目标
使用 Dataproc 中心创建在 Dataproc 集群上运行的单用户 JupyterLab 笔记本环境。
在 Dataproc 集群上创建笔记本并运行 Spark 作业。
删除集群并在 Cloud Storage 中保留您的笔记本。
准备工作
- 管理员必须为您授予
notebooks.instances.use权限(请参阅设置 Identity and Access Management (IAM) 角色)。
通过 Dataproc Hub 创建 Dataproc JupyterLab 集群
在 Google Cloud 控制台中,选择 Dataproc→Workbench 页面上的用户管理的笔记本标签页。
在列出管理员创建的 Dataproc Hub 实例的行中,点击打开 JupyterLab。
- 如果您无权访问 Google Cloud 控制台,请在网络浏览器中输入管理员与您分享的 Dataproc Hub 实例网址。
在 Jupyterhub→Dataproc 选项页面上,选择集群配置和可用区。启用后,请指定任意自定义项,然后点击创建。

创建 Dataproc 集群后,系统会将您重定向到在集群上运行的 JupyterLab 界面。
创建笔记本并运行 Spark 作业
在 JupyterLab 界面的左侧面板上,点击
GCS(Cloud Storage)。通过 JupyterLab 启动器创建 PySpark 笔记本。

PySpark 内核会初始化 SparkContext(使用
sc变量)。您可以从笔记本中检查 SparkContext 并运行 Spark 作业。rdd = (sc.parallelize(['lorem', 'ipsum', 'dolor', 'sit', 'amet', 'lorem']) .map(lambda word: (word, 1)) .reduceByKey(lambda a, b: a + b)) print(rdd.collect())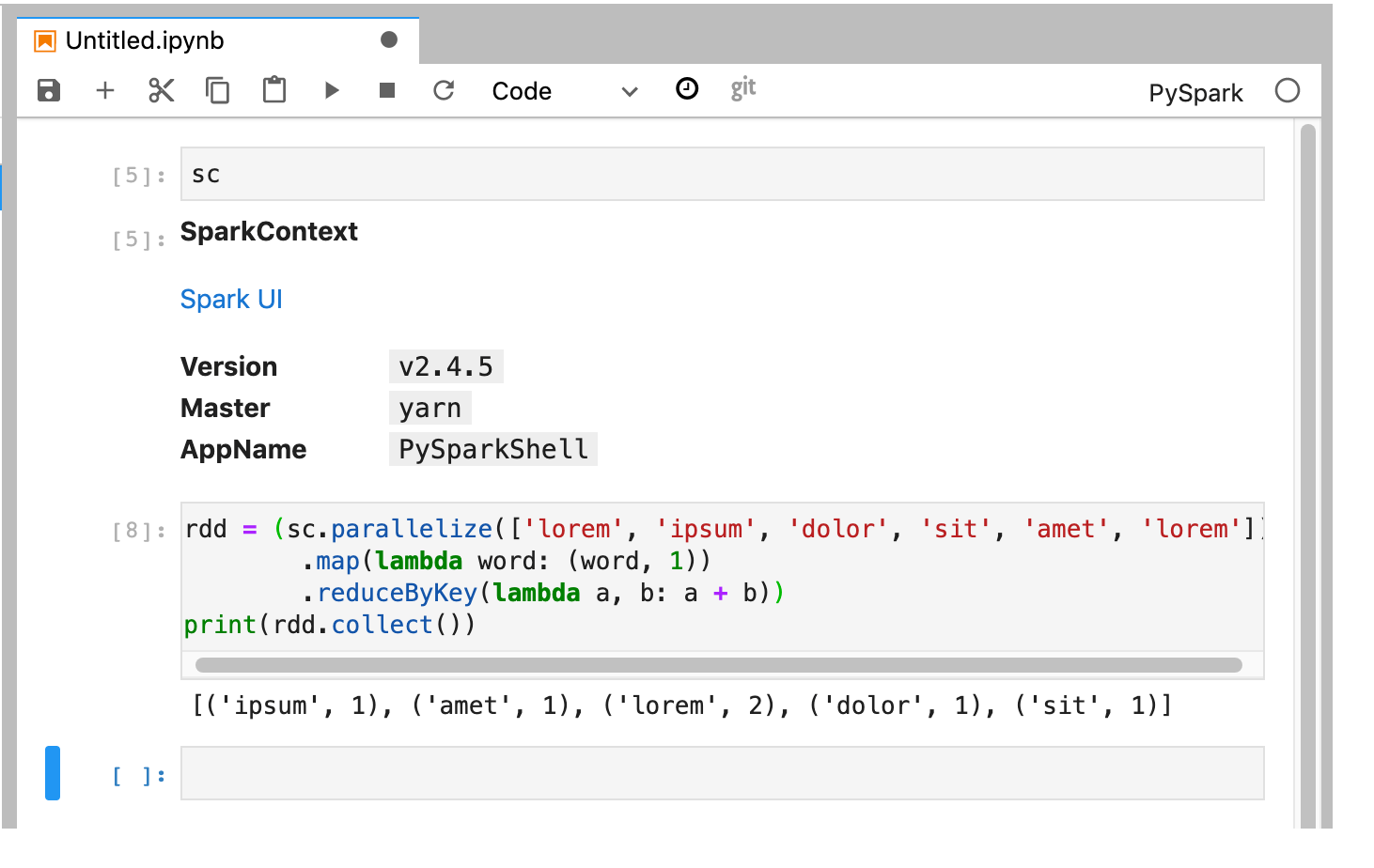
为笔记本命名并保存。在删除 Dataproc 集群后,笔记本将保存并保留在 Cloud Storage 中。
关停 Dataproc 集群
在 JupyterLab 界面中,选择文件→Hub 控制台以打开 Jupyterhub 页面。
点击停止我的集群以关停(删除)JupyterLab 服务器,这会删除 Dataproc 集群。
后续步骤
- 在 GitHub 上探索 Dataproc 上的 Spark 和 Jupyter 笔记本。