La traçabilité des données vous aide à comprendre comment les données transitent par vos systèmes en suivant les relations entre les assets de données et les processus qui les transforment. Vous pouvez afficher ces informations sur la lignée sous forme de graphiques et de listes dans la console Google Cloud .
Ce document présente le modèle d'informations sur la traçabilité des données, fournit des détails sur la précision de la traçabilité au niveau des tables et des colonnes, et explique comment utiliser les vues Graphique et Liste pour explorer la traçabilité des données.
Modèle d'informations sur la traçabilité des données
La traçabilité est un enregistrement des données transformées de sources en cibles. L'API Data Lineage collecte ces informations et les organise dans un modèle de données hiérarchique à l'aide des concepts de processus, d'exécutions et d'événements.
- Processus : définition de la transformation des données.
- Exécution : exécution d'un processus.
- Événement : enregistrement du déplacement des données lors d'une exécution.
Processus
Un processus est la définition d'une opération de transformation de données pour un système spécifique. Pour la traçabilité BigQuery, un processus est un job d'un type de job accepté. Toutes les exécutions d'une même requête SQL sont associées à un seul processus, ce qui vous permet de suivre chaque instance où une logique de transformation spécifique est utilisée.
Par exemple, la requête SQL suivante est un processus. Cette requête crée une table en comptant le nombre total de trajets pour chaque fournisseur à partir de deux tables sources.
CREATE TABLE `dataplex-docs.data_lineage_demo.total_green_trips_22_21`
AS
SELECT
vendor_id,
COUNT(*) AS number_of_trips
FROM
(
SELECT vendor_id
FROM `dataplex-docs.data_lineage_demo.nyc_green_trips_2022`
UNION ALL
SELECT vendor_id
FROM `dataplex-docs.data_lineage_demo.nyc_green_trips_2021`
)
GROUP BY
vendor_id;
Le format du nom de ressource REST pour un processus est projects/PROJECT_NUMBER/locations/LOCATION/processes/PROCESS_ID.
Par exemple : projects/123456789123/locations/us/processes/sh-0548bbf4ff3c8072a6c7372ba1acafb6
Pour en savoir plus sur la ressource process, consultez la documentation de référence sur la ressource Process.
Exécuter
Une exécution correspond à une seule exécution d'un processus. Les processus peuvent comporter plusieurs exécutions.
Chaque exécution est une opération unique caractérisée par un startTime, un endTime et un état final, tel que COMPLETED, FAILED ou ABORTED.
Par exemple, l'exécution de la requête SQL de la section Processus à 9h00 crée une exécution spécifique. Si vous exécutez à nouveau la même requête à 10h00, une nouvelle exécution distincte est créée. Les deux exécutions sont associées au même processus parent.
Le format du nom de ressource REST pour une exécution indique qu'il s'agit d'un enfant d'un processus :
projects/PROJECT_NUMBER/locations/LOCATION/processes/PROCESS_ID/runs/RUN_ID.
Par exemple : projects/123456789123/locations/us/processes/sh-0548bbf4ff3c8072a6c7372ba1acafb6/runs/83dd03a51cd2ac80f465c9e267a950b1
Pour en savoir plus sur la ressource run, consultez la documentation de référence sur la ressource Run.
Événement
Un événement représente un point dans le temps où une transformation de données déplace des données entre une entité source et une entité cible. Un événement est un enregistrement précis d'un transfert de données spécifique qui relie les tables sources et cibles pour une exécution spécifique. Un événement peut également avoir plusieurs sources et cibles.
Par exemple, si votre exécution exécute la requête SQL décrite dans la section Processus, un événement de lignage enregistre que les tables sources nyc_green_trips_2021 et nyc_green_trips_2022 sont utilisées pour créer la table cible total_green_trips_22_21.
Un événement de lignée contient une liste de liens qui définissent la source et la cible. Les événements sont utilisés pour créer des graphiques de lignée. Bien que la console Google Cloud présente ces graphiques de traçabilité, elle n'affiche pas directement les événements individuels. Vous pouvez créer, lire et supprimer des événements, mais pas les mettre à jour, à l'aide de l'API Data Lineage.
Chaque lien d'un événement définit un chemin unique de flux de données d'une entité source vers une entité cible. Une entité est une référence à un élément de données, tel qu'une table BigQuery, et est identifiée par son nom complet (FQN). Un même événement peut contenir plusieurs liens, ce qui est courant dans les opérations telles que les jointures de tables où plusieurs sources contribuent à une seule cible.
Pour savoir comment les événements sont compatibles avec la traçabilité au niveau des colonnes, consultez Traçabilité au niveau des colonnes.
Précision de la traçabilité
La traçabilité des données vous permet de suivre l'origine et le chemin de transformation de vos données au niveau des tables et des colonnes.
Traçabilité au niveau de la table
La traçabilité au niveau des tables offre une vue d'ensemble de vos pipelines de données en affichant les relations entre les tables entières. Utilisez la traçabilité au niveau des tables pour les tâches de haut niveau, telles que les suivantes :
Découverte des données : Un analyste qui crée un tableau de bord peut utiliser le lineage au niveau des tables pour remonter d'une table récapitulative à ses sources et confirmer que les données proviennent d'une base de données faisant autorité.
Planification de la migration : Un administrateur de base de données qui prévoit de migrer une base de données principale peut utiliser la traçabilité au niveau des tables pour identifier tous les rapports et tableaux de bord en aval qui en dépendent.
Audit et gouvernance. Un responsable des données peut utiliser la traçabilité au niveau des tables et des colonnes pour vérifier comment les données d'une table contenant des informations permettant d'identifier personnellement l'utilisateur circulent dans un pipeline.
Traçabilité au niveau de la colonne
La traçabilité au niveau des colonnes offre une vue plus précise en suivant le flux de données entre les colonnes individuelles. Dans cette vue, les liens d'un événement de lignée représentent la relation entre une colonne source et une colonne cible. Chacun de ces liens au niveau des colonnes possède un type de dépendance qui décrit la transformation :
Exact copy: les valeurs sont copiées entre les colonnes.Other: autres types de dépendances entre les colonnes.
Utilisez le lineage au niveau des colonnes pour effectuer les tâches suivantes :
Analyse des causes fondamentales : Si un analyste de données trouve une valeur incorrecte dans une colonne, il peut utiliser le lineage au niveau des colonnes pour remonter jusqu'aux colonnes sources et trouver la cause première.
Analyse de l'impact : Avant de supprimer une colonne, un ingénieur des données peut utiliser la traçabilité au niveau de la colonne pour trouver toutes les colonnes en aval qui en dépendent.
Vérification de la source de données pour les métriques. Un analyste de données peut utiliser la traçabilité au niveau des colonnes pour identifier les colonnes sources utilisées pour calculer une métrique sans avoir à déchiffrer une requête SQL complexe.
La traçabilité au niveau des colonnes est collectée automatiquement pour les types de jobs BigQuery suivants :
Vues de traçabilité dans la console Google Cloud
La traçabilité des données dans la console Google Cloud vous permet d'interagir avec les informations de traçabilité de deux manières : vous pouvez explorer le graphique de traçabilité dans plusieurs régions disponibles ou utiliser le panneau Explorateur de traçabilité pour obtenir une vue plus ciblée dans une région spécifique. Vous pouvez également basculer entre la vue Graphique et la vue Liste pour analyser le flux de données à différents niveaux de détail.
Les vues de lignage ne sont disponibles que pour les entrées Dataplex Universal Catalog, les composants BigQuery et les ressources Vertex AI (modèles, ensembles de données, vues Feature Store et groupes de caractéristiques).
Pour afficher les différentes vues abordées sur cette page, consultez Utiliser la traçabilité des données avec les systèmes Google Cloud .
Vue Graphique de traçabilité
La vue Graphique permet de visualiser le flux et les relations des composants de données entre les systèmes et les régions. Elle vous aide à comprendre l'architecture des données, à suivre les origines et les destinations, et à identifier les tendances. Ces graphiques de traçabilité, générés par le service API Data Lineage pour une entrée Dataplex Universal Catalog spécifique, montrent comment les données sont transformées au fil du temps. Ils affichent les flux en amont, en aval ou les deux à partir d'une entrée racine sélectionnée.
L'API Data Lineage reçoit automatiquement des informations sur les composants à partir des systèmes compatibles et par le biais d'appels d'API pour les sources personnalisées.
Les éléments clés du graphique sont décrits comme suit :
Nœuds Représentez les entités de données. Dans une vue au niveau de la table, un nœud affiche le nom de la table et ses colonnes. Dans une vue au niveau des colonnes, chaque nœud représente une table et une colonne spécifiques.
Arêtes : Les lignes qui relient les nœuds et représentent les processus qui se produisent entre eux. L'apparence d'un bord dépend de la vue de lignée :
- Dans la vue au niveau du tableau, les arêtes sont associées à des icônes qui indiquent les transformations de données.
- Dans la vue au niveau des colonnes, les arêtes comportent des libellés indiquant les transformations de données. Par exemple, un libellé d'arête peut indiquer
Exact copypour décrire comment une colonne source a été copiée dans une colonne cible.
Icônes et libellés de processus Elles s'affichent sur les bords pour fournir plus d'informations sur la transformation.
- Icônes Représenter le processus de transformation. Lorsque vous explorez manuellement le graphique, les icônes sur les arêtes représentent le système source du processus (par exemple, BigQuery ou Vertex AI). Si plusieurs processus sont impliqués, une icône "Plusieurs processus" s'affiche. Si le système source du processus est inconnu, une icône en forme de roue dentée est utilisée. Lorsque vous appliquez des filtres, une icône en forme de roue dentée est utilisée pour tous les processus.
- Libellés : Dans la vue de traçabilité au niveau des colonnes, un libellé décrit le type de dépendance entre les colonnes :
Exact copyouOther.
Explorer manuellement le graphique de traçabilité
Lorsque vous ouvrez l'onglet Lignée, la vue Graphique par défaut s'affiche. La vue par défaut fournit un aperçu général des systèmes et des régions, avec une expansion manuelle et incrémentielle du graphique qui peut charger cinq nœuds à la fois. Les icônes de processus sur les bords représentent le système source ou indiquent plusieurs processus.
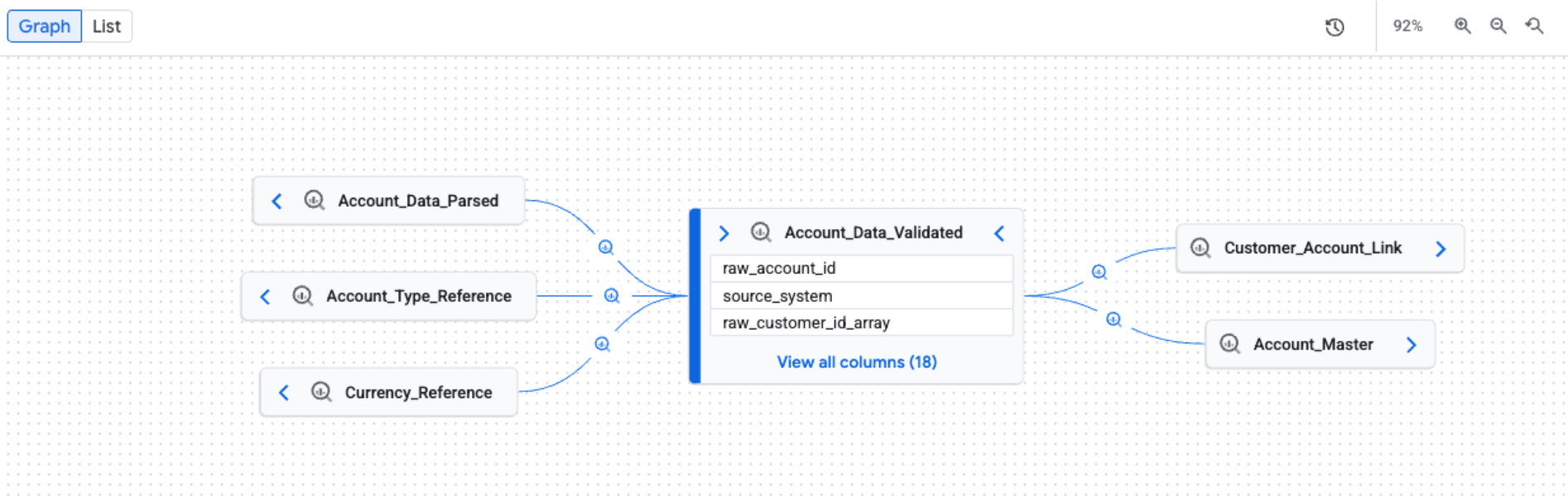
Appliquer des filtres pour une vue ciblée de la lignée
Pour filtrer les données de lignée et effectuer une analyse ciblée dans une région spécifique, utilisez le panneau Explorateur de lignée. Voici quelques critères que vous pouvez utiliser pour passer à une vue concentrée :
- Nom de la colonne : filtrez la traçabilité par nom de colonne pour afficher les détails au niveau de la colonne.
- Direction : affiche la traçabilité en amont, en aval ou les deux.
- Période : filtrez la lignée en fonction d'une heure de début ou de fin spécifique.
- Type de dépendance : filtrez la traçabilité au niveau des colonnes en fonction du type de dépendance.
Par exemple, les options disponibles sont
AllouExact copy.
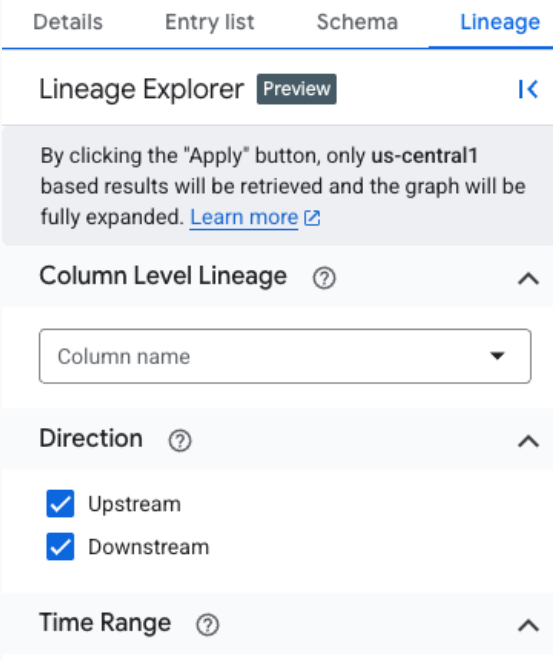
La vue ciblée développe automatiquement le graphique jusqu'à trois niveaux, en chargeant tous les lignages correspondant aux critères de filtrage. Il est compatible avec la traçabilité au niveau des tables et des colonnes, y compris la visualisation du chemin d'accès depuis n'importe quel nœud sélectionné jusqu'à la racine. Dans cette vue ciblée, une icône en forme de roue dentée générique est utilisée pour tous les processus.

Pour afficher la lignée au niveau des colonnes, vous pouvez utiliser l'une des méthodes suivantes :
Dans une vue Graphique ciblée, cliquez sur l'icône Colonne d'un tableau pour passer à la lignée au niveau de la colonne.
Icône Colonne Dans la vue Graphique par défaut ou la vue Graphique ciblée, appliquez un nom de colonne dans le panneau Explorateur de traçabilité.

Pour supprimer tous les filtres et revenir à la vue par défaut, cliquez sur Réinitialiser.
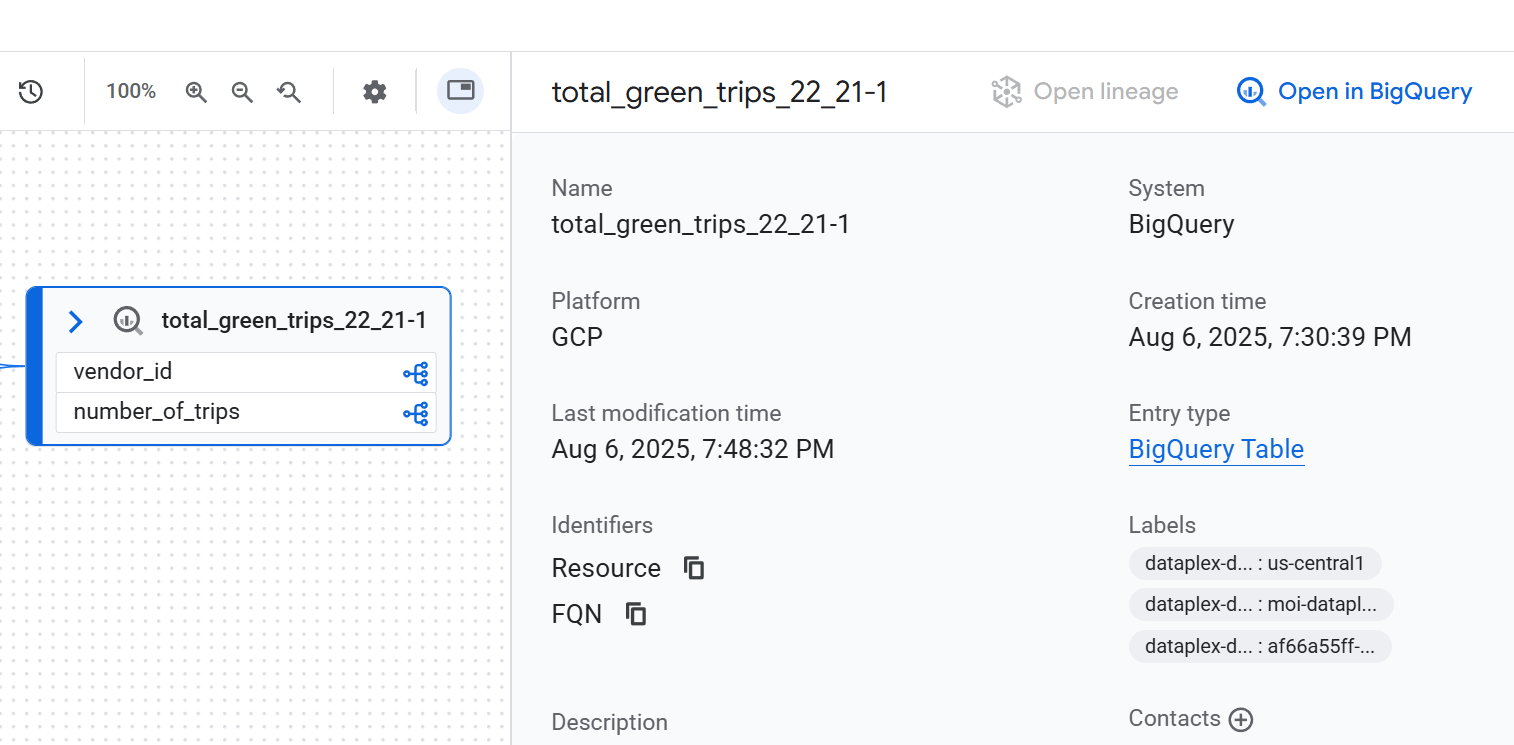
Détails du nœud
Pour afficher les détails d'un nœud, cliquez dessus. Un panneau latéral s'affiche et fournit des informations détaillées sur le composant de données sélectionné. Par exemple, dans une vue de lignée au niveau d'une table, cliquer sur un nœud affiche des informations telles que le nom complet, le type et d'autres attributs pertinents de l'actif.
Audit et historique des exécutions
Un graphique de lignée complet est le résultat d'exécutions de nombreux jobs différents, chaque job créant un lien spécifique dans le graphique. Les exécutions multiples sont consignées en tant que nouvelles exécutions, mais ne modifient pas l'apparence statique du graphique.
Pour afficher les détails de ces exécutions individuelles, cliquez sur un bord avec un processus dans le graphique. Dans le panneau Requête qui s'affiche, cliquez sur l'onglet Exécutions.

Inspecter la logique de transformation
Pour comprendre la logique métier d'une transformation sans rechercher le code, vous pouvez afficher la requête SQL exacte qui a été exécutée. Pour afficher le code SQL, cliquez sur un bord avec un processus dans le graphique. Dans le panneau latéral qui s'affiche, cliquez sur l'onglet Détails.
Visualisation du chemin de traçabilité
La visualisation du chemin de traçabilité vous aide à retracer le chemin depuis n'importe quel nœud sélectionné dans le graphique jusqu'à l'entrée racine. Lorsque vous sélectionnez un nœud et cliquez sur Visualiser le chemin, le graphique ne met en évidence que les nœuds et les processus qui forment le chemin de lignée direct vers l'entrée racine.
Pour afficher la visualisation du chemin de lignée, appliquez un filtre dans le panneau Explorateur de lignée afin de créer une vue Graphique ciblée. Ensuite, dans la vue Graphique, sélectionnez un nœud. Dans le panneau de détails du nœud sélectionné, cliquez sur Visualiser le chemin.
La visualisation du chemin de traçabilité est disponible pour la traçabilité au niveau des tables et des colonnes. Vous pouvez également utiliser la visualisation du chemin de traçabilité dans la vue Liste.
Affichage de la traçabilité sous forme de liste
La vue Liste offre une représentation tabulaire et structurée de la lignée, synchronisée avec la vue Graphique. Il facilite le tri, le filtrage et le téléchargement des composants de données. Cette vue est idéale pour analyser les relations source-cible, détailler les composants concernés et exporter les données de traçabilité.
La vue Liste est disponible pour la traçabilité au niveau des tables et des colonnes. Vous pouvez basculer entre les vues détaillées et simplifiées suivantes.
Vue liste simplifiée : cette vue est utile pour obtenir une liste unique et condensée de tous les composants impliqués dans la traçabilité. Les colonnes telles que Système, Projet, Entité, Nom complet, Direction et Profondeur vous aident à afficher tous les éléments de données dans l'arborescence, leur emplacement, leur source d'origine et leur distance par rapport à l'élément central analysé. Il est idéal pour obtenir une vue d'ensemble de toutes les entités participant au flux de données. Il s'agit de la vue par défaut.
Vue détaillée : cette vue est conçue pour analyser les relations source-cible individuelles. En fournissant des colonnes distinctes pour Source et Cible, vous pouvez voir chaque lien de transformation de données spécifique. Cette vue est idéale pour les tâches qui nécessitent une compréhension approfondie de la façon dont les données circulent entre des paires spécifiques d'éléments, comme l'audit des flux de données individuels, la compréhension des dépendances entre les tables ou l'exportation d'enregistrements détaillés de l'héritage pour chaque connexion.
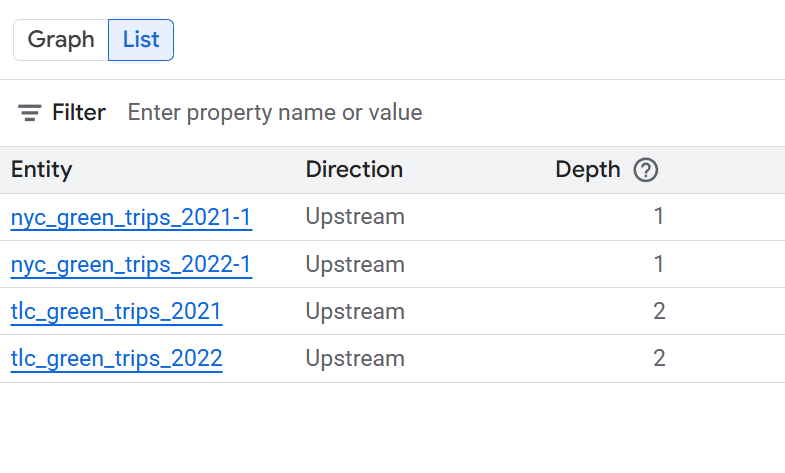
Vue Liste de la traçabilité au niveau de la table
Cette vue montre les relations entre les tables dans leur ensemble. Utilisez les filtres fournis pour sélectionner les colonnes dont vous avez besoin.
Développez les sections suivantes pour afficher les colonnes disponibles dans les vues Liste au niveau du tableau.
Colonnes disponibles dans la vue Liste simplifiée au niveau des tables
- Système : système dans lequel se trouve l'élément de données. Par exemple, BigQuery.
- Projet : ID du projet Google Cloud contenant le composant de données.
- Entité : nom du composant de données. Les exemples incluent un nom de table.
- FQN : nom complet (FQN) de l'entité ou de la colonne source d'origine.
- Direction : indique si le composant listé est en amont (source) ou en aval (cible) dans le flux de traçabilité.
- Profondeur : nombre d'étapes de lignée à partir de l'élément central analysé.
Colonnes disponibles dans la vue Liste détaillée au niveau des tables
- Système source : système dans lequel se trouve l'élément de données source. Par exemple, BigQuery.
- Projet source : ID du projet Google Cloud contenant le composant de données source.
- Source : nom de l'élément de données source. Par exemple, un nom de table.
- Nom complet de la source : nom complet de l'entité source.
- Système cible : système dans lequel se trouve l'élément de données cible. Par exemple, BigQuery.
- Projet cible : ID du projet Google Cloud contenant le composant de données cible.
- Cible : nom du composant de données cible. Par exemple, un nom de table.
- Nom complet de la cible : nom complet de l'entité cible.
- Direction : indique si le composant listé est en amont (source) ou en aval (cible) dans le flux de traçabilité.
- Profondeur : nombre d'étapes de lignée à partir de l'élément central analysé.
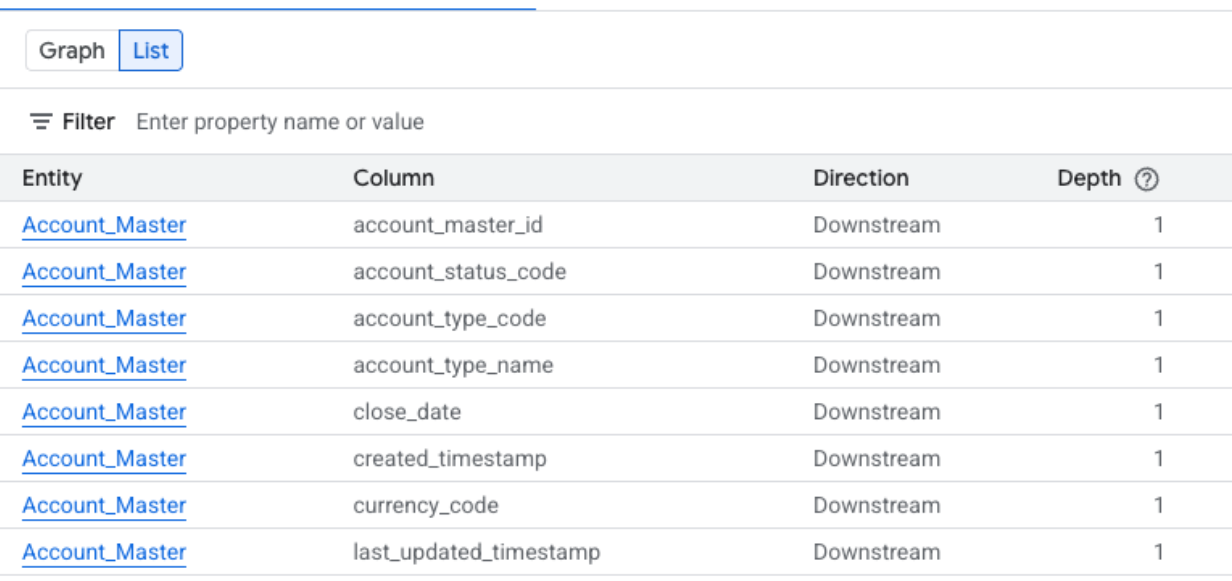
Vue Liste de la traçabilité au niveau des colonnes
Cette vue affiche les relations entre les colonnes individuelles des tables sources et cibles. Utilisez les filtres fournis pour sélectionner les colonnes dont vous avez besoin.
Développez les sections suivantes pour afficher les colonnes disponibles dans les vues de liste au niveau des colonnes.
Colonnes disponibles dans la vue Liste simplifiée au niveau des colonnes
- Système : système dans lequel se trouve l'élément de données. Par exemple, BigQuery.
- Projet : ID du projet Google Cloud contenant le composant de données.
- Entité : nom du composant de données. Les exemples incluent un nom de table.
- Colonne : colonne spécifique choisie dans le panneau Explorateur de traçabilité de l'entité.
- FQN : nom complet (FQN) de l'entité ou de la colonne source d'origine.
- Direction : indique si le composant listé est en amont (source) ou en aval (cible) dans le flux de traçabilité.
- Profondeur : nombre d'étapes de lignée à partir de l'élément central analysé.
Colonnes disponibles dans la vue Liste détaillée au niveau des colonnes
- Système source : système dans lequel se trouve l'élément de données source.
- Projet source : ID du projet Google Cloud contenant le composant de données source.
- Nom complet de la source : nom complet de la colonne source.
- Système cible : système dans lequel se trouve l'élément de données cible.
- Projet cible : ID du projet Google Cloud contenant le composant de données cible.
- Nom complet de la cible : nom complet de la colonne cible.
- Direction : indique si le flux de données est en amont ou en aval.
- Types de dépendances : décrit la nature de la relation entre les colonnes.
- Profondeur : nombre d'étapes de lignée à partir de l'élément central analysé.
Étapes suivantes
En savoir plus sur les sources de traçabilité
Découvrez comment suivre la traçabilité des données pour une copie de table BigQuery et des jobs de requête.
Découvrez comment utiliser la traçabilité des données avec les systèmes Google Cloud .