泛化是一种获取可区分值并将其抽象为较普通、较不易区分的值的过程。泛化的目的是保留数据效用,同时降低数据的可标识性。
存在许多级别的泛化,具体取决于数据类型。您可以使用敏感数据保护的风险分析方法中包含的技术,在数据集或实际人口中进行测量,了解需要什么级别的泛化。
Sensitive Data Protection 支持的一种常见泛化技术是“分桶”。通过分桶,您可以将记录分组到较小的存储分区中,以尽量降低攻击者将敏感信息与标识性信息相关联的风险。这样做可以保留含义和效用,但也会模糊参与者太少的个体值。
分桶场景 1
请考虑此数值分桶场景:数据库存储用户满意度分数,范围从 0 到 100。该数据库如下所示:
| user_id | 得分 |
|---|---|
| 1 | 100 |
| 2 | 100 |
| 3 | 92 |
| ... | … |
扫描数据后,您会发现某些值很少被用户使用。 事实上,有一些分数只映射到一个用户。例如,大多数用户选择 0、25、50、75 或 100。但是,有五个用户选择了 95,只有一个用户选择了 92。您可以将这些值泛化到多个组中,并消除任何参与者太少的组,而不是保留原始数据。以这种方式泛化数据有助于防止重标识,具体取决于数据的使用方式。
您可以选择移除这些离群数据行,也可以尝试使用分桶保留其效用。在此示例中,我们根据以下项对所有值进行分桶:
- 0-25:“低”
- 26-75:“中”
- 76-100:“高”
Sensitive Data Protection 中的分桶是可用于去标识化的多种初始转换之一。以下 JSON 配置说明了如何在 DLP API 中实现此分桶场景。此 JSON 可以包含在对 content.deidentify 方法的请求中:
C#
如需了解如何安装和使用 Sensitive Data Protection 客户端库,请参阅 Sensitive Data Protection 客户端库。
如需向 Sensitive Data Protection 进行身份验证,请设置应用默认凭据。如需了解详情,请参阅为本地开发环境设置身份验证。
Go
如需了解如何安装和使用 Sensitive Data Protection 客户端库,请参阅 Sensitive Data Protection 客户端库。
如需向 Sensitive Data Protection 进行身份验证,请设置应用默认凭据。如需了解详情,请参阅为本地开发环境设置身份验证。
Java
如需了解如何安装和使用 Sensitive Data Protection 客户端库,请参阅 Sensitive Data Protection 客户端库。
如需向 Sensitive Data Protection 进行身份验证,请设置应用默认凭据。如需了解详情,请参阅为本地开发环境设置身份验证。
Node.js
如需了解如何安装和使用 Sensitive Data Protection 客户端库,请参阅 Sensitive Data Protection 客户端库。
如需向 Sensitive Data Protection 进行身份验证,请设置应用默认凭据。如需了解详情,请参阅为本地开发环境设置身份验证。
PHP
如需了解如何安装和使用 Sensitive Data Protection 客户端库,请参阅 Sensitive Data Protection 客户端库。
如需向 Sensitive Data Protection 进行身份验证,请设置应用默认凭据。如需了解详情,请参阅为本地开发环境设置身份验证。
Python
如需了解如何安装和使用 Sensitive Data Protection 客户端库,请参阅 Sensitive Data Protection 客户端库。
如需向 Sensitive Data Protection 进行身份验证,请设置应用默认凭据。如需了解详情,请参阅为本地开发环境设置身份验证。
REST
...
{
"primitiveTransformation":
{
"bucketingConfig":
{
"buckets":
[
{
"min":
{
"integerValue": "0"
},
"max":
{
"integerValue": "25"
},
"replacementValue":
{
"stringValue": "Low"
}
},
{
"min":
{
"integerValue": "26"
},
"max":
{
"integerValue": "75"
},
"replacementValue":
{
"stringValue": "Medium"
}
},
{
"min":
{
"integerValue": "76"
},
"max":
{
"integerValue": "100"
},
"replacementValue":
{
"stringValue": "High"
}
}
]
}
}
}
...
分桶场景 2
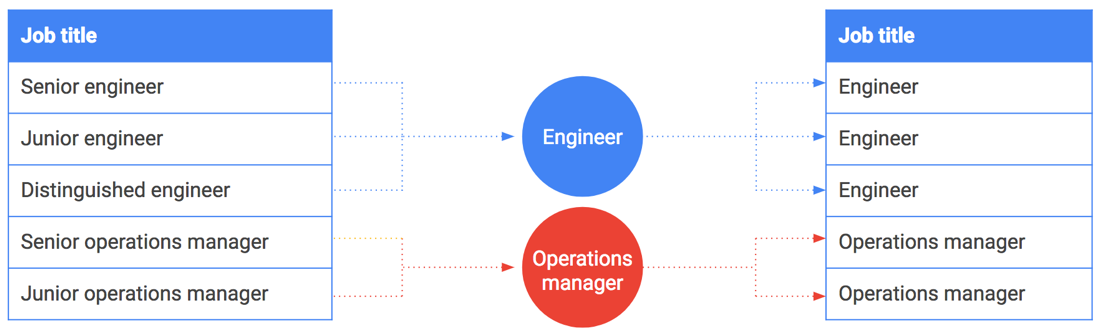
分桶也可用于字符串或枚举值。假设您想要分享薪资数据并包含职位。但是,某些职位(如 CEO 或杰出工程师)可以与一个人或一小群人联系起来。这些职位很容易与拥有这些职位的员工匹配。
分桶也可以用于这种情况。不要包括确切的职位,而是对它们进行泛化和分桶。例如,将“高级工程师”、“初级工程师”和“杰出工程师”泛化和分桶为“工程师”。下表说明了如何将特定职位分桶到职位系列中。
其他场景
在这些示例中,我们将对结构化数据应用转换。只要可以使用预定义或自定义的 infoType 对值进行分类,则分桶也可用于非结构化示例。以下是一些示例场景:
- 对日期进行分类并将其按年份分桶
- 对名称进行分类并根据首字母(A-M、N-Z)将其分桶到不同的组
资源
要详细了解泛化和分桶,请参阅对文本内容中的敏感数据进行去标识化。
如需 API 文档,请参阅:
projects.content.deidentify方法BucketingConfig转换:根据自定义范围对值进行分桶。FixedSizeBucketingConfig转换:根据固定大小范围对值进行分桶。