Esta página mostra como usar o conector do Spark Spanner para ler dados do Spanner usando o Apache Spark.
Cálculo de custos
Neste documento, você usará os seguintes componentes faturáveis do Google Cloud:
- Dataproc
- Spanner
- Cloud Storage
Para gerar uma estimativa de custo baseada na projeção de uso deste tutorial, use a calculadora de preços.
Antes de começar
Antes de executar o tutorial, saiba qual é a versão do conector e obtenha um URI do conector.
Como especificar o URI do arquivo JAR do conector
As versões do conector Spark Spanner estão listadas no repositório do GitHub GoogleCloudDataproc/spark-spanner-connector.
Especifique o arquivo JAR do conector substituindo as informações da versão do conector
na seguinte string de URI:
gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar
O conector está disponível para as versões do Spark 3.1+
Exemplo da CLI gcloud:
gcloud dataproc jobs submit spark \ --jars=gs://spark-lib/spanner/spark-3.1-spanner-1.0.0.jar \ -- job-args
Preparar o banco de dados do Spanner
Se você não tiver uma tabela do Spanner, siga o
tutorial para criar uma. Depois disso, você terá um ID de instância,
um ID de banco de dados e uma tabela Singers.
Criar cluster do Dataproc
Qualquer cluster do Dataproc que use o conector precisa dos escopos spanner ou cloud-platform. Os clusters do Dataproc têm o escopo padrão cloud-platform para a imagem 2.1 ou mais recente. Se você usar uma versão mais antiga, poderá usar o console do Google Cloud, a Google Cloud CLI e a API Dataproc para criar um cluster do Dataproc.
Console
- No console do Google Cloud, abra a página Criar um cluster do Dataproc.
- Na guia "Gerenciar segurança", clique em "Ativa o escopo da plataforma de nuvem para este cluster" na seção "Acesso ao projeto".
- Preencha ou confirme os outros campos de criação de clusters e clique em "Criar".
Google Cloud CLI
gcloud dataproc clusters create CLUSTER_NAME --scopes https://www.googleapis.com/auth/cloud-platform
API
É possível especificar o GceClusterConfig.serviceAccountScopes como parte de uma solicitação clusters.create. Exemplo:
"serviceAccountScopes": ["https://www.googleapis.com/auth/cloud-platform"],
Verifique se a permissão do Spanner correspondente foi atribuída à conta de serviço da VM do Dataproc. Se você usar o Data Boost no tutorial, consulte a permissão do IAM do Data Boost.
Ler dados do Spanner
É possível usar Scala e Python para ler dados do Spanner em um Dataframe do Spark usando a API de origem de dados do Spark.
Scala
- Examine o código e substitua os marcadores [projectId], [instanceId], [databaseId] e [table] pelo ID do projeto, da instância, do banco de dados e da tabela que você criou anteriormente. A opção enableDataBoost ativa o recurso Data Boost do Spanner, que tem
impacto quase zero na instância principal do Spanner.
object singers { def main(): Unit = { /* * Remove comment if you are not running in spark-shell. * import org.apache.spark.sql.SparkSession val spark = SparkSession.builder() .appName("spark-spanner-demo") .getOrCreate() */ // Load data in from Spanner. See // https://github.com/GoogleCloudDataproc/spark-spanner-connector/blob/main/README.md#properties // for option information. val singersDF = (spark.read.format("cloud-spanner") .option("projectId", "[projectId]") .option("instanceId", "[instanceId]") .option("databaseId", "[databaseId]") .option("enableDataBoost", true) .option("table", "[table]") .load() .cache()) singersDF.createOrReplaceTempView("Singers") // Load the Singers table. val result = spark.sql("SELECT * FROM Singers") result.show() result.printSchema() } }
- Executar o código no seu cluster
- Use o SSH para se conectar ao nó mestre do cluster do Dataproc.
- Acesse a página Clusters do Dataproc no console do Google Cloud e clique no nome do cluster.
- Na página >Detalhes do cluster, selecione a guia "Instâncias de VM". Em seguida, clique em
SSHà direita do nome do nó mestre do cluster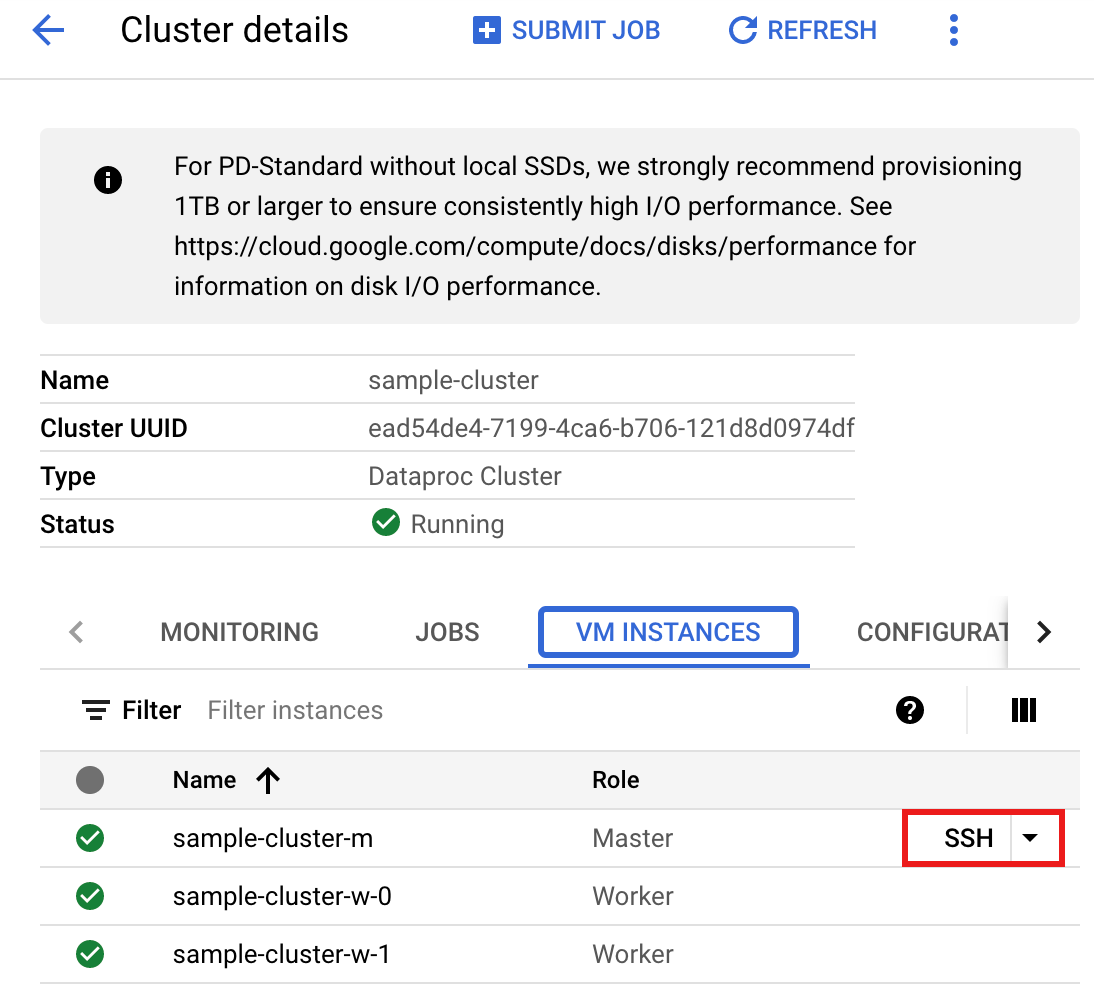
Uma janela do navegador é aberta no diretório principal do nó mestre.Connected, host fingerprint: ssh-rsa 2048 ... ... user@clusterName-m:~$
- Acesse a página Clusters do Dataproc no console do Google Cloud e clique no nome do cluster.
- Crie
singers.scalacom o editor de textovi,vimounanopré-instalado e cole o código da lista de códigos Scalanano singers.scala
- Inicie o REPL
spark-shell.$ spark-shell --jars=gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar
- Execute singers.scala com o comando
:load singers.scalapara criar a tabelaSingersdo Spanner. A listagem de saída mostra exemplos da saída de Singers.> :load singers.scala Loading singers.scala... defined object singers > singers.main() ... +--------+---------+--------+---------+-----------+ |SingerId|FirstName|LastName|BirthDate|LastUpdated| +--------+---------+--------+---------+-----------+ | 1| Marc|Richards| null| null| | 2| Catalina| Smith| null| null| | 3| Alice| Trentor| null| null| +--------+---------+--------+---------+-----------+ root |-- SingerId: long (nullable = false) |-- FirstName: string (nullable = true) |-- LastName: string (nullable = true) |-- BirthDate: date (nullable = true) |-- LastUpdated: timestamp (nullable = true)
PySpark
- Examine o código e substitua os marcadores [projectId], [instanceId], [databaseId] e [table] pelo ID do projeto, da instância, do banco de dados e da tabela que você criou anteriormente. A opção enableDataBoost ativa o recurso Data Boost do Spanner, que tem
impacto quase zero na instância principal do Spanner.
#!/usr/bin/env python """Spanner PySpark read example.""" from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .master('yarn') \ .appName('spark-spanner-demo') \ .getOrCreate() # Load data from Spanner. singers = spark.read.format('cloud-spanner') \ .option("projectId", "[projectId]") \ .option("instanceId", "[instanceId]") \ .option("databaseId", "[databaseId]") \ .option("enableDataBoost", "true") \ .option("table", "[table]") \ .load() singers.createOrReplaceTempView('Singers') # Read from Singers result = spark.sql('SELECT * FROM Singers') result.show() result.printSchema()
- Execute o código no cluster
- Use o SSH para se conectar ao nó mestre do cluster do Dataproc.
- Acesse a página Clusters do Dataproc no console do Google Cloud e clique no nome do cluster.
- Na página Detalhes do cluster, selecione a guia "Instâncias de VM". Em seguida, clique em
SSHà direita do nome do nó mestre do cluster
Uma janela do navegador é aberta no diretório principal do nó principal.Connected, host fingerprint: ssh-rsa 2048 ... ... user@clusterName-m:~$
- Acesse a página Clusters do Dataproc no console do Google Cloud e clique no nome do cluster.
- Crie
singers.pycom o editor de textovi,vimounanopré-instalado e cole o código PySpark da lista de códigos PySparknano singers.py
- Execute singers.py com
spark-submitpara criar a tabelaSingersdo Spanner.spark-submit --jars gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar singers.py
... +--------+---------+--------+---------+-----------+ |SingerId|FirstName|LastName|BirthDate|LastUpdated| +--------+---------+--------+---------+-----------+ | 1| Marc|Richards| null| null| | 2| Catalina| Smith| null| null| | 3| Alice| Trentor| null| null| +--------+---------+--------+---------+-----------+ root |-- SingerId: long (nullable = false) |-- FirstName: string (nullable = true) |-- LastName: string (nullable = true) |-- BirthDate: date (nullable = true) |-- LastUpdated: timestamp (nullable = true) only showing top 20 rows
- Use o SSH para se conectar ao nó mestre do cluster do Dataproc.
Limpeza
Para limpar e evitar cobranças contínuas na sua conta do Google Cloud pelos recursos criados neste tutorial, siga estas etapas.
gcloud dataproc clusters stop CLUSTER_NAME gcloud dataproc clusters delete CLUSTER_NAME