使用 Dataproc Hub
從 Dataproc Hub 建立 Dataproc JupyterLab 叢集
在 Google Cloud 控制台的「Dataproc」→「Workbench」頁面中,選取「使用者自行管理的筆記本」分頁。
在列出管理員建立的 Dataproc Hub 執行個體資料列中,按一下「Open JupyterLab」。
- 如果您無法存取 Google Cloud 控制台,請在網頁瀏覽器中輸入管理員與您共用的 Dataproc Hub 執行個體網址。
在「Jupyterhub→Dataproc Options」(Jupyterhub→Dataproc 選項) 頁面中,選取叢集設定和區域。如果啟用,請指定任何自訂項目,然後按一下「建立」。
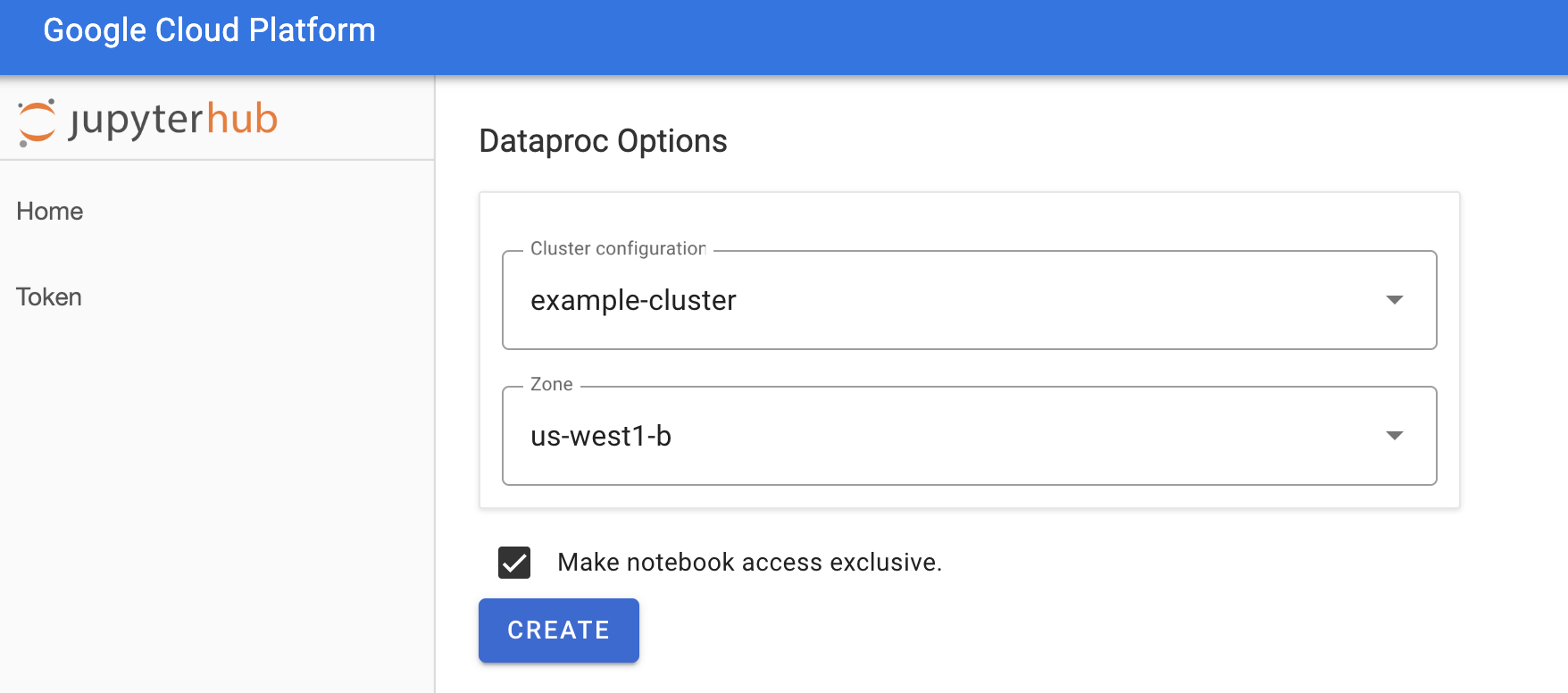
建立 Dataproc 叢集後,系統會將您重新導向至叢集上執行的 JupyterLab 介面。
建立筆記本並執行 Spark 工作
在 JupyterLab 介面的左側面板中,按一下 GCS (Cloud Storage)。
從 JupyterLab 啟動器建立 PySpark 筆記本。
PySpark 核心會初始化 SparkContext (使用 sc 變數)。您可以檢查 SparkContext,並從筆記本執行 Spark 工作。
rdd = (sc.parallelize(['lorem', 'ipsum', 'dolor', 'sit', 'amet', 'lorem'])
.map(lambda word: (word, 1))
.reduceByKey(lambda a, b: a + b))
print(rdd.collect())
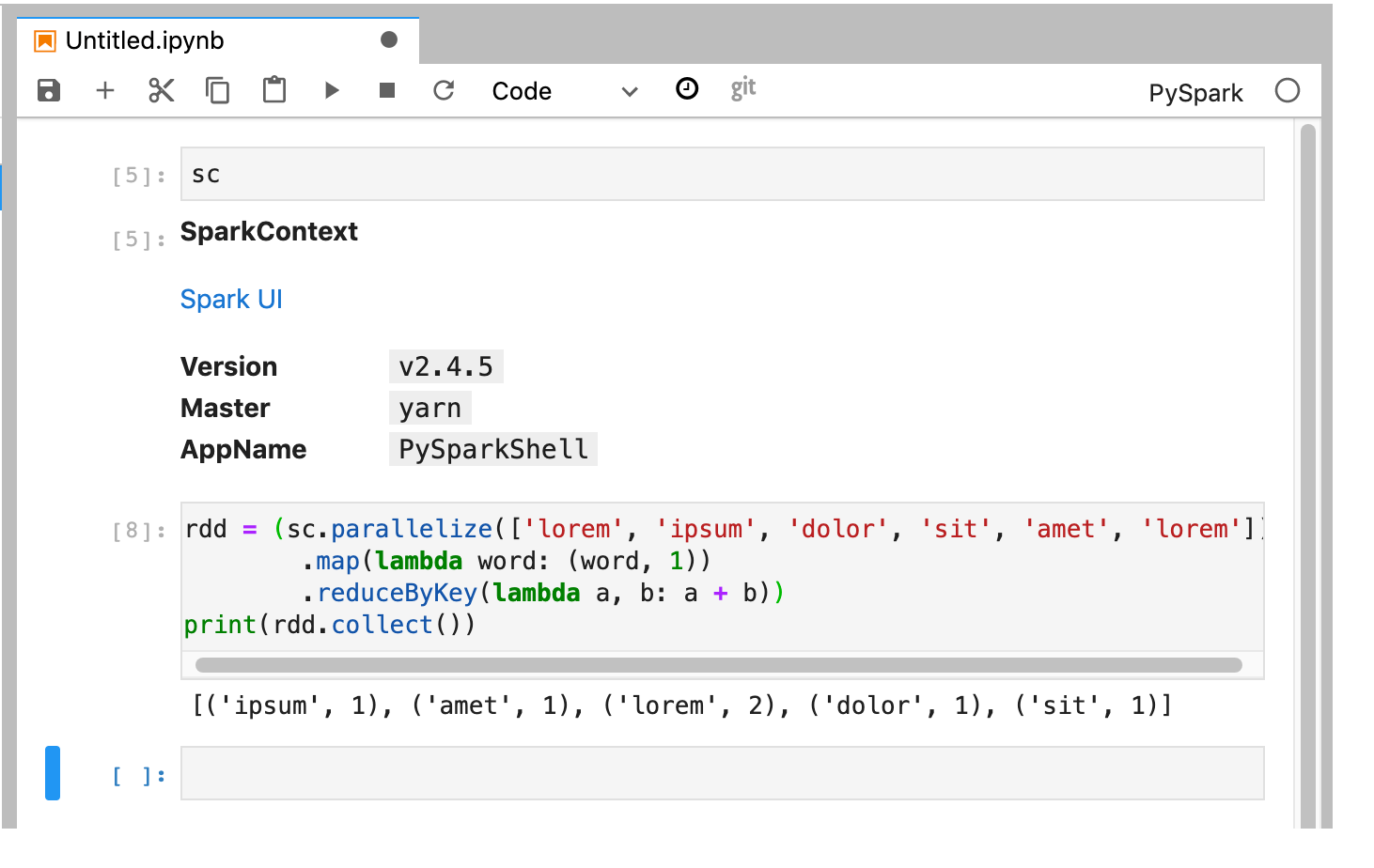
為筆記本命名並儲存。刪除 Dataproc 叢集後,筆記本會儲存在 Cloud Storage 中。
關閉 Dataproc 叢集
在 JupyterLab 介面中,選取「File」→「Hub Control Panel」,開啟 Jupyterhub 頁面。
按一下「Stop My Cluster」(停止我的叢集),關閉 (刪除) JupyterLab 伺服器,並刪除 Dataproc 叢集。
除非另有註明,否則本頁面中的內容是採用創用 CC 姓名標示 4.0 授權,程式碼範例則為阿帕契 2.0 授權。詳情請參閱《Google Developers 網站政策》。Java 是 Oracle 和/或其關聯企業的註冊商標。
上次更新時間:2025-10-19 (世界標準時間)。
[[["容易理解","easyToUnderstand","thumb-up"],["確實解決了我的問題","solvedMyProblem","thumb-up"],["其他","otherUp","thumb-up"]],[["難以理解","hardToUnderstand","thumb-down"],["資訊或程式碼範例有誤","incorrectInformationOrSampleCode","thumb-down"],["缺少我需要的資訊/範例","missingTheInformationSamplesINeed","thumb-down"],["翻譯問題","translationIssue","thumb-down"],["其他","otherDown","thumb-down"]],["上次更新時間:2025-10-19 (世界標準時間)。"],[],[]]