This topic describes in detail how to create a Sensitive Data Protection inspection job, and how to schedule recurring inspection jobs by creating a job trigger. For a quick walkthrough of how to create a new job trigger using the Sensitive Data Protection UI, see Quickstart: Creating a Sensitive Data Protection job trigger.
About inspection jobs and job triggers
When Sensitive Data Protection performs an inspection scan to identify sensitive data, each scan runs as a job. Sensitive Data Protection creates and runs a job resource whenever you tell it to inspect your Google Cloud storage repositories, including Cloud Storage buckets, BigQuery tables, Datastore kinds, and external data.
You schedule Sensitive Data Protection inspection scan jobs by creating job triggers. A job trigger automates the creation of Sensitive Data Protection jobs on a periodic basis, and can also be run on demand.
To learn more about jobs and job triggers in Sensitive Data Protection, see the Jobs and job triggers conceptual page.
Create a new inspection job
To create a new Sensitive Data Protection inspection job:
Console
In the Sensitive Data Protection section of the Google Cloud console, go to the Create job or job trigger page.
Go to Create job or job trigger
The Create job or job trigger page contains the following sections:
Choose input data
Name
Enter a name for the job. You can use letters, numbers, and hyphens. Naming your job is optional. If you don't enter a name, Sensitive Data Protection will give the job a unique number identifier.
Location
From the Storage type menu, choose the kind of repository that stores the data you want to scan:
- Cloud Storage: Either enter the URL of the bucket you want to scan, or choose Include/exclude from the Location type menu, and then click Browse to navigate to the bucket or subfolder you want to scan. Select the Scan folder recursively checkbox to scan the specified directory and all contained directories. Leave it unselected to scan only the specified directory and no deeper.
- BigQuery: Enter the identifiers for the project, dataset, and table that you want to scan.
- Datastore: Enter the identifiers for the project, namespace (optional), and kind that you want to scan.
- Hybrid: You can add required labels, optional labels, and options for handling tabular data. For more information, see Types of metadata you can provide.
Sampling
Sampling is an optional way to save resources if you have a very large amount of data.
Under Sampling, you can choose whether to scan all the selected data or to sample the data by scanning a certain percentage. Sampling works differently depending on the type of storage repository you're scanning:
- For BigQuery, you can sample a subset of the total selected rows, corresponding to the percentage of files you specify to include in the scan.
- For Cloud Storage, if any file exceeds the size specified in the Max byte size to scan per file, Sensitive Data Protection scans it up to that maximum file size and then moves on to the next file.
To turn on sampling, choose one of the following options from the first menu:
- Start sampling from top: Sensitive Data Protection starts the partial scan at the beginning of the data. For BigQuery, this starts the scan at the first row. For Cloud Storage, this starts the scan at the beginning of each file, and stops scanning once Sensitive Data Protection has scanned up to any specified maximum file size.
- Start sampling from random start: Sensitive Data Protection starts the partial scan at a random location within the data. For BigQuery, this starts the scan at a random row. For Cloud Storage, this setting only applies to files that exceed any specified maximum size. Sensitive Data Protection scans files under the maximum file size in their entirety, and scans files above the maximum file size up to the maximum.
To perform a partial scan, you must also choose what percentage of the data you want to scan. Use the slider to set the percentage.
You can also narrow the files or records to scan by date. To learn how, see Schedule, later in this topic.
Advanced configuration
When you create a job for a scan of Cloud Storage buckets or BigQuery tables, you can narrow your search by specifying an advanced configuration. Specifically, you can configure:
- Files (Cloud Storage only): The file types to scan for, which include text, binary, and image files.
- Identifying fields (BigQuery only): Unique row identifiers within the table.
- For Cloud Storage, if any file exceeds the size specified in the Max byte size to scan per file, Sensitive Data Protection scans it up to that maximum file size and then moves on to the next file.
To turn on sampling, choose what percentage of the data you want to scan. Use the slider to set the percentage. Then, choose one of the following options from the first menu:
- Start sampling from top: Sensitive Data Protection starts the partial scan at the beginning of the data. For BigQuery, this starts the scan at the first row. For Cloud Storage, this starts the scan at the beginning of each file, and stops scanning once Sensitive Data Protection has scanned up to any specified maximum file size (see above).
- Start sampling from random start: Sensitive Data Protection starts the partial scan at a random location within the data. For BigQuery, this starts the scan at a random row. For Cloud Storage, this setting only applies to files that exceed any specified maximum size. Sensitive Data Protection scans files under the maximum file size in their entirety, and scans files above the maximum file size up to the maximum.
Files
For files stored in Cloud Storage, you can specify the types to include in your scan under Files.
You can choose from binary, text, image, CSV, TSV, Microsoft Word, Microsoft Excel,
Microsoft Powerpoint, PDF, and Apache Avro files. For an exhaustive list of file
extensions that Sensitive Data Protection can scan in Cloud Storage buckets,
see FileType.
Choosing Binary causes Sensitive Data Protection to scan files of
types that are unrecognized.
Identifying fields
For tables in BigQuery, in the Identifying fields field, you can direct Sensitive Data Protection to include the values of the table's primary key columns in the results. Doing so lets you link the findings back to the table rows that contain them.
Enter the names of the columns that uniquely identify each row within the table. If necessary, use dot notation to specify nested fields. You can add as many fields as you want.
You must also turn on the Save to BigQuery action to export the findings to
BigQuery. When the findings are exported to BigQuery, each finding
contains the respective values of the identifying fields. For more information, see
identifyingFields.
Configure detection
The Configure detection section is where you specify the types of sensitive data you want to scan for. Completing this section is optional. If you skip this section, Sensitive Data Protection will scan your data for a default set of infoTypes.
Template
You can optionally use a Sensitive Data Protection template to reuse configuration information you've specified previously.
If you have already created a template that you want to use, click in the Template name field to see a list of existing inspection templates. Choose or type the name of the template you want to use.
For more information about creating templates, see Creating Sensitive Data Protection inspection templates.
InfoTypes
InfoType detectors find sensitive data of a certain type. For example, the
Sensitive Data Protection US_SOCIAL_SECURITY_NUMBER built-in infoType detector
finds US Social Security numbers. In addition to the built-in infoType
detectors, you can create your own custom infoType detectors.
Under InfoTypes, choose the infoType detector that corresponds to a data type you want to scan for. We don't recommend leaving this section blank. Doing so causes Sensitive Data Protection to scan your data with a default set of infoTypes, which might include infoTypes that you don't need. For more information about each detector, see InfoType detector reference.
For more information about how to manage built-in and custom infoTypes in this section, see Manage infoTypes through the Google Cloud console.
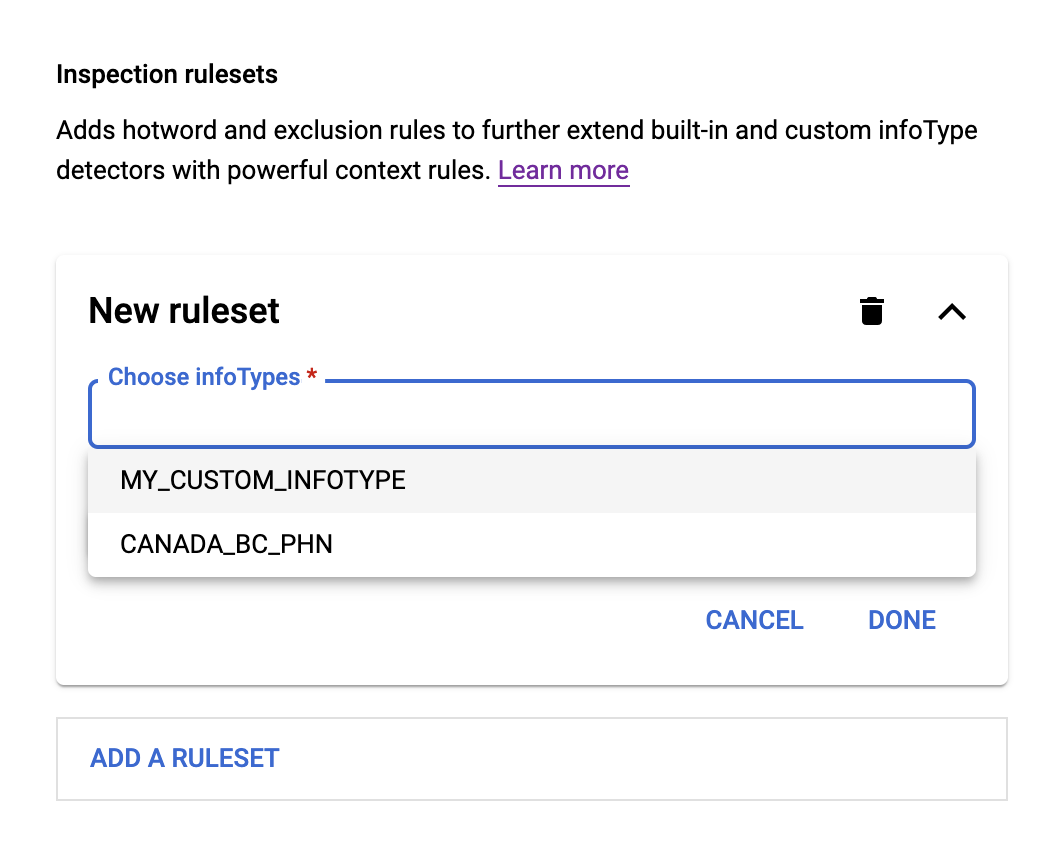
Inspection rulesets
Inspection rulesets allow you to customize both built-in and custom infoType detectors using context rules. The two types of inspection rules are:
- Exclusion rules, which help exclude false or unwanted findings.
- Hotword rules, which help detect additional findings.
To add a new ruleset, first specify one or more built-in or custom infoType detectors in the InfoTypes section. These are the infoType detectors that your rulesets will be modifying. Then, do the following:
- Click in the Choose infoTypes field. The infoType or infoTypes you specified previously appear below the field in a menu, as shown here:
- Choose an infoType from the menu, and then click Add rule. A menu appears with the two options Hotword rule and Exclusion rule.
For hotword rules, choose Hotword rules. Then, do the following:
- In the Hotword field, enter a regular expression that Sensitive Data Protection should look for.
- From the Hotword proximity menu, choose whether the hotword you entered is found before or after the chosen infoType.
- In Hotword distance from infoType, enter the approximate number of characters between the hotword and the chosen infoType.
- In Confidence level adjustment, choose whether to assign matches a fixed likelihood level, or to increase or decrease the default likelihood level by a certain amount.
For exclusion rules, choose Exclusion rules. Then, do the following:
- In the Exclude field, enter a regular expression (regex) that Sensitive Data Protection should look for.
- From the Matching type menu, choose one of the following:
- Full match: The finding must completely match the regex.
- Partial match: A substring of the finding can match the regex.
- Inverse match: The finding doesn't match the regex.
You can add additional hotword or exclusion rules and rulesets to further refine your scan results.
Confidence threshold
Every time Sensitive Data Protection detects a potential match for sensitive data, it assigns it a likelihood value on a scale from "Very unlikely" to "Very likely." When you set a likelihood value here, you are instructing Sensitive Data Protection to only match on data that corresponds to that likelihood value or higher.
The default value of "Possible" is sufficient for most purposes. If you routinely get matches that are too broad, move the slider up. If you get too few matches, move the slider down.
When you're done, click Continue.
Add actions
In the Add actions step, select one or more actions that you want Sensitive Data Protection to take after the job completes.
You can configure the following actions:
Save to BigQuery: Save the Sensitive Data Protection job results to a BigQuery table. Before viewing or analyzing the results, first ensure that the job has completed.
Each time a scan runs, Sensitive Data Protection saves scan findings to the BigQuery table you specify. The exported findings contain details about each finding's location and match likelihood. If you want each finding to include the string that matched the infoType detector, enable the Include quote option.
If you don't specify a table ID, BigQuery assigns a default name to a new table the first time the scan runs. If you specify an existing table, Sensitive Data Protection appends scan findings to it.
If you don't save findings to BigQuery, the scan results only contain statistics about the number and infoTypes of the findings.
When data is written to a BigQuery table, the billing and quota usage are applied to the project that contains the destination table.
Publish to Pub/Sub: Publish a notification that contains the name of the Sensitive Data Protection job as an attribute to a Pub/Sub channel. You can specify one or more topics to send the notification message to. Make sure that the Sensitive Data Protection service account running the scan job has publishing access on the topic.
Publish to Security Command Center: Publish a summary of the job results to Security Command Center. For more information, see Send Sensitive Data Protection scan results to Security Command Center.
Publish to Dataplex: Send job results to Dataplex, Google Cloud's metadata management service.
Notify by email: Send an email when the job completes. The email goes to IAM project owners and technical Essential Contacts.
Publish to Cloud Monitoring: Send inspection results to Cloud Monitoring in Google Cloud Observability.
Make a de-identified copy: De-identify any findings in the inspected data, and write the de-identified content to a new file. You can then use the de-identified copy in your business processes, in place of data that contains sensitive information. For more information, see Create a de-identified copy of Cloud Storage data using Sensitive Data Protection in the Google Cloud console.
For more information, see Actions.
When you're done selecting actions, click Continue.
Review
The Review section contains a JSON-formatted summary of the job settings you just specified.
Click Create to create the job (if you didn't specify a schedule) and to run the job once. The job'sinformation page appears, which contains status and other information. If the job is currently running, you can click the Cancel button to stop it. You can also delete the job by clicking Delete.
To return to the main Sensitive Data Protection page, click the Back arrow in the Google Cloud console.
C#
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Go
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Java
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Node.js
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
PHP
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Python
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
REST
A job is represented in the DLP API by the
DlpJobs
resource. You can create a new job by using the DlpJob resource's
projects.dlpJobs.create
method.
This sample JSON can be sent in a POST request to the specified Sensitive Data Protection REST endpoint. This example JSON demonstrates how to create a job in Sensitive Data Protection. The job is a Datastore inspection scan.
To quickly try this out, you can use the API Explorer that's embedded below. Keep in mind that a successful request, even one created in API Explorer, will create a job. For general information about using JSON to send requests to the DLP API, see the JSON quickstart.
JSON input:
{
"inspectJob": {
"storageConfig": {
"bigQueryOptions": {
"tableReference": {
"projectId": "bigquery-public-data",
"datasetId": "san_francisco_sfpd_incidents",
"tableId": "sfpd_incidents"
}
},
"timespanConfig": {
"startTime": "2020-01-01T00:00:01Z",
"endTime": "2020-01-31T23:59:59Z",
"timestampField": {
"name": "timestamp"
}
}
},
"inspectConfig": {
"infoTypes": [
{
"name": "PERSON_NAME"
},
{
"name": "STREET_ADDRESS"
}
],
"excludeInfoTypes": false,
"includeQuote": true,
"minLikelihood": "LIKELY"
},
"actions": [
{
"saveFindings": {
"outputConfig": {
"table": {
"projectId": "[PROJECT-ID]",
"datasetId": "[DATASET-ID]"
}
}
}
}
]
}
}
JSON output:
The following output indicates that the job was successfully created.
{
"name": "projects/[PROJECT-ID]/dlpJobs/[JOB-ID]",
"type": "INSPECT_JOB",
"state": "PENDING",
"inspectDetails": {
"requestedOptions": {
"snapshotInspectTemplate": {},
"jobConfig": {
"storageConfig": {
"bigQueryOptions": {
"tableReference": {
"projectId": "bigquery-public-data",
"datasetId": "san_francisco_sfpd_incidents",
"tableId": "sfpd_incidents"
}
},
"timespanConfig": {
"startTime": "2020-01-01T00:00:01Z",
"endTime": "2020-01-31T23:59:59Z",
"timestampField": {
"name": "timestamp"
}
}
},
"inspectConfig": {
"infoTypes": [
{
"name": "PERSON_NAME"
},
{
"name": "STREET_ADDRESS"
}
],
"minLikelihood": "LIKELY",
"limits": {},
"includeQuote": true
},
"actions": [
{
"saveFindings": {
"outputConfig": {
"table": {
"projectId": "[PROJECT-ID]",
"datasetId": "[DATASET-ID]",
"tableId": "[TABLE-ID]"
}
}
}
}
]
}
},
"result": {}
},
"createTime": "2020-07-10T07:26:33.643Z"
}
Create a new job trigger
To create a new Sensitive Data Protection job trigger:
Console
In the Sensitive Data Protection section of the Google Cloud console, go to the Create job or job trigger page.
Go to Create job or job trigger
The Create job or job trigger page contains the following sections:
Choose input data
Name
Enter a name for the job trigger. You can use letters, numbers, and hyphens. Naming your job trigger is optional. If you don't enter a name Sensitive Data Protection will give the job trigger a unique number identifier.
Location
From the Storage type menu, choose the kind of repository that stores the data you want to scan:
- Cloud Storage: Either enter the URL of the bucket you want to scan, or choose Include/exclude from the Location type menu, and then click Browse to navigate to the bucket or subfolder you want to scan. Select the Scan folder recursively checkbox to scan the specified directory and all contained directories. Leave it unselected to scan only the specified directory and no deeper.
- BigQuery: Enter the identifiers for the project, dataset, and table that you want to scan.
- Datastore: Enter the identifiers for the project, namespace (optional), and kind that you want to scan.
Sampling
Sampling is an optional way to save resources if you have a very large amount of data.
Under Sampling, you can choose whether to scan all the selected data or to sample the data by scanning a certain percentage. Sampling works differently depending on the type of storage repository you're scanning:
- For BigQuery, you can sample a subset of the total selected rows, corresponding to the percentage of files you specify to include in the scan.
- For Cloud Storage, if any file exceeds the size specified in the Max byte size to scan per file, Sensitive Data Protection scans it up to that maximum file size and then moves on to the next file.
To turn on sampling, choose one of the following options from the first menu:
- Start sampling from top: Sensitive Data Protection starts the partial scan at the beginning of the data. For BigQuery, this starts the scan at the first row. For Cloud Storage, this starts the scan at the beginning of each file, and stops scanning once Sensitive Data Protection has scanned up to any specified maximum file size (see above).
- Start sampling from random start: Sensitive Data Protection starts the partial scan at a random location within the data. For BigQuery, this starts the scan at a random row. For Cloud Storage, this setting only applies to files that exceed any specified maximum size. Sensitive Data Protection scans files under the maximum file size in their entirety, and scans files above the maximum file size up to the maximum.
To perform a partial scan, you must also choose what percentage of the data you want to scan. Use the slider to set the percentage.
Advanced configuration
When you create a job trigger for a scan of Cloud Storage buckets or BigQuery tables, you can narrow your search by specifying an advanced configuration. Specifically, you can configure:
- Files (Cloud Storage only): The file types to scan for, which include text, binary, and image files.
- Identifying fields (BigQuery only): Unique row identifiers within the table.
- For Cloud Storage, if any file exceeds the size specified in the Max byte size to scan per file, Sensitive Data Protection scans it up to that maximum file size and then moves on to the next file.
To turn on sampling, choose what percentage of the data you want to scan. Use the slider to set the percentage. Then, choose one of the following options from the first menu:
- Start sampling from top: Sensitive Data Protection starts the partial scan at the beginning of the data. For BigQuery, this starts the scan at the first row. For Cloud Storage, this starts the scan at the beginning of each file, and stops scanning once Sensitive Data Protection has scanned up to any specified maximum file size (see above).
- Start sampling from random start: Sensitive Data Protection starts the partial scan at a random location within the data. For BigQuery, this starts the scan at a random row. For Cloud Storage, this setting only applies to files that exceed any specified maximum size. Sensitive Data Protection scans files under the maximum file size in their entirety, and scans files above the maximum file size up to the maximum.
Files
For files stored in Cloud Storage, you can specify the types to include in your scan under Files.
You can choose from binary, text, image, Microsoft Word, Microsoft Excel,
Microsoft Powerpoint, PDF, and Apache Avro
files. For an exhaustive list of file extensions that Sensitive Data Protection can
scan in Cloud Storage buckets, see
FileType.
Choosing Binary causes Sensitive Data Protection to scan files of
types that are unrecognized.
Identifying fields
For tables in BigQuery, in the Identifying fields field, you can direct Sensitive Data Protection to include the values of the table's primary key columns in the results. Doing so lets you link the findings back to the table rows that contain them.
Enter the names of the columns that uniquely identify each row within the table. If necessary, use dot notation to specify nested fields. You can add as many fields as you want.
You must also turn on the Save to BigQuery action to export the findings to
BigQuery. When the findings are exported to BigQuery, each finding
contains the respective values of the identifying fields. For more information, see
identifyingFields.
Configure detection
The Configure detection section is where you specify the types of sensitive data you want to scan for. Completing this section is optional. If you skip this section, Sensitive Data Protection will scan your data for a default set of infoTypes.
Template
You can optionally use a Sensitive Data Protection template to reuse configuration information you've specified previously.
If you have already created a template that you want to use, click in the Template name field to see a list of existing inspection templates. Choose or type the name of the template you want to use.
For more information about creating templates, see Creating Sensitive Data Protection inspection templates.
InfoTypes
InfoType detectors find sensitive data of a certain type. For example, the
Sensitive Data Protection US_SOCIAL_SECURITY_NUMBER built-in infoType detector
finds US Social Security numbers. In addition to the built-in infoType
detectors, you can create your own custom infoType
detectors.
Under InfoTypes, choose the infoType detector that corresponds to a data type you want to scan for. You can also leave this field blank to scan for all default infoTypes. More information about each detector is provided in InfoType detector reference.
You can also add custom infoType detectors in the Custom infoTypes section, and customize both built-in and custom infoType detectors in the Inspection rulesets section.
Custom infoTypes
Inspection rulesets
Inspection rulesets allow you to customize both built-in and custom infoType detectors using context rules. The two types of inspection rules are:
- Exclusion rules, which help exclude false or unwanted findings.
- Hotword rules, which help detect additional findings.
To add a new ruleset, first specify one or more built-in or custom infoType detectors in the InfoTypes section. These are the infoType detectors that your rulesets will be modifying. Then, do the following:
- Click in the Choose infoTypes field. The infoType or infoTypes you specified previously appear below the field in a menu, as shown here:
- Choose an infoType from the menu, and then click Add rule. A menu appears with the two options Hotword rule and Exclusion rule.
For hotword rules, choose Hotword rules. Then, do the following:
- In the Hotword field, enter a regular expression that Sensitive Data Protection should look for.
- From the Hotword proximity menu, choose whether the hotword you entered is found before or after the chosen infoType.
- In Hotword distance from infoType, enter the approximate number of characters between the hotword and the chosen infoType.
- In Confidence level adjustment, choose whether to assign matches a fixed likelihood level, or to increase or decrease the default likelihood level by a certain amount.
For exclusion rules, choose Exclusion rules. Then, do the following:
- In the Exclude field, enter a regular expression (regex) that Sensitive Data Protection should look for.
- From the Matching type menu, choose one of the following:
- Full match: The finding must completely match the regex.
- Partial match: A substring of the finding can match the regex.
- Inverse match: The finding doesn't match the regex.
You can add additional hotword or exclusion rules and rulesets to further refine your scan results.
Confidence threshold
Every time Sensitive Data Protection detects a potential match for sensitive data, it assigns it a likelihood value on a scale from "Very unlikely" to "Very likely." When you set a likelihood value here, you are instructing Sensitive Data Protection to only match on data that corresponds to that likelihood value or higher.
The default value of "Possible" is sufficient for most purposes. If you routinely get matches that are too broad, move the slider up. If you get too few matches, move the slider down.
When you're done, click Continue.
Add actions
In the Add actions step, select one or more actions that you want Sensitive Data Protection to take after the job completes.
You can configure the following actions:
Save to BigQuery: Save the Sensitive Data Protection job results to a BigQuery table. Before viewing or analyzing the results, first ensure that the job has completed.
Each time a scan runs, Sensitive Data Protection saves scan findings to the BigQuery table you specify. The exported findings contain details about each finding's location and match likelihood. If you want each finding to include the string that matched the infoType detector, enable the Include quote option.
If you don't specify a table ID, BigQuery assigns a default name to a new table the first time the scan runs. If you specify an existing table, Sensitive Data Protection appends scan findings to it.
If you don't save findings to BigQuery, the scan results only contain statistics about the number and infoTypes of the findings.
When data is written to a BigQuery table, the billing and quota usage are applied to the project that contains the destination table.
Publish to Pub/Sub: Publish a notification that contains the name of the Sensitive Data Protection job as an attribute to a Pub/Sub channel. You can specify one or more topics to send the notification message to. Make sure that the Sensitive Data Protection service account running the scan job has publishing access on the topic.
Publish to Security Command Center: Publish a summary of the job results to Security Command Center. For more information, see Send Sensitive Data Protection scan results to Security Command Center.
Publish to Dataplex: Send job results to Dataplex, Google Cloud's metadata management service.
Notify by email: Send an email when the job completes. The email goes to IAM project owners and technical Essential Contacts.
Publish to Cloud Monitoring: Send inspection results to Cloud Monitoring in Google Cloud Observability.
Make a de-identified copy: De-identify any findings in the inspected data, and write the de-identified content to a new file. You can then use the de-identified copy in your business processes, in place of data that contains sensitive information. For more information, see Create a de-identified copy of Cloud Storage data using Sensitive Data Protection in the Google Cloud console.
For more information, see Actions.
When you're done selecting actions, click Continue.
Schedule
In the Schedule section, you can do two things:
- Specify time span: This option limits the files or rows to scan by date. Click Start time to specify the earliest file timestamp to include. Leave this value blank to specify all files. Click End time to specify the latest file timestamp to include. Leave this value blank to specify no upper timestamp limit.
Create a trigger to run the job on a periodic schedule: This option turns the job into a job trigger that runs on a periodic schedule. If you don't specify a schedule, you effectively create a single job that starts immediately and runs once. To create a job trigger that runs regularly, you must set this option.
The default value is also the minimum value: 24 hours. The maximum value is 60 days.
If you want Sensitive Data Protection to scan only new files or rows, select Limit scans only to new content. For BigQuery inspection, only rows that are at least three hours old are included in the scan. See the known issue related to this operation.
Review
The Review section contains a JSON-formatted summary of the job settings you just specified.
Click Create to create the job trigger (if you specified a schedule). The job trigger's information page appears, which contains status and other information. If the job is currently running, you can click the Cancel button to stop it. You can also delete the job trigger by clicking Delete.
To return to the main Sensitive Data Protection page, click the Back arrow in the Google Cloud console.
C#
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Go
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Java
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Node.js
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
PHP
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Python
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
REST
A job trigger is represented in the DLP API by the
JobTrigger
resource. You can create a new job trigger by using the JobTrigger resource's
projects.jobTriggers.create
method.
This sample JSON can be sent in a POST request to the specified Sensitive Data Protection REST endpoint. This example JSON demonstrates how to create a job trigger in Sensitive Data Protection. The job that this trigger will kick off is a Datastore inspection scan. The job trigger that is created runs every 86,400 seconds (or 24 hours).
To quickly try this out, you can use the API Explorer that's embedded below. Keep in mind that a successful request, even one created in API Explorer, will create a new scheduled job trigger. For general information about using JSON to send requests to the DLP API, see the JSON quickstart.
JSON input:
{
"jobTrigger":{
"displayName":"JobTrigger1",
"description":"Starts an inspection of a Datastore kind",
"triggers":[
{
"schedule":{
"recurrencePeriodDuration":"86400s"
}
}
],
"status":"HEALTHY",
"inspectJob":{
"storageConfig":{
"datastoreOptions":{
"kind":{
"name":"Example-Kind"
},
"partitionId":{
"projectId":"[PROJECT_ID]",
"namespaceId":"[NAMESPACE_ID]"
}
}
},
"inspectConfig":{
"infoTypes":[
{
"name":"PHONE_NUMBER"
}
],
"excludeInfoTypes":false,
"includeQuote":true,
"minLikelihood":"LIKELY"
},
"actions":[
{
"saveFindings":{
"outputConfig":{
"table":{
"projectId":"[PROJECT_ID]",
"datasetId":"[BIGQUERY_DATASET_NAME]",
"tableId":"[BIGQUERY_TABLE_NAME]"
}
}
}
}
]
}
}
}
JSON output:
The following output indicates that the job trigger was successfully created.
{
"name":"projects/[PROJECT_ID]/jobTriggers/[JOB_TRIGGER_NAME]",
"displayName":"JobTrigger1",
"description":"Starts an inspection of a Datastore kind",
"inspectJob":{
"storageConfig":{
"datastoreOptions":{
"partitionId":{
"projectId":"[PROJECT_ID]",
"namespaceId":"[NAMESPACE_ID]"
},
"kind":{
"name":"Example-Kind"
}
}
},
"inspectConfig":{
"infoTypes":[
{
"name":"PHONE_NUMBER"
}
],
"minLikelihood":"LIKELY",
"limits":{
},
"includeQuote":true
},
"actions":[
{
"saveFindings":{
"outputConfig":{
"table":{
"projectId":"[PROJECT_ID]",
"datasetId":"[BIGQUERY_DATASET_NAME]",
"tableId":"[BIGQUERY_TABLE_NAME]"
}
}
}
}
]
},
"triggers":[
{
"schedule":{
"recurrencePeriodDuration":"86400s"
}
}
],
"createTime":"2018-11-30T01:52:41.171857Z",
"updateTime":"2018-11-30T01:52:41.171857Z",
"status":"HEALTHY"
}
List all jobs
To list all jobs for the current project:
Console
In the Google Cloud console, go to the Sensitive Data Protection page.
Click the Inspection tab, and then click the Inspect jobs subtab.
The console displays a list of all jobs for the current project, including their job identifiers, state, creation time, and end time. You can get more information about any job—including a summary of its results— by clicking its identifier.
C#
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Go
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Java
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Node.js
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
PHP
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Python
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
REST
The DlpJob resource has a
projects.dlpJobs.list
method, with which you can list all jobs.
To list all jobs currently defined in your project, send a GET request
to the
dlpJobs endpoint, as shown
here:
URL:
GET https://dlp.googleapis.com/v2/projects/[PROJECT-ID]/dlpJobs?key={YOUR_API_KEY}
The following JSON output lists one of the jobs returned. Note that the
structure of the job mirrors that of the
DlpJob resource.
JSON output:
{
"jobs":[
{
"name":"projects/[PROJECT-ID]/dlpJobs/i-5270277269264714623",
"type":"INSPECT_JOB",
"state":"DONE",
"inspectDetails":{
"requestedOptions":{
"snapshotInspectTemplate":{
},
"jobConfig":{
"storageConfig":{
"cloudStorageOptions":{
"fileSet":{
"url":"[CLOUD-STORAGE-URL]"
},
"fileTypes":[
"FILE_TYPE_UNSPECIFIED"
],
"filesLimitPercent":100
},
"timespanConfig":{
"startTime":"2019-09-08T22:43:16.623Z",
"enableAutoPopulationOfTimespanConfig":true
}
},
"inspectConfig":{
"infoTypes":[
{
"name":"US_SOCIAL_SECURITY_NUMBER"
},
{
"name":"CANADA_SOCIAL_INSURANCE_NUMBER"
}
],
"minLikelihood":"LIKELY",
"limits":{
},
"includeQuote":true
},
"actions":[
{
"saveFindings":{
"outputConfig":{
"table":{
"projectId":"[PROJECT-ID]",
"datasetId":"[DATASET-ID]",
"tableId":"[TABLE-ID]"
}
}
}
}
]
}
},
"result":{
...
}
},
"createTime":"2019-09-09T22:43:16.918Z",
"startTime":"2019-09-09T22:43:16.918Z",
"endTime":"2019-09-09T22:43:53.091Z",
"jobTriggerName":"projects/[PROJECT-ID]/jobTriggers/sample-trigger2"
},
...
To quickly try this out, you can use the API Explorer that's embedded below. For general information about using JSON to send requests to the DLP API, see the JSON quickstart.
List all job triggers
To list all job triggers for the current project:
Console
In the Google Cloud console, go to the Sensitive Data Protection page.
Go to Sensitive Data Protection
On the Inspection tab, on the Job triggers subtab, the console displays a list of all job triggers for the current project.
C#
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Go
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Java
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Node.js
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
PHP
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Python
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
REST
The JobTrigger resource has a
projects.jobTriggers.list
method, with which you can list all job triggers.
To list all job triggers currently defined in your project, send a GET request
to the
jobTriggers
endpoint, as shown here:
URL:
GET https://dlp.googleapis.com/v2/projects/[PROJECT-ID]/jobTriggers?key={YOUR_API_KEY}
The following JSON output lists the job trigger we created in the previous
section. Note that the structure of the job trigger mirrors that of the
JobTrigger
resource.
JSON output:
{
"jobTriggers":[
{
"name":"projects/[PROJECT_ID]/jobTriggers/[JOB_TRIGGER_NAME]",
"displayName":"JobTrigger1",
"description":"Starts an inspection of a Datastore kind",
"inspectJob":{
"storageConfig":{
"datastoreOptions":{
"partitionId":{
"projectId":"[PROJECT_ID]",
"namespaceId":"[NAMESPACE_ID]"
},
"kind":{
"name":"Example-Kind"
}
}
},
"inspectConfig":{
"infoTypes":[
{
"name":"PHONE_NUMBER"
}
],
"minLikelihood":"LIKELY",
"limits":{
},
"includeQuote":true
},
"actions":[
{
"saveFindings":{
"outputConfig":{
"table":{
"projectId":"[PROJECT_ID]",
"datasetId":"[BIGQUERY_DATASET_NAME]",
"tableId":"[BIGQUERY_TABLE_NAME]"
}
}
}
}
]
},
"triggers":[
{
"schedule":{
"recurrencePeriodDuration":"86400s"
}
}
],
"createTime":"2018-11-30T01:52:41.171857Z",
"updateTime":"2018-11-30T01:52:41.171857Z",
"status":"HEALTHY"
},
...
],
"nextPageToken":"KkwKCQjivJ2UpPreAgo_Kj1wcm9qZWN0cy92ZWx2ZXR5LXN0dWR5LTE5NjEwMS9qb2JUcmlnZ2Vycy8xNTA5NzEyOTczMDI0MDc1NzY0"
}
To quickly try this out, you can use the API Explorer that's embedded below. For general information about using JSON to send requests to the DLP API, see the JSON quickstart.
Delete a job
To delete a job from your project, which includes its results, do the following. Any results saved externally (such as to BigQuery) are untouched by this operation.
Console
In the Google Cloud console, go to the Sensitive Data Protection page.
Click the Inspection tab, and then click the Inspect jobs subtab. The Google Cloud console displays a list of all jobs for the current project.
In the Actions column for the job trigger you want to delete, click the more actions menu (displayed as three dots arranged vertically) , and then click Delete.
Alternatively, from the list of jobs, click the identifier of the job you want to delete. On the job's detail page, click Delete.
C#
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Go
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Java
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Node.js
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
PHP
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Python
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
REST
To delete a job from the current project, send a
DELETE
request to the
dlpJobs
endpoint, as shown here. Replace the [JOB-IDENTIFIER] field with the
identifier of the job, which starts with i-.
URL:
DELETE https://dlp.googleapis.com/v2/projects/[PROJECT-ID]/dlpJobs/[JOB-IDENTIFIER]?key={YOUR_API_KEY}
If the request was successful, the DLP API will return a success response. To verify the job was successfully deleted, list all jobs.
To quickly try this out, you can use the API Explorer that's embedded below. For general information about using JSON to send requests to the DLP API, see the JSON quickstart.
Delete a job trigger
Console
In the Google Cloud console, go to the Sensitive Data Protection page.
Go to Sensitive Data Protection
On the Inspection tab, on the Job triggers subtab, the console displays a list of all job triggers for the current project.
In the Actions column for the job trigger you want to delete, click the more actions menu (displayed as three dots arranged vertically) , and then click Delete.
Alternatively, from the list of job triggers, click the name of the job trigger you want to delete. On the job trigger's detail page, click Delete.
C#
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Go
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Java
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Node.js
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
PHP
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Python
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
REST
To delete a job trigger from the current project, send a
DELETE
request to the
jobTriggers
endpoint, as shown here. Replace the [JOB-TRIGGER-NAME] field with the name
of the job trigger.
URL:
DELETE https://dlp.googleapis.com/v2/projects/[PROJECT-ID]/jobTriggers/[JOB-TRIGGER-NAME]?key={YOUR_API_KEY}
If the request was successful, the DLP API will return a success response. To verify the job trigger was successfully deleted, list all job triggers.
To quickly try this out, you can use the API Explorer that's embedded below. For general information about using JSON to send requests to the DLP API, see the JSON quickstart.
Get a job
To get a job from your project, which includes its results, do the following. Any results saved externally (such as to BigQuery) are untouched by this operation.
C#
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Go
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Java
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Node.js
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
PHP
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Python
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
REST
To get a job from the current project, send a
GET
request to the
dlpJobs
endpoint, as shown here. Replace the [JOB-IDENTIFIER] field with the
identifier of the job, which starts with i-.
URL:
GET https://dlp.googleapis.com/v2/projects/[PROJECT-ID]/dlpJobs/[JOB-IDENTIFIER]?key={YOUR_API_KEY}
If the request was successful, the DLP API will return a success response.
To quickly try this out, you can use the API Explorer that's embedded below. For general information about using JSON to send requests to the DLP API, see the JSON quickstart.
Force an immediate run of a job trigger
After a job trigger is created, you can force an immediate execution of the trigger for testing by activating it. To do so, run the following command:
curl --request POST \
-H "Content-Type: application/json" \
-H "Accept: application/json" \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "X-Goog-User-Project: PROJECT_ID" \
'https://dlp.googleapis.com/v2/JOB_TRIGGER_NAME:activate'
Replace the following:
- PROJECT_ID: the ID of the Google Cloud project to bill for access charges associated with the request.
- JOB_TRIGGER_NAME: the full resource name of the job
trigger—for example,
projects/my-project/locations/global/jobTriggers/123456789.
Update an existing job trigger
In addition to creating, listing, and deleting job triggers, you can also update an existing job trigger. To change the configuration for an existing job trigger:
Console
In the Google Cloud console, go to the Sensitive Data Protection page.
Click the Inspection tab, and then click the Job triggers subtab.
The console displays a list of all job triggers for the current project.
In the Actions column for the job trigger you want to delete, click More more_vert, then click View details.
On the job trigger detail page, click Edit.
On the Edit trigger page, you can change the location of the input data; detection details such as templates, infoTypes, or likelihood; any post-scan actions, and the job trigger's schedule. When you're done making changes, click Save.
C#
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Go
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Java
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Node.js
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
PHP
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Python
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
REST
Use the
projects.jobTriggers.patch
method to send new JobTrigger values to the DLP API
to update those values within a specified job trigger.
For example, consider the following simple job trigger. This JSON represents the job trigger, and was returned after sending a GET request to the current project's job trigger endpoint.
JSON output:
{
"name":"projects/[PROJECT_ID]/jobTriggers/[JOB_TRIGGER_NAME]",
"inspectJob":{
"storageConfig":{
"cloudStorageOptions":{
"fileSet":{
"url":"gs://dlptesting/*"
},
"fileTypes":[
"FILE_TYPE_UNSPECIFIED"
],
"filesLimitPercent":100
},
"timespanConfig":{
"enableAutoPopulationOfTimespanConfig":true
}
},
"inspectConfig":{
"infoTypes":[
{
"name":"US_SOCIAL_SECURITY_NUMBER"
}
],
"minLikelihood":"POSSIBLE",
"limits":{
}
},
"actions":[
{
"jobNotificationEmails":{
}
}
]
},
"triggers":[
{
"schedule":{
"recurrencePeriodDuration":"86400s"
}
}
],
"createTime":"2019-03-06T21:19:45.774841Z",
"updateTime":"2019-03-06T21:19:45.774841Z",
"status":"HEALTHY"
}
The following JSON, when sent with a PATCH request to the specified endpoint,
updates the given job trigger with a new infoType to scan for, as well as a new
minimum likelihood. Note that you must also specify the updateMask attribute,
and that its value is in
FieldMask
format.
JSON input:
PATCH https://dlp.googleapis.com/v2/projects/[PROJECT_ID]/jobTriggers/[JOB_TRIGGER_NAME]?key={YOUR_API_KEY}
{
"jobTrigger":{
"inspectJob":{
"inspectConfig":{
"infoTypes":[
{
"name":"US_INDIVIDUAL_TAXPAYER_IDENTIFICATION_NUMBER"
}
],
"minLikelihood":"LIKELY"
}
}
},
"updateMask":"inspectJob(inspectConfig(infoTypes,minLikelihood))"
}
After you send this JSON to the specified URL, it returns the following, which represents the updated job trigger. Note that the original infoType and likelihood values have been replaced by the new values.
JSON output:
{
"name":"projects/[PROJECT_ID]/jobTriggers/[JOB_TRIGGER_NAME]",
"inspectJob":{
"storageConfig":{
"cloudStorageOptions":{
"fileSet":{
"url":"gs://dlptesting/*"
},
"fileTypes":[
"FILE_TYPE_UNSPECIFIED"
],
"filesLimitPercent":100
},
"timespanConfig":{
"enableAutoPopulationOfTimespanConfig":true
}
},
"inspectConfig":{
"infoTypes":[
{
"name":"US_INDIVIDUAL_TAXPAYER_IDENTIFICATION_NUMBER"
}
],
"minLikelihood":"LIKELY",
"limits":{
}
},
"actions":[
{
"jobNotificationEmails":{
}
}
]
},
"triggers":[
{
"schedule":{
"recurrencePeriodDuration":"86400s"
}
}
],
"createTime":"2019-03-06T21:19:45.774841Z",
"updateTime":"2019-03-06T21:27:01.650183Z",
"lastRunTime":"1970-01-01T00:00:00Z",
"status":"HEALTHY"
}
To quickly try this out, you can use the API Explorer that's embedded below. For general information about using JSON to send requests to the DLP API, see the JSON quickstart.
Job latency
There are no service level objectives (SLO) guaranteed for jobs and job triggers. Latency is affected by several factors, including the amount of data to scan, the storage repository being scanned, the type and number of infoTypes you are scanning for, the region where the job is processed, and the computing resources available in that region. Therefore, the latency of inspection jobs can't be determined in advance.
To help reduce job latency, you can try the following:
- If sampling is available for your job or job trigger, enable it.
Avoid enabling infoTypes that you don't need. Although the following are useful in certain scenarios, these infoTypes can make requests run much more slowly than requests that don't include them:
PERSON_NAMEFEMALE_NAMEMALE_NAMEFIRST_NAMELAST_NAMEDATE_OF_BIRTHLOCATIONSTREET_ADDRESSORGANIZATION_NAME
Always specify infoTypes explicitly. Do not use an empty infoTypes list.
If possible, use a different processing region.
If you're still having latency issues with jobs after trying these techniques,
consider using
content.inspect or
content.deidentify
requests instead of jobs. These methods are covered under the Service Level
Agreement. For more information, see Sensitive Data Protection Service Level
Agreement.
Limit scans to only new content
You can configure your job trigger to automatically set the timespan date for
files stored in Cloud Storage or
BigQuery. When you set the
TimespanConfig
object to auto-populate, Sensitive Data Protection only scans data that was
added or modified since the trigger last ran:
...
timespan_config {
enable_auto_population_of_timespan_config: true
}
...
For BigQuery inspection, only rows that are at least three hours old are included in the scan. See the known issue related to this operation.
Trigger jobs at file upload
In addition to the support for job triggers—which is built into Sensitive Data Protection—Google Cloud also has a variety of other components that you can use to integrate or trigger Sensitive Data Protection jobs. For example, you can use Cloud Run functions to trigger a Sensitive Data Protection scan every time a file is uploaded to Cloud Storage.
For information about how to set up this operation, see Automating the classification of data uploaded to Cloud Storage.
Successful jobs with no data inspected
A job can complete successfully even if no data was scanned. The following example scenarios can cause this to happen:
- The job is configured to inspect a specific data asset, such as a file, that exists but is empty.
- The job is configured to inspect a data asset that doesn't exist or that no longer exists.
- The job is configured to inspect a Cloud Storage bucket that is empty.
- The job is configured to inspect a bucket, and recursive scanning is disabled. At the top level, the bucket contains only folders that, in turn, contain the files.
- The job is configured to inspect only a specific file type in a bucket, but the bucket doesn't have any files of that type.
- The job is configured to inspect only new content, but there were no updates after the last time the job was run.
In the Google Cloud console, on the Job details page, the Bytes scanned
field specifies how much data was inspected by the job. In the
DLP API, the
processedBytes field
specifies how much data was inspected.
What's next
- Learn more about creating a de-identified copy of data in storage.