione sono:
- Regole di esclusione, che consentono di escludere risultati falsi o indesiderati.
- Regole hotword, che consentono di rilevare ulteriori risultati.
Per aggiungere una nuova regola, specifica prima uno o più rilevatori infoType integrati o personalizzati nella sezione InfoType. Questi sono i rilevatori di infoType che verranno modificati dai tuoi set di regole. Poi:
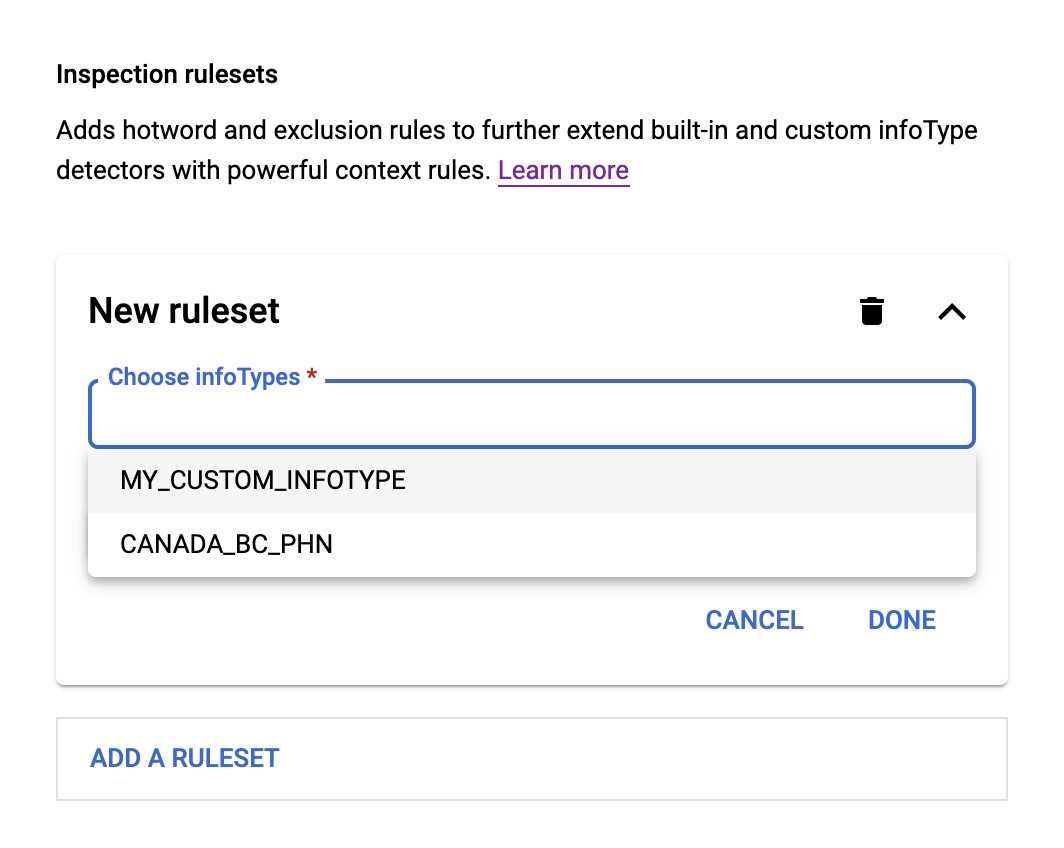
- Fai clic nel campo Scegli infoType. L'infoType o gli infoType specificati in precedenza vengono visualizzati sotto il campo in un menu, come mostrato di seguito:
- Scegli un tipo di informazioni dal menu e poi fai clic su Aggiungi regola. Viene visualizzato un menu con le due opzioni Regola hotword e Regola di esclusione.
Per le regole hotword, scegli Regole hotword. Poi:
- Nel campo Hotword, inserisci un'espressione regolare che Sensitive Data Protection deve cercare.
- Nel menu Prossimità hotword, scegli se l'hotword inserita deve essere trovata prima o dopo l'infoType scelto.
- In Distanza tra hotword e infoType, inserisci il numero approssimativo di caratteri tra la hotword e l'infoType scelto.
- In Aggiustamento del livello di confidenza, scegli se assegnare alle corrispondenze un livello di probabilità fisso o aumentare o diminuire il livello di probabilità predefinito di un determinato importo.
Per le regole di esclusione, scegli Regole di esclusione. Poi:
- Nel campo Escludi, inserisci un'espressione regolare (regex) che deve essere cercata da Sensitive Data Protection.
- Dal menu Tipo di corrispondenza, scegli una delle seguenti opzioni:
- Corrispondenza completa: il rilevamento deve corrispondere completamente alla regex.
- Corrispondenza parziale: una sottostringa del rilevamento può corrispondere alla regex.
- Corrispondenza inversa: il rilevamento non corrisponde all'espressione regolare.
Puoi aggiungere altre regole per hotword o esclusione e insiemi di regole per perfezionare ulteriormente i risultati della ricerca.
Soglia di confidenza
Ogni volta che Sensitive Data Protection rileva una potenziale corrispondenza per i dati sensibili, gli assegna un valore di probabilità su una scala da "Molto improbabile" a "Molto probabile". Quando imposti un valore di probabilità qui, indichi a Sensitive Data Protection di eseguire la corrispondenza solo sui dati corrispondenti a quel valore di probabilità o superiore.
Il valore predefinito "Possibile" è sufficiente per la maggior parte degli scopi. Se di solito ricevi corrispondenze troppo ampie, sposta il cursore verso l'alto. Se ricevi troppe poche corrispondenze, sposta il cursore verso il basso.
Al termine, fai clic su Continua.
Aggiungi azioni
Nel passaggio Aggiungi azioni, seleziona una o più azioni che vuoi che Sensitive Data Protection esegua al termine del job.
Puoi configurare le seguenti azioni:
Salva in BigQuery: salva i risultati del job Sensitive Data Protection in una tabella BigQuery. Prima di visualizzare o analizzare i risultati, assicurati che il job sia stato completato.
Ogni volta che viene eseguita una scansione, Sensitive Data Protection salva i risultati della scansione nella tabella BigQuery specificata. I risultati esportati contengono dettagli sulla posizione e sulla probabilità di corrispondenza di ogni risultato. Se vuoi che ogni risultato includa la stringa corrispondente al rilevatore di tipo di informazioni, attiva l'opzione Includi virgolette.
Se non specifichi un ID tabella, BigQuery assegna un nome predefinito a una nuova tabella la prima volta che viene eseguita la scansione. Se specifichi una tabella esistente, Sensitive Data Protection vi aggiunge i risultati della scansione.
Se non salvi i risultati in BigQuery, i risultati della scansione conterranno solo le statistiche sul numero e sugli infoType dei risultati.
Quando i dati vengono scritti in una tabella BigQuery, la fatturazione e l'utilizzo delle quote vengono applicati al progetto che contiene la tabella di destinazione.
Pubblica in Pub/Sub: pubblica una notifica contenente il nome del job Sensitive Data Protection come attributo in un canale Pub/Sub. Puoi specificare uno o più argomenti a cui inviare il messaggio di notifica. Assicurati che l'account di servizio Sensitive Data Protection che esegue il job di scansione abbia accesso in pubblicazione all'argomento.
Pubblica in Security Command Center: pubblica un riepilogo dei risultati del job in Security Command Center. Per ulteriori informazioni, consulta Inviare i risultati della scansione di Sensitive Data Protection a Security Command Center.
Pubblica in Dataplex: invia i risultati del job a Dataplex,il servizio di gestione dei metadati di Google Cloud.
Invia una notifica via email: invia un'email al termine del job. L'email viene inviata ai proprietari del progetto IAM e ai contatti tecnici fondamentali.
Pubblica su Cloud Monitoring: invia i risultati dell'ispezione a Cloud Monitoring in Observability di Google Cloud.
Crea una copia anonimizzata: anonimizza i risultati nei dati ispezionati e scrivi i contenuti anonimizzati in un nuovo file. Puoi quindi utilizzare la copia anonimizzata nei tuoi processi aziendali al posto dei dati che contengono informazioni sensibili. Per ulteriori informazioni, consulta Creare una copia anonimizzata dei dati di Cloud Storage utilizzando Sensitive Data Protection nella console Google Cloud.
Per ulteriori informazioni, vedi Azioni.
Al termine della selezione delle azioni, fai clic su Continua.
Rivedi
La sezione Rivedi contiene un riepilogo in formato JSON delle impostazioni del job che hai appena specificato.
Fai clic su Crea per creare il job (se non hai specificato una pianificazione) e per eseguire il job una volta. Viene visualizzata la pagina delle informazioni del job, che contiene lo stato e altre informazioni. Se il job è attualmente in esecuzione, puoi fare clic sul pulsante Annulla per interromperlo. Puoi anche eliminare il job facendo clic su Elimina.
Per tornare alla pagina principale di Sensitive Data Protection, fai clic sulla freccia Indietro nella console Google Cloud.
C#
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Go
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Java
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Node.js
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
PHP
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Python
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
REST
Un job è rappresentato nell'API DLP dalla risorsa
DlpJobs. Puoi creare un nuovo job utilizzando il metodo
projects.dlpJobs.create
della risorsa DlpJob.
Questo JSON di esempio può essere inviato in una richiesta POST all'endpoint REST per la protezione dei dati sensibili specificato. Questo esempio JSON mostra come creare un job in Sensitive Data Protection. Il job è una scansione di ispezione di Datastore.
Per provarlo rapidamente, puoi utilizzare l'API Explorer incorporato di seguito. Tieni presente che una richiesta andata a buon fine, anche se creata in API Explorer, creerà un job. Per informazioni generali sull'utilizzo di JSON per inviare richieste all'API DLP, consulta la guida introduttiva JSON.
Input JSON:
{
"inspectJob": {
"storageConfig": {
"bigQueryOptions": {
"tableReference": {
"projectId": "bigquery-public-data",
"datasetId": "san_francisco_sfpd_incidents",
"tableId": "sfpd_incidents"
}
},
"timespanConfig": {
"startTime": "2020-01-01T00:00:01Z",
"endTime": "2020-01-31T23:59:59Z",
"timestampField": {
"name": "timestamp"
}
}
},
"inspectConfig": {
"infoTypes": [
{
"name": "PERSON_NAME"
},
{
"name": "STREET_ADDRESS"
}
],
"excludeInfoTypes": false,
"includeQuote": true,
"minLikelihood": "LIKELY"
},
"actions": [
{
"saveFindings": {
"outputConfig": {
"table": {
"projectId": "[PROJECT-ID]",
"datasetId": "[DATASET-ID]"
}
}
}
}
]
}
}
Output JSON:
Il seguente output indica che il job è stato creato correttamente.
{
"name": "projects/[PROJECT-ID]/dlpJobs/[JOB-ID]",
"type": "INSPECT_JOB",
"state": "PENDING",
"inspectDetails": {
"requestedOptions": {
"snapshotInspectTemplate": {},
"jobConfig": {
"storageConfig": {
"bigQueryOptions": {
"tableReference": {
"projectId": "bigquery-public-data",
"datasetId": "san_francisco_sfpd_incidents",
"tableId": "sfpd_incidents"
}
},
"timespanConfig": {
"startTime": "2020-01-01T00:00:01Z",
"endTime": "2020-01-31T23:59:59Z",
"timestampField": {
"name": "timestamp"
}
}
},
"inspectConfig": {
"infoTypes": [
{
"name": "PERSON_NAME"
},
{
"name": "STREET_ADDRESS"
}
],
"minLikelihood": "LIKELY",
"limits": {},
"includeQuote": true
},
"actions": [
{
"saveFindings": {
"outputConfig": {
"table": {
"projectId": "[PROJECT-ID]",
"datasetId": "[DATASET-ID]",
"tableId": "[TABLE-ID]"
}
}
}
}
]
}
},
"result": {}
},
"createTime": "2020-07-10T07:26:33.643Z"
}
Crea un nuovo trigger di job
Per creare un nuovo trigger per un job di Sensitive Data Protection:
Console
Nella sezione Protezione dei dati sensibili della console Google Cloud, vai alla pagina Crea job o trigger.
Vai a Crea job o trigger di job
La pagina Crea job o trigger di job contiene le seguenti sezioni:
Scegli dati di input
Nome
Inserisci un nome per l'attivatore del job. Puoi utilizzare lettere, numeri e trattini. Assegnare un nome all'attivatore del job è facoltativo. Se non inserisci un nome, Sensitive Data Protection assegna all'attivatore del job un identificatore numerico univoco.
Località
Dal menu Tipo di archiviazione, scegli il tipo di repository in cui sono archiviati i dati da eseguire la scansione:
- Cloud Storage: inserisci l'URL del bucket da eseguire la scansione o scegli Includi/escludi dal menu Tipo di località e poi fai clic su Sfoglia per accedere al bucket o alla sottocartella da eseguire la scansione. Seleziona la casella di controllo Esegui la scansione della cartella in modo ricorsivo per eseguire la scansione della directory specificata e di tutte le directory contenute. Lascialo selezionato per eseguire la scansione solo della directory specificata e non di directory più profonde.
- BigQuery: inserisci gli identificatori del progetto, del set di dati e della tabella da eseguire la scansione.
- Datastore: inserisci gli identificatori del progetto, dello spazio dei nomi (facoltativo) e del tipo che vuoi eseguire la scansione.
Campionamento
Il campionamento è un modo facoltativo per risparmiare risorse in caso di volumi elevati di dati.
In Campionamento, puoi scegliere se eseguire la scansione di tutti i dati selezionati o eseguire il campionamento dei dati analizzando una determinata percentuale. Il campionamento funziona in modo diverso a seconda del tipo di repository di archiviazione sottoposto a scansione:
- Per BigQuery, puoi campionare un sottoinsieme delle righe selezionate totali, corrispondente alla percentuale di file da includere nella scansione.
- Per Cloud Storage, se un file supera le dimensioni specificate in Dimensione massima in byte da scansionare per file, la funzionalità Protezione dei dati sensibili lo scansiona fino a quella dimensione massima e poi passa al file successivo.
Per attivare il campionamento, scegli una delle seguenti opzioni dal primo menu:
- Inizia il campionamento dall'alto: Sensitive Data Protection avvia la scansione parziale all'inizio dei dati. Per BigQuery, la scansione inizia dalla prima riga. Per Cloud Storage, la scansione viene avviata all'inizio di ogni file e viene interrotta quando Sensitive Data Protection ha eseguito la scansione fino al limite di dimensioni massime del file specificato (vedi sopra).
- Inizia il campionamento da un punto casuale: Sensitive Data Protection avvia la scansione parziale in una posizione casuale all'interno dei dati. Per BigQuery, la scansione viene avviata in una riga casuale. Per Cloud Storage, questa impostazione si applica solo ai file che superano le dimensioni massime specificate. Sensitive Data Protection analizza i file di dimensioni inferiori a quelle massime nella loro interezza e i file di dimensioni superiori a quelle massime fino al massimo consentito.
Per eseguire una scansione parziale, devi anche scegliere la percentuale di dati da analizzare. Utilizza il cursore per impostare la percentuale.
Configurazione avanzata
Quando crei un attivatore di job per la scansione dei bucket Cloud Storage o delle tabelle BigQuery, puoi restringere la ricerca specificando una configurazione avanzata. Nello specifico, puoi configurare:
- File (solo Cloud Storage): i tipi di file da cercare, tra cui file di testo, binari e immagini.
- Campi di identificazione (solo BigQuery): identificatori univoci delle righe all'interno della tabella.
- Per Cloud Storage, se un file supera le dimensioni specificate in Dimensione massima in byte da scansionare per file, la funzionalità Protezione dei dati sensibili lo scansiona fino a quella dimensione massima e poi passa al file successivo.
Per attivare il campionamento, scegli la percentuale di dati da analizzare. Utilizza il cursore per impostare la percentuale. Poi, scegli una delle seguenti opzioni dal primo menu:
- Inizia il campionamento dall'alto: Sensitive Data Protection avvia la scansione parziale all'inizio dei dati. Per BigQuery, la scansione inizia dalla prima riga. Per Cloud Storage, la scansione viene avviata all'inizio di ogni file e viene interrotta quando Sensitive Data Protection ha eseguito la scansione fino a qualsiasi dimensione massima del file specificata (vedi sopra).
- Inizia il campionamento da un punto casuale: Sensitive Data Protection avvia la scansione parziale in una posizione casuale all'interno dei dati. Per BigQuery, la scansione viene avviata in una riga casuale. Per Cloud Storage, questa impostazione si applica solo ai file che superano le dimensioni massime specificate. Sensitive Data Protection analizza i file di dimensioni inferiori a quelle massime nella loro interezza e i file di dimensioni superiori a quelle massime fino al massimo consentito.
File
Per i file archiviati in Cloud Storage, puoi specificare i tipi da includere nella scansione in File.
Puoi scegliere tra file di tipo binario, di testo, di immagini, Microsoft Word, Microsoft Excel,
Microsoft PowerPoint, PDF e Apache Avro. Per un elenco esaustivo delle estensioni di file che Sensitive Data Protection può eseguire la scansione nei bucket Cloud Storage, consulta
FileType.
Se scegli Binario, Sensitive Data Protection esegue la scansione dei file di tipi non riconosciuti.
Campi identificativi
Per le tabelle in BigQuery, nel campo Campi di identificazione, puoi indicare a Sensitive Data Protection di includere i valori delle colonne della chiave principale della tabella nei risultati. In questo modo puoi ricollegare i risultati alle righe della tabella che li contengono.
Inserisci i nomi delle colonne che identificano in modo univoco ogni riga all'interno della tabella. Se necessario, utilizza la notazione a punti per specificare i campi nidificati. Puoi aggiungere tutti i campi che vuoi.
Devi anche attivare l'azione Salva in BigQuery per esportare i risultati in BigQuery. Quando i risultati vengono esportati in BigQuery, ogni risultato contiene i rispettivi valori dei campi di identificazione. Per ulteriori informazioni, consulta
identifyingFields.
Configura il rilevamento
Nella sezione Configura il rilevamento puoi specificare i tipi di dati sensibili che vuoi cercare. Il completamento di questa sezione è facoltativo. Se salti questa sezione, Sensitive Data Protection cercherà un insieme predefinito di infoType nei tuoi dati.
Modello
Se vuoi, puoi utilizzare un modello Sensitive Data Protection per riutilizzare le informazioni di configurazione specificate in precedenza.
Se hai già creato un modello da utilizzare, fai clic sul campo Nome modello per visualizzare un elenco dei modelli di ispezione esistenti. Scegli o digita il nome del modello che vuoi utilizzare.
Per ulteriori informazioni sulla creazione di modelli, vedi Creare modelli di ispezione di Sensitive Data Protection.
InfoType
I rilevatori di infoType trovano dati sensibili di un determinato tipo. Ad esempio, il rilevatore di infoType integrato di Sensitive Data Protection US_SOCIAL_SECURITY_NUMBER trova i numeri di previdenza sociale statunitensi. Oltre ai rilevatori di tipo di informazione integrati, puoi creare i tuoi rilevatori di tipo di informazione personalizzati.
In InfoType, scegli il rilevatore di infoType corrispondente a un tipo di dati che vuoi cercare. Puoi anche lasciare vuoto questo campo per eseguire la ricerca di tutti gli infoType predefiniti. Ulteriori informazioni su ciascun rilevatore sono disponibili nella guida di riferimento per i rilevatori di infoType.
Puoi anche aggiungere rilevatori di infoType personalizzati nella sezione InfoType personalizzati e personalizzare i rilevatori di infoType sia incorporati che personalizzati nella sezione Regole di ispezione.
InfoType personalizzati
Set di regole di ispezione
I set di regole di ispezione ti consentono di personalizzare i rilevatori di infoType integrati e personalizzati utilizzando le regole di contesto. I due tipi di regole di ispezione sono:
- Regole di esclusione, che consentono di escludere risultati falsi o indesiderati.
- Regole hotword, che consentono di rilevare ulteriori risultati.
Per aggiungere una nuova regola, specifica prima uno o più rilevatori infoType integrati o personalizzati nella sezione InfoType. Questi sono i rilevatori di infoType che verranno modificati dai tuoi set di regole. Poi:
- Fai clic nel campo Scegli infoType. L'infoType o gli infoType specificati in precedenza vengono visualizzati sotto il campo in un menu, come mostrato di seguito:
- Scegli un tipo di informazioni dal menu e poi fai clic su Aggiungi regola. Viene visualizzato un menu con le due opzioni Regola hotword e Regola di esclusione.
Per le regole hotword, scegli Regole hotword. Poi:
- Nel campo Hotword, inserisci un'espressione regolare che Sensitive Data Protection deve cercare.
- Nel menu Prossimità hotword, scegli se l'hotword inserita deve essere trovata prima o dopo l'infoType scelto.
- In Distanza tra hotword e infoType, inserisci il numero approssimativo di caratteri tra la hotword e l'infoType scelto.
- In Aggiustamento del livello di confidenza, scegli se assegnare alle corrispondenze un livello di probabilità fisso o aumentare o diminuire il livello di probabilità predefinito di un determinato importo.
Per le regole di esclusione, scegli Regole di esclusione. Poi:
- Nel campo Escludi, inserisci un'espressione regolare (regex) che deve essere cercata da Sensitive Data Protection.
- Dal menu Tipo di corrispondenza, scegli una delle seguenti opzioni:
- Corrispondenza completa: il rilevamento deve corrispondere completamente alla regex.
- Corrispondenza parziale: una sottostringa del rilevamento può corrispondere alla regex.
- Corrispondenza inversa: il rilevamento non corrisponde all'espressione regolare.
Puoi aggiungere altre regole per hotword o esclusione e insiemi di regole per perfezionare ulteriormente i risultati della ricerca.
Soglia di confidenza
Ogni volta che Sensitive Data Protection rileva una potenziale corrispondenza per i dati sensibili, gli assegna un valore di probabilità su una scala da "Molto improbabile" a "Molto probabile". Quando imposti un valore di probabilità qui, indichi a Sensitive Data Protection di eseguire la corrispondenza solo sui dati corrispondenti a quel valore di probabilità o superiore.
Il valore predefinito "Possibile" è sufficiente per la maggior parte degli scopi. Se di solito ricevi corrispondenze troppo ampie, sposta il cursore verso l'alto. Se ricevi troppe poche corrispondenze, sposta il cursore verso il basso.
Al termine, fai clic su Continua.
Aggiungi azioni
Nel passaggio Aggiungi azioni, seleziona una o più azioni che vuoi che Sensitive Data Protection esegua al termine del job.
Puoi configurare le seguenti azioni:
Salva in BigQuery: salva i risultati del job Sensitive Data Protection in una tabella BigQuery. Prima di visualizzare o analizzare i risultati, assicurati che il job sia stato completato.
Ogni volta che viene eseguita una scansione, Sensitive Data Protection salva i risultati della scansione nella tabella BigQuery specificata. I risultati esportati contengono dettagli sulla posizione e sulla probabilità di corrispondenza di ogni risultato. Se vuoi che ogni risultato includa la stringa corrispondente al rilevatore di tipo di informazioni, attiva l'opzione Includi virgolette.
Se non specifichi un ID tabella, BigQuery assegna un nome predefinito a una nuova tabella la prima volta che viene eseguita la scansione. Se specifichi una tabella esistente, Sensitive Data Protection vi aggiunge i risultati della scansione.
Se non salvi i risultati in BigQuery, i risultati della scansione conterranno solo le statistiche sul numero e sugli infoType dei risultati.
Quando i dati vengono scritti in una tabella BigQuery, la fatturazione e l'utilizzo delle quote vengono applicati al progetto che contiene la tabella di destinazione.
Pubblica in Pub/Sub: pubblica una notifica contenente il nome del job Sensitive Data Protection come attributo in un canale Pub/Sub. Puoi specificare uno o più argomenti a cui inviare il messaggio di notifica. Assicurati che l'account di servizio Sensitive Data Protection che esegue il job di scansione abbia accesso in pubblicazione all'argomento.
Pubblica in Security Command Center: pubblica un riepilogo dei risultati del job in Security Command Center. Per ulteriori informazioni, consulta Inviare i risultati della scansione di Sensitive Data Protection a Security Command Center.
Pubblica in Dataplex: invia i risultati del job a Dataplex,il servizio di gestione dei metadati di Google Cloud.
Invia una notifica via email: invia un'email al termine del job. L'email viene inviata ai proprietari del progetto IAM e ai contatti tecnici fondamentali.
Pubblica su Cloud Monitoring: invia i risultati dell'ispezione a Cloud Monitoring in Observability di Google Cloud.
Crea una copia anonimizzata: anonimizza i risultati nei dati ispezionati e scrivi i contenuti anonimizzati in un nuovo file. Puoi quindi utilizzare la copia anonimizzata nei tuoi processi aziendali al posto dei dati che contengono informazioni sensibili. Per ulteriori informazioni, consulta Creare una copia anonimizzata dei dati di Cloud Storage utilizzando Sensitive Data Protection nella console Google Cloud.
Per ulteriori informazioni, vedi Azioni.
Al termine della selezione delle azioni, fai clic su Continua.
Pianificazione
Nella sezione Pianifica, puoi eseguire due operazioni:
- Specifica intervallo di tempo: questa opzione limita i file o le righe da analizzare in base alla data. Fai clic su Ora di inizio per specificare il timestamp del file più antico da includere. Lascia vuoto questo valore per specificare tutti i file. Fai clic su Ora di fine per specificare il timestamp del file più recente da includere. Lascia vuoto questo valore per specificare nessun limite superiore per il timestamp.
Crea un trigger per eseguire il job su base periodica: questa opzione trasforma il job in un trigger che viene eseguito in base a una pianificazione periodica. Se non specifichi una pianificazione, crei un singolo job che inizia immediatamente e viene eseguito una volta. Per creare un attivatore di job che venga eseguito regolarmente, devi impostare questa opzione.
Il valore predefinito è anche il valore minimo: 24 ore. Il valore massimo è 60 giorni.
Se vuoi che la funzionalità Protezione dei dati sensibili esamini solo i nuovi file o le nuove righe, seleziona Limita le scansioni solo ai nuovi contenuti. Per l'ispezione di BigQuery, nell'analisi vengono incluse solo le righe risalenti ad almeno tre ore prima. Consulta il problema noto relativo a questa operazione.
Rivedi
La sezione Rivedi contiene un riepilogo in formato JSON delle impostazioni del job che hai appena specificato.
Fai clic su Crea per creare l'attivatore di job (se hai specificato una pianificazione). Viene visualizzata la pagina delle informazioni dell'attivatore del job, che contiene lo stato e altre informazioni. Se il job è attualmente in esecuzione, puoi fare clic sul pulsante Annulla per interromperlo. Puoi anche eliminare l'attivatore del job facendo clic su Elimina.
Per tornare alla pagina principale di Sensitive Data Protection, fai clic sulla freccia Indietro nella console Google Cloud.
C#
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Go
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Java
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Node.js
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
PHP
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Python
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
REST
Un attivatore di job è rappresentato nell'API DLP dalla risorsa
JobTrigger. Puoi creare un nuovo attivatore di job utilizzando il metodo
projects.jobTriggers.create
della risorsa JobTrigger.
Questo JSON di esempio può essere inviato in una richiesta POST all'endpoint REST per la protezione dei dati sensibili specificato. Questo esempio JSON mostra come creare un attivatore di job in Protezione dei dati sensibili. Il job avviato da questo trigger è una scansione di ispezione di Datastore. L'attivatore di job creato viene eseguito ogni 86.400 secondi (o 24 ore).
Per provarlo rapidamente, puoi utilizzare l'API Explorer incorporato di seguito. Tieni presente che una richiesta andata a buon fine, anche se creata in API Explorer, creerà un nuovo attivatore di job pianificato. Per informazioni generali sull'utilizzo di JSON per inviare richieste all'API DLP, consulta la guida introduttiva JSON.
Input JSON:
{
"jobTrigger":{
"displayName":"JobTrigger1",
"description":"Starts an inspection of a Datastore kind",
"triggers":[
{
"schedule":{
"recurrencePeriodDuration":"86400s"
}
}
],
"status":"HEALTHY",
"inspectJob":{
"storageConfig":{
"datastoreOptions":{
"kind":{
"name":"Example-Kind"
},
"partitionId":{
"projectId":"[PROJECT_ID]",
"namespaceId":"[NAMESPACE_ID]"
}
}
},
"inspectConfig":{
"infoTypes":[
{
"name":"PHONE_NUMBER"
}
],
"excludeInfoTypes":false,
"includeQuote":true,
"minLikelihood":"LIKELY"
},
"actions":[
{
"saveFindings":{
"outputConfig":{
"table":{
"projectId":"[PROJECT_ID]",
"datasetId":"[BIGQUERY_DATASET_NAME]",
"tableId":"[BIGQUERY_TABLE_NAME]"
}
}
}
}
]
}
}
}
Output JSON:
Il seguente output indica che l'attivatore del job è stato creato correttamente.
{
"name":"projects/[PROJECT_ID]/jobTriggers/[JOB_TRIGGER_NAME]",
"displayName":"JobTrigger1",
"description":"Starts an inspection of a Datastore kind",
"inspectJob":{
"storageConfig":{
"datastoreOptions":{
"partitionId":{
"projectId":"[PROJECT_ID]",
"namespaceId":"[NAMESPACE_ID]"
},
"kind":{
"name":"Example-Kind"
}
}
},
"inspectConfig":{
"infoTypes":[
{
"name":"PHONE_NUMBER"
}
],
"minLikelihood":"LIKELY",
"limits":{
},
"includeQuote":true
},
"actions":[
{
"saveFindings":{
"outputConfig":{
"table":{
"projectId":"[PROJECT_ID]",
"datasetId":"[BIGQUERY_DATASET_NAME]",
"tableId":"[BIGQUERY_TABLE_NAME]"
}
}
}
}
]
},
"triggers":[
{
"schedule":{
"recurrencePeriodDuration":"86400s"
}
}
],
"createTime":"2018-11-30T01:52:41.171857Z",
"updateTime":"2018-11-30T01:52:41.171857Z",
"status":"HEALTHY"
}
Elenca tutti i job
Per elencare tutti i job per il progetto corrente:
Console
Nella console Google Cloud, vai alla pagina Protezione dei dati sensibili.
Fai clic sulla scheda Ispezione, quindi sulla sottoscheda Ispeziona job.
La console mostra un elenco di tutti i job per il progetto corrente, inclusi gli identificatori, lo stato, la data di creazione e la data di fine. Puoi ottenere maggiori informazioni su qualsiasi job, incluso un riepilogo dei risultati, facendo clic sul relativo identificatore.
C#
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Go
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Java
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Node.js
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
PHP
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Python
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
REST
La risorsa DlpJob ha un metodo
projects.dlpJobs.list
con il quale puoi elencare tutti i job.
Per elencare tutti i job attualmente definiti nel progetto, invia una richiesta GET all'endpoint dlpJobs, come mostrato di seguito:
URL:
GET https://dlp.googleapis.com/v2/projects/[PROJECT-ID]/dlpJobs?key={YOUR_API_KEY}
Il seguente output JSON elenca uno dei job restituiti. Tieni presente che la struttura del job rispecchia quella della risorsa DlpJob.
Output JSON:
{
"jobs":[
{
"name":"projects/[PROJECT-ID]/dlpJobs/i-5270277269264714623",
"type":"INSPECT_JOB",
"state":"DONE",
"inspectDetails":{
"requestedOptions":{
"snapshotInspectTemplate":{
},
"jobConfig":{
"storageConfig":{
"cloudStorageOptions":{
"fileSet":{
"url":"[CLOUD-STORAGE-URL]"
},
"fileTypes":[
"FILE_TYPE_UNSPECIFIED"
],
"filesLimitPercent":100
},
"timespanConfig":{
"startTime":"2019-09-08T22:43:16.623Z",
"enableAutoPopulationOfTimespanConfig":true
}
},
"inspectConfig":{
"infoTypes":[
{
"name":"US_SOCIAL_SECURITY_NUMBER"
},
{
"name":"CANADA_SOCIAL_INSURANCE_NUMBER"
}
],
"minLikelihood":"LIKELY",
"limits":{
},
"includeQuote":true
},
"actions":[
{
"saveFindings":{
"outputConfig":{
"table":{
"projectId":"[PROJECT-ID]",
"datasetId":"[DATASET-ID]",
"tableId":"[TABLE-ID]"
}
}
}
}
]
}
},
"result":{
...
}
},
"createTime":"2019-09-09T22:43:16.918Z",
"startTime":"2019-09-09T22:43:16.918Z",
"endTime":"2019-09-09T22:43:53.091Z",
"jobTriggerName":"projects/[PROJECT-ID]/jobTriggers/sample-trigger2"
},
...
Per provarlo rapidamente, puoi utilizzare l'API Explorer incorporato di seguito. Per informazioni generali sull'utilizzo di JSON per inviare richieste all'API DLP, consulta la guida introduttiva JSON.
Elenco di tutti gli attivatori dei job
Per elencare tutti gli attivatori dei job per il progetto corrente:
Console
Nella console Google Cloud, vai alla pagina Protezione dei dati sensibili.
Vai a Sensitive Data Protection
Nella scheda Ispezione, nella sottoscheda Attivatori job, la console mostra un elenco di tutti gli attivatori job per il progetto corrente.
C#
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Go
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Java
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Node.js
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
PHP
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Python
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
REST
La risorsa JobTrigger ha un metodo
projects.jobTriggers.list
con il quale puoi elencare tutti gli attivatori dei job.
Per elencare tutti gli attivatori dei job attualmente definiti nel progetto, invia una richiesta GET all'endpoint jobTriggers, come mostrato di seguito:
URL:
GET https://dlp.googleapis.com/v2/projects/[PROJECT-ID]/jobTriggers?key={YOUR_API_KEY}
Il seguente output JSON elenca l'attivatore del job che abbiamo creato nella sezione precedente. Tieni presente che la struttura dell'attivatore del job rispecchia quella della risorsa JobTrigger.
Output JSON:
{
"jobTriggers":[
{
"name":"projects/[PROJECT_ID]/jobTriggers/[JOB_TRIGGER_NAME]",
"displayName":"JobTrigger1",
"description":"Starts an inspection of a Datastore kind",
"inspectJob":{
"storageConfig":{
"datastoreOptions":{
"partitionId":{
"projectId":"[PROJECT_ID]",
"namespaceId":"[NAMESPACE_ID]"
},
"kind":{
"name":"Example-Kind"
}
}
},
"inspectConfig":{
"infoTypes":[
{
"name":"PHONE_NUMBER"
}
],
"minLikelihood":"LIKELY",
"limits":{
},
"includeQuote":true
},
"actions":[
{
"saveFindings":{
"outputConfig":{
"table":{
"projectId":"[PROJECT_ID]",
"datasetId":"[BIGQUERY_DATASET_NAME]",
"tableId":"[BIGQUERY_TABLE_NAME]"
}
}
}
}
]
},
"triggers":[
{
"schedule":{
"recurrencePeriodDuration":"86400s"
}
}
],
"createTime":"2018-11-30T01:52:41.171857Z",
"updateTime":"2018-11-30T01:52:41.171857Z",
"status":"HEALTHY"
},
...
],
"nextPageToken":"KkwKCQjivJ2UpPreAgo_Kj1wcm9qZWN0cy92ZWx2ZXR5LXN0dWR5LTE5NjEwMS9qb2JUcmlnZ2Vycy8xNTA5NzEyOTczMDI0MDc1NzY0"
}
Per provarlo rapidamente, puoi utilizzare l'API Explorer incorporato di seguito. Per informazioni generali sull'utilizzo di JSON per inviare richieste all'API DLP, consulta la guida introduttiva JSON.
Elimina un job
Per eliminare un job dal progetto, inclusi i relativi risultati: I risultati salvati esternamente (ad esempio in BigQuery) rimangono invariati da questa operazione.
Console
Nella console Google Cloud, vai alla pagina Protezione dei dati sensibili.
Fai clic sulla scheda Ispezione, quindi sulla sottoscheda Ispeziona job. La console Google Cloud mostra un elenco di tutti i job per il progetto corrente.
Nella colonna Azioni relativa all'attivatore di job da eliminare, fai clic sul menu Altre azioni (visualizzato come tre puntini disposti in verticale) e poi su Elimina.
In alternativa, nell'elenco dei job, fai clic sull'identificatore del job che vuoi eliminare. Nella pagina dei dettagli dell'offerta di lavoro, fai clic su Elimina.
C#
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Go
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Java
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Node.js
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
PHP
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Python
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
REST
Per eliminare un job dal progetto corrente, invia una richiesta DELETE all'endpoint dlpJobs, come mostrato di seguito. Sostituisci il campo [JOB-IDENTIFIER] con l' identificativo del job, che inizia con i-.
URL:
DELETE https://dlp.googleapis.com/v2/projects/[PROJECT-ID]/dlpJobs/[JOB-IDENTIFIER]?key={YOUR_API_KEY}
Se la richiesta è andata a buon fine, l'API DLP restituisce una risposta di conferma. Per verificare che il job sia stato eliminato correttamente, elenca tutti i job.
Per provarlo rapidamente, puoi utilizzare l'API Explorer incorporato di seguito. Per informazioni generali sull'utilizzo di JSON per inviare richieste all'API DLP, consulta la guida introduttiva JSON.
Eliminare un trigger di job
Console
Nella console Google Cloud, vai alla pagina Protezione dei dati sensibili.
Vai a Sensitive Data Protection
Nella scheda Ispezione, nella sottoscheda Attivatori job, la console mostra un elenco di tutti gli attivatori job per il progetto corrente.
Nella colonna Azioni relativa all'attivatore di job da eliminare, fai clic sul menu Altre azioni (visualizzato come tre puntini disposti in verticale) e poi su Elimina.
In alternativa, nell'elenco degli attivatori dei job, fai clic sul nome dell'attivatore del job che vuoi eliminare. Nella pagina dei dettagli dell'attivatore del job, fai clic su Elimina.
C#
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Go
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Java
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Node.js
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
PHP
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Python
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
REST
Per eliminare un attivatore di job dal progetto corrente, invia una richiesta DELETE all'endpoint jobTriggers, come mostrato di seguito. Sostituisci il campo [JOB-TRIGGER-NAME] con il nome
dell'attivatore del job.
URL:
DELETE https://dlp.googleapis.com/v2/projects/[PROJECT-ID]/jobTriggers/[JOB-TRIGGER-NAME]?key={YOUR_API_KEY}
Se la richiesta è andata a buon fine, l'API DLP restituisce una risposta di conferma. Per verificare che l'attivatore del job sia stato eliminato correttamente, elenca tutti gli attivatori del job.
Per provarlo rapidamente, puoi utilizzare l'API Explorer incorporato di seguito. Per informazioni generali sull'utilizzo di JSON per inviare richieste all'API DLP, consulta la guida introduttiva JSON.
Recupero di un job
Per ottenere un job dal tuo progetto, che include i relativi risultati: Tutti i risultati salvati esternamente (ad esempio in BigQuery) rimangono invariati da questa operazione.
C#
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Go
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Java
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Node.js
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
PHP
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Python
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
REST
Per recuperare un job dal progetto corrente, invia una richiesta GET all'endpoint dlpJobs, come mostrato di seguito. Sostituisci il campo [JOB-IDENTIFIER] con l' identificativo del job, che inizia con i-.
URL:
GET https://dlp.googleapis.com/v2/projects/[PROJECT-ID]/dlpJobs/[JOB-IDENTIFIER]?key={YOUR_API_KEY}
Se la richiesta è andata a buon fine, l'API DLP restituisce una risposta di conferma.
Per provarlo rapidamente, puoi utilizzare l'API Explorer incorporato di seguito. Per informazioni generali sull'utilizzo di JSON per inviare richieste all'API DLP, consulta la guida introduttiva JSON.
Forzare un'esecuzione immediata di un attivatore di job
Dopo aver creato un attivatore di job, puoi forzare un'esecuzione immediata dell'attivatore per i test attivandolo. Per farlo, esegui il seguente comando:
curl --request POST \
-H "Content-Type: application/json" \
-H "Accept: application/json" \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "X-Goog-User-Project: PROJECT_ID" \
'https://dlp.googleapis.com/v2/JOB_TRIGGER_NAME:activate'
Sostituisci quanto segue:
- PROJECT_ID: l'ID del Google Cloud progetto a cui addebitare gli oneri di accesso associati alla richiesta.
- JOB_TRIGGER_NAME: il nome completo della risorsa dell'attivatore del job, ad esempio
projects/my-project/locations/global/jobTriggers/123456789.
Aggiornare un trigger di job esistente
Oltre a creare, elencare ed eliminare gli attivatori di job, puoi anche aggiornare un attivatore di job esistente. Per modificare la configurazione di un attivatore job esistente:
Console
Nella console Google Cloud, vai alla pagina Protezione dei dati sensibili.
Fai clic sulla scheda Ispezione e poi sulla sottoscheda Attivatori job.
La console mostra un elenco di tutti gli attivatori dei job per il progetto corrente.
Nella colonna Azioni relativa all'attivatore del job da eliminare, fai clic su Altro more_vert e poi su Visualizza dettagli.
Nella pagina dei dettagli dell'attivatore del job, fai clic su Modifica.
Nella pagina Modifica attivatore, puoi modificare la posizione dei dati di input, i dettagli di rilevamento come modelli, infoType o probabilità, eventuali azioni post-scan e la pianificazione dell'attivatore del job. Al termine, fai clic su Salva.
C#
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Go
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Java
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Node.js
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
PHP
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Python
Per scoprire come installare e utilizzare la libreria client per Sensitive Data Protection, consulta Librerie client di Sensitive Data Protection.
Per autenticarti a Sensitive Data Protection, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
REST
Utilizza il metodo
projects.jobTriggers.patch
per inviare nuovi valori JobTrigger all'API DLP
per aggiornarli in un attivatore del job specificato.
Ad esempio, considera il seguente semplice attivatore di job. Questo JSON rappresenta l'attivatore del job ed è stato restituito dopo l'invio di una richiesta GET all'endpoint di attivazione del job del progetto corrente.
Output JSON:
{
"name":"projects/[PROJECT_ID]/jobTriggers/[JOB_TRIGGER_NAME]",
"inspectJob":{
"storageConfig":{
"cloudStorageOptions":{
"fileSet":{
"url":"gs://dlptesting/*"
},
"fileTypes":[
"FILE_TYPE_UNSPECIFIED"
],
"filesLimitPercent":100
},
"timespanConfig":{
"enableAutoPopulationOfTimespanConfig":true
}
},
"inspectConfig":{
"infoTypes":[
{
"name":"US_SOCIAL_SECURITY_NUMBER"
}
],
"minLikelihood":"POSSIBLE",
"limits":{
}
},
"actions":[
{
"jobNotificationEmails":{
}
}
]
},
"triggers":[
{
"schedule":{
"recurrencePeriodDuration":"86400s"
}
}
],
"createTime":"2019-03-06T21:19:45.774841Z",
"updateTime":"2019-03-06T21:19:45.774841Z",
"status":"HEALTHY"
}
Il seguente JSON, se inviato con una richiesta PATCH all'endpoint specificato,
aggiorna l'attivatore del job specificato con un nuovo tipo di informazioni da cercare, nonché una nuova
probabilità minima. Tieni presente che devi specificare anche l'attributo updateMask e che il relativo valore sia nel formato FieldMask.
Input JSON:
PATCH https://dlp.googleapis.com/v2/projects/[PROJECT_ID]/jobTriggers/[JOB_TRIGGER_NAME]?key={YOUR_API_KEY}
{
"jobTrigger":{
"inspectJob":{
"inspectConfig":{
"infoTypes":[
{
"name":"US_INDIVIDUAL_TAXPAYER_IDENTIFICATION_NUMBER"
}
],
"minLikelihood":"LIKELY"
}
}
},
"updateMask":"inspectJob(inspectConfig(infoTypes,minLikelihood))"
}
Dopo aver inviato questo JSON all'URL specificato, viene restituito quanto segue, che rappresenta l'attivatore del job aggiornato. Tieni presente che i valori originali di infoType e likelihood sono stati sostituiti dai nuovi valori.
Output JSON:
{
"name":"projects/[PROJECT_ID]/jobTriggers/[JOB_TRIGGER_NAME]",
"inspectJob":{
"storageConfig":{
"cloudStorageOptions":{
"fileSet":{
"url":"gs://dlptesting/*"
},
"fileTypes":[
"FILE_TYPE_UNSPECIFIED"
],
"filesLimitPercent":100
},
"timespanConfig":{
"enableAutoPopulationOfTimespanConfig":true
}
},
"inspectConfig":{
"infoTypes":[
{
"name":"US_INDIVIDUAL_TAXPAYER_IDENTIFICATION_NUMBER"
}
],
"minLikelihood":"LIKELY",
"limits":{
}
},
"actions":[
{
"jobNotificationEmails":{
}
}
]
},
"triggers":[
{
"schedule":{
"recurrencePeriodDuration":"86400s"
}
}
],
"createTime":"2019-03-06T21:19:45.774841Z",
"updateTime":"2019-03-06T21:27:01.650183Z",
"lastRunTime":"1970-01-01T00:00:00Z",
"status":"HEALTHY"
}
Per provarlo rapidamente, puoi utilizzare l'API Explorer incorporato di seguito. Per informazioni generali sull'utilizzo di JSON per inviare richieste all'API DLP, consulta la guida introduttiva JSON.
Latenza del job
Non sono garantiti obiettivi del livello di servizio (SLO) per i job e gli attivatori dei job. La latenza è influenzata da diversi fattori, tra cui la quantità di dati da analizzare, il repository di archiviazione sottoposto a scansione, il tipo e il numero di InfoType che stai cercando, la regione in cui viene elaborato il job e le risorse di calcolo disponibili in quella regione. Pertanto, la latenza dei job di ispezione non può essere determinata in anticipo.
Per contribuire a ridurre la latenza dei job, puoi provare a:
- Se il campionamento è disponibile per il tuo job o trigger di job, attivalo.
Evita di attivare infoType non necessari. Sebbene i seguenti siano utili in determinati scenari, questi infoType possono far funzionare le richieste molto più lentamente rispetto a quelle che non li includono:
PERSON_NAMEFEMALE_NAMEMALE_NAMEFIRST_NAMELAST_NAMEDATE_OF_BIRTHLOCATIONSTREET_ADDRESSORGANIZATION_NAME
Specifica sempre gli infoType in modo esplicito. Non utilizzare un elenco infoTypes vuoto.
Se possibile, utilizza una regione di elaborazione diversa.
Se dopo aver provato queste tecniche i problemi di latenza con i job persistono,
considera la possibilità di utilizzare
richieste
content.inspect o
content.deidentify
invece di job. Questi metodi sono coperti dall'accordo sul livello del servizio. Per ulteriori informazioni, consulta l'Accordo sul livello del servizio di Sensitive Data Protection.
Limita le scansioni ai nuovi contenuti
Puoi configurare l'attivatore del job in modo che imposti automaticamente la data dell'intervallo di tempo per i file archiviati in Cloud Storage o BigQuery. Quando imposti l'oggetto
TimespanConfig
per il completamento automatico, Sensitive Data Protection esegue la scansione solo dei dati
aggiunti o modificati dall'ultima esecuzione dell'attivatore:
...
timespan_config {
enable_auto_population_of_timespan_config: true
}
...
Per l'ispezione di BigQuery, nell'analisi vengono incluse solo le righe risalenti ad almeno tre ore prima. Consulta il problema noto relativo a questa operazione.
Attivare i job al caricamento dei file
Oltre al supporto degli attivatori dei job, che è integrato in Sensitive Data Protection,Google Cloud offre anche una serie di altri componenti che puoi utilizzare per integrare o attivare i job di Sensitive Data Protection. Ad esempio, puoi utilizzare le funzioni Cloud Run per attivare una scansione di protezione dei dati sensibili ogni volta che un file viene caricato su Cloud Storage.
Per informazioni su come configurare questa operazione, consulta Automatizzare la classificazione dei dati caricati su Cloud Storage.
Job riusciti senza dati ispezionati
Un job può essere completato correttamente anche se non è stata eseguita la scansione di alcun dato. I seguenti scenari di esempio possono causare questo problema:
- Il job è configurato per ispezionare un asset dati specifico, ad esempio un file, che esiste, ma è vuoto.
- Il job è configurato per ispezionare una risorsa dati che non esiste o che non esiste più.
- Il job è configurato per ispezionare un bucket Cloud Storage vuoto.
- Il job è configurato per ispezionare un bucket e la ricerca ricorsiva è disattivata. A livello superiore, il bucket contiene solo cartelle che, a loro volta, contengono i file.
- Il job è configurato per ispezionare solo un tipo di file specifico in un bucket, ma il bucket non contiene file di quel tipo.
- Il job è configurato per ispezionare solo i nuovi contenuti, ma non sono stati apportati aggiornamenti dall'ultima esecuzione del job.
Nella console Google Cloud, nella pagina Dettagli job, il campo Byte analizzati
specifica la quantità di dati ispezionati dal job. Nell'API DLP, il campo processedBytes specifica la quantità di dati ispezionati.
Passaggi successivi
- Scopri di più sulla creazione di una copia anonimizzata dei dati nello stoccaggio.