El linaje de datos te ayuda a comprender cómo se mueven los datos a través de tus sistemas haciendo un seguimiento de las relaciones entre los activos de datos y los procesos que los transforman. Puedes ver esta información de linaje como gráficos y listas en la consola de Google Cloud .
En este documento, se proporciona una descripción general del modelo de información del linaje de datos, detalles sobre la granularidad del linaje a nivel de tabla y columna, y se incluyen instrucciones para usar las vistas de gráfico y de lista para explorar el linaje de datos.
Modelo de información del linaje de datos
El linaje es un registro de los datos que se transforman de las fuentes a los destinos. La API de Data Lineage recopila esta información y la organiza en un modelo de datos jerárquico que usa los conceptos de procesos, ejecuciones y eventos.
- Proceso: Es una definición de transformación de datos.
- Ejecución: Es la realización de un proceso.
- Evento: Es un registro del movimiento de datos durante una ejecución.
Proceso
Un proceso es la definición de una operación de transformación de datos para un sistema específico. En el linaje de BigQuery, un proceso es un trabajo de un tipo de trabajo admitido. Todas las ejecuciones de la misma consulta en SQL se vinculan a un solo proceso, lo que te permite hacer un seguimiento de cada instancia en la que se usa una lógica de transformación específica.
Por ejemplo, la siguiente consulta en SQL es un proceso. Esta consulta crea una tabla que cuenta la cantidad total de viajes para cada proveedor a partir de dos tablas de origen.
CREATE TABLE `dataplex-docs.data_lineage_demo.total_green_trips_22_21`
AS
SELECT
vendor_id,
COUNT(*) AS number_of_trips
FROM
(
SELECT vendor_id
FROM `dataplex-docs.data_lineage_demo.nyc_green_trips_2022`
UNION ALL
SELECT vendor_id
FROM `dataplex-docs.data_lineage_demo.nyc_green_trips_2021`
)
GROUP BY
vendor_id;
El formato del nombre del recurso REST para un proceso es projects/PROJECT_NUMBER/locations/LOCATION/processes/PROCESS_ID.
Por ejemplo: projects/123456789123/locations/us/processes/sh-0548bbf4ff3c8072a6c7372ba1acafb6
Para obtener más información sobre el recurso process, consulta la referencia del recurso Process.
Ejecutar
Una ejecución es una sola ejecución de un proceso. Los procesos pueden tener varias ejecuciones.
Cada ejecución es una operación única caracterizada por un startTime, un endTime y un estado final, como COMPLETED, FAILED o ABORTED.
Por ejemplo, ejecutar la consulta en SQL de la sección Proceso a las 9:00 a.m. crea una ejecución específica. Si vuelves a ejecutar la misma consulta a las 10 a.m., se creará una ejecución nueva y distinta. Ambas ejecuciones están vinculadas al mismo proceso principal.
El formato del nombre del recurso de REST para una ejecución muestra que es secundario de un proceso: projects/PROJECT_NUMBER/locations/LOCATION/processes/PROCESS_ID/runs/RUN_ID.
Por ejemplo: projects/123456789123/locations/us/processes/sh-0548bbf4ff3c8072a6c7372ba1acafb6/runs/83dd03a51cd2ac80f465c9e267a950b1
Para obtener más información sobre el recurso run, consulta la referencia del recurso Run.
Evento
Un evento representa un punto en el tiempo en el que una transformación de datos mueve datos entre una entidad de origen y una de destino. Un evento es un registro detallado de un movimiento de datos específico que conecta las tablas de origen y destino para una ejecución específica. Un evento también puede tener varias fuentes y destinos.
Por ejemplo, si tu ejecución ejecuta la consulta en SQL que se analizó en la sección Proceso, un evento de linaje registrará que las tablas de origen nyc_green_trips_2021 y nyc_green_trips_2022 se usan para crear la tabla de destino total_green_trips_22_21.
Un evento de linaje contiene una lista de vínculos que definen la fuente y el destino. Los eventos se usan para crear gráficos de linaje. Si bien la consola de Google Cloud presenta estos gráficos de linaje, no muestra directamente los eventos individuales. Puedes crear, leer y borrar eventos, pero no actualizarlos, con la API de Data Lineage.
Cada vínculo dentro de un evento define una sola ruta de flujo de datos desde una entidad de origen a una entidad de destino. Una entidad es una referencia a un activo de datos, como una tabla de BigQuery, y se identifica por su nombre completamente calificado (FQN). Un solo evento puede contener varios vínculos, lo que es común en operaciones como las uniones de tablas, en las que varias fuentes contribuyen a un solo destino.
Para obtener detalles sobre cómo los eventos admiten el linaje a nivel de columna, consulta Linaje a nivel de columna.
Nivel de detalle del linaje
El linaje de datos te permite rastrear el origen y la ruta de transformación de tus datos a nivel de tabla y columna.
Linaje a nivel de tabla
El linaje a nivel de la tabla proporciona una descripción general de alto nivel de tus canalizaciones de datos, ya que muestra las relaciones entre tablas completas. Usa el linaje a nivel de la tabla para tareas a nivel macro, como las siguientes:
Descubrimiento de datos: Un analista que crea un panel nuevo puede usar el linaje a nivel de la tabla para rastrear una tabla de resumen hasta sus fuentes y confirmar que los datos provienen de una base de datos autorizada.
Planificación de la migración. Un administrador de bases de datos que planea migrar una base de datos principal puede usar el linaje a nivel de la tabla para identificar cada informe y panel descendente que dependa de ella.
Auditoría y administración. Un administrador de datos puede usar el linaje a nivel de tabla y columna para verificar cómo fluyen los datos de una tabla que contiene información de identificación personal (PII) a través de una canalización.
Linaje a nivel de columna
El linaje a nivel de columna proporciona una vista más detallada, ya que hace un seguimiento del flujo de datos entre columnas individuales. En esta vista, los vínculos dentro de un evento de linaje representan la relación entre una columna de origen y una columna de destino. Cada uno de estos vínculos a nivel de la columna tiene un tipo de dependencia que describe la transformación:
Exact copy: Los valores se copian entre columnas.Other: Otros tipos de dependencias entre columnas.
Usa el linaje a nivel de la columna para tareas como las siguientes:
Análisis de la causa raíz Si un analista de datos encuentra un valor incorrecto en una columna, puede usar el linaje a nivel de la columna para rastrearlo hasta las columnas de origen y encontrar la causa raíz.
Análisis del impacto: Antes de que un ingeniero de datos deje de usar una columna, puede usar el linaje a nivel de la columna para encontrar cada columna descendiente que dependa de ella.
Verificación de la fuente de datos para las métricas. Un analista de datos puede usar el linaje a nivel de la columna para identificar qué columnas de origen se usan para calcular una métrica sin tener que descifrar una consulta en SQL compleja.
El linaje a nivel de la columna se recopila automáticamente para los siguientes tipos de trabajos de BigQuery:
Vistas de linaje en la consola de Google Cloud
El linaje de datos en la consola de Google Cloud te permite interactuar con la información del linaje de dos maneras: puedes explorar el gráfico de linaje en varias regiones disponibles o usar el panel del Explorador de linaje para obtener una vista más enfocada dentro de una región específica. También puedes alternar entre la vista de gráfico y la vista de lista para analizar el flujo de datos en diferentes niveles de detalle.
Las vistas de linaje solo están disponibles para las entradas de Dataplex Universal Catalog, los recursos de BigQuery y los recursos de Vertex AI (modelos, conjuntos de datos, vistas de almacén de atributos y grupos de atributos).
Para ver las diferentes vistas que se analizan en esta página, consulta Cómo usar el linaje de datos con sistemas de Google Cloud .
Vista del gráfico de linaje
La vista Gráfico visualiza el flujo y las relaciones de los activos de datos en los sistemas y las regiones, lo que te ayuda a comprender la arquitectura de datos, rastrear los orígenes y los destinos, y a identificar patrones. Estos gráficos de linaje, generados por el servicio de la API de Data Lineage para una entrada específica del catálogo universal de Dataplex, muestran cómo se transforman los datos con el tiempo y muestran los flujos upstream, downstream o ambos desde una entrada raíz seleccionada.
La API de Data Lineage recibe automáticamente información de los recursos de los sistemas compatibles y a través de llamadas a la API para fuentes personalizadas.
Los elementos clave del gráfico se describen a continuación:
Nodos: Representar las entidades de datos En una vista a nivel de la tabla, un nodo muestra el nombre de la tabla y sus columnas. En una vista a nivel de la columna, cada nodo representa una tabla y una columna específicas.
Bordes. Son las líneas que conectan los nodos y representan los procesos que ocurren entre ellos. La apariencia de una arista depende de la vista de linaje:
- En la vista a nivel de la tabla, las aristas tienen íconos que indican las transformaciones de datos.
- En la vista a nivel de la columna, las aristas tienen etiquetas para indicar las transformaciones de datos. Por ejemplo, una etiqueta de borde podría decir
Exact copypara describir cómo se copió una columna de origen a una columna de destino.
Procesa íconos y etiquetas. Aparecen en los bordes para proporcionar más información sobre la transformación.
- Íconos: Representar el proceso de transformación Cuando exploras el gráfico de forma manual, los íconos en los bordes representan el sistema fuente del proceso (por ejemplo, BigQuery o Vertex AI). Si hay varios procesos involucrados, se muestra un ícono de "varios procesos". Si se desconoce el sistema fuente del proceso, se usa un ícono de engranaje. Cuando aplicas filtros, se usa un ícono de engranaje para todos los procesos.
- Etiquetas. En la vista de linaje a nivel de columna, una etiqueta describe el tipo de dependencia entre las columnas:
Exact copyoOther.
Explora el gráfico de linaje de forma manual
Cuando abres la pestaña Linaje, ves la vista predeterminada Gráfico. La vista predeterminada proporciona una descripción general de alto nivel en todos los sistemas y regiones, con una expansión manual e incremental del gráfico que puede cargar cinco nodos a la vez. Los íconos de proceso en los bordes representan el sistema fuente o indican múltiples procesos.
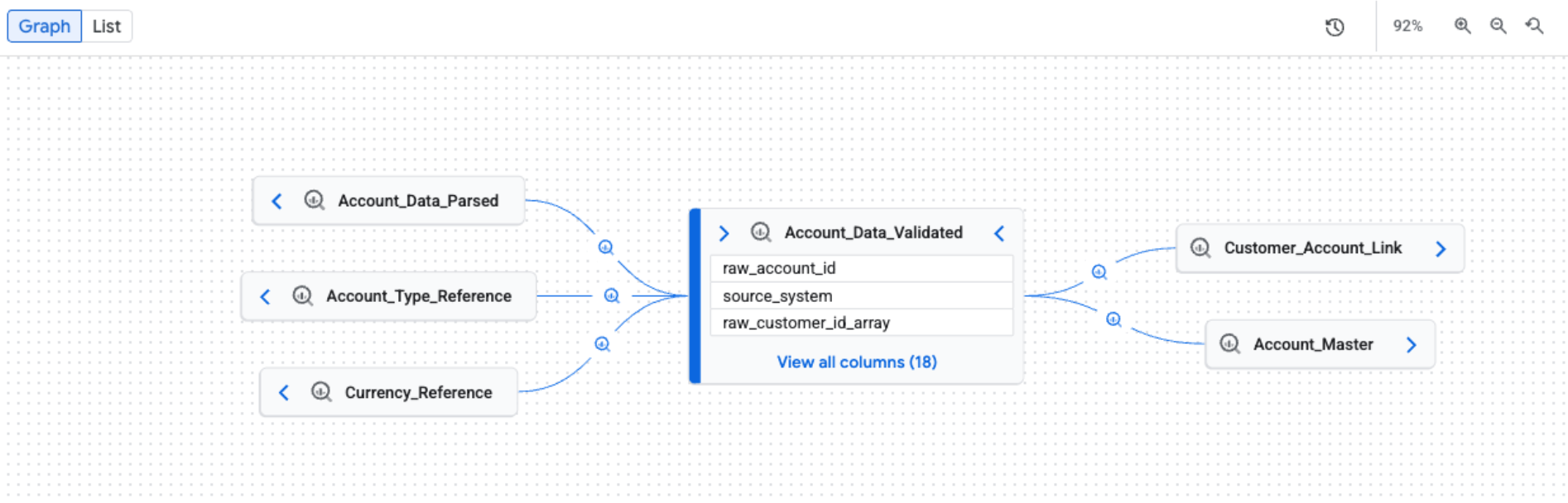
Aplica filtros para obtener una vista enfocada del linaje
Para filtrar los datos de linaje y realizar un análisis enfocado en una región específica, usa el panel del Explorador de linaje. Estos son algunos criterios que puedes usar para cambiar a una vista enfocada:
- Nombre de la columna: Filtra el linaje por nombre de columna para ver los detalles a nivel de la columna.
- Dirección: Muestra el linaje ascendente o descendente, o ambos.
- Intervalo de tiempo: Filtra el linaje según una hora de inicio o finalización específica.
- Tipo de dependencia: Filtra el linaje a nivel de la columna según el tipo de dependencia.
Entre los ejemplos de opciones disponibles, se incluyen
AlloExact copy.
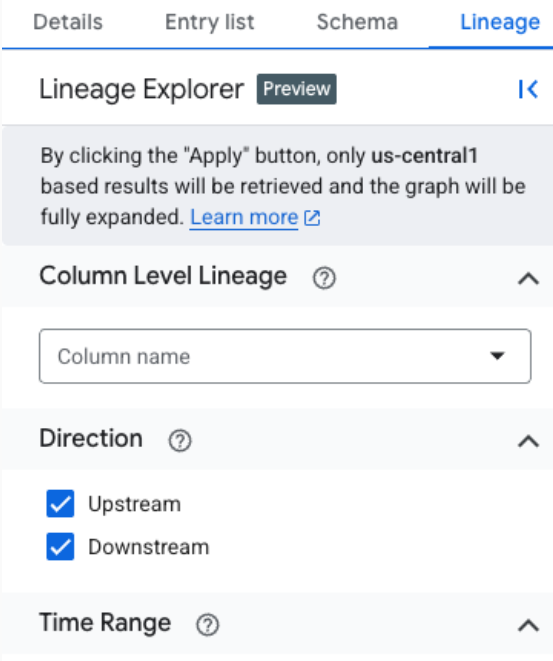
La vista enfocada expande automáticamente el gráfico hasta tres niveles y carga todo el linaje que coincide con los criterios de filtrado. Admite el linaje a nivel de la tabla y de la columna, incluida la visualización de la ruta desde cualquier nodo seleccionado hasta la raíz. En esta vista enfocada, se usa un ícono de engranaje genérico para todos los procesos.

Para ver el linaje a nivel de la columna, puedes seguir uno de los siguientes métodos:
En una vista de gráfico enfocada, haz clic en el ícono de columna de una tabla para cambiar al linaje a nivel de la columna.
Ícono de columna En la vista Gráfico predeterminada o enfocada, aplica un nombre de columna en el panel Explorador de linaje.

Para quitar todos los filtros y volver a la vista predeterminada, haz clic en restablecer.
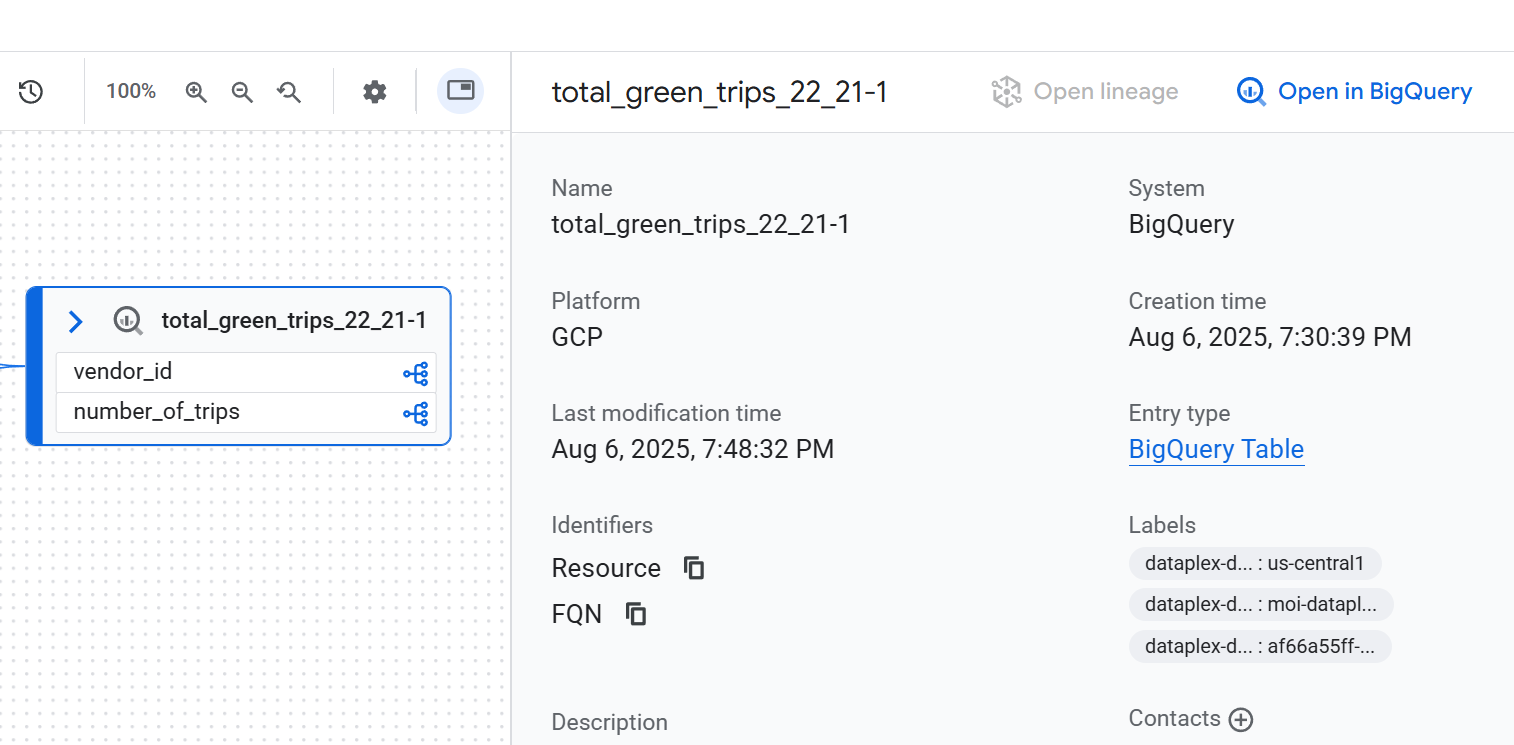
Detalles del nodo
Para ver los detalles de un nodo, haz clic en él. Aparecerá un panel lateral en el que se muestra información detallada sobre el activo de datos seleccionado. Por ejemplo, en una vista del linaje a nivel de la tabla, hacer clic en un nodo muestra información como el nombre completamente calificado, el tipo y otros atributos relevantes del activo.
Historial y auditoría de ejecuciones
Un gráfico de linaje completo es el resultado de las ejecuciones de muchos trabajos diferentes, y cada trabajo crea un vínculo específico en el gráfico. Se registran varias ejecuciones como ejecuciones nuevas, pero no cambian la apariencia estática del gráfico.
Para ver los detalles de estas ejecuciones individuales, haz clic en una arista con un proceso en el gráfico. En el panel Consulta que aparece, haz clic en la pestaña Ejecuciones.

Cómo inspeccionar la lógica de transformación
Para comprender la lógica empresarial de una transformación sin buscar el código, puedes ver la consulta en SQL exacta que se ejecutó. Para ver el código SQL, haz clic en una arista con un proceso en el gráfico. En el panel lateral que aparece, haz clic en la pestaña Detalles.
Visualización de la ruta de linaje
La visualización de la ruta de linaje te ayuda a rastrear la ruta desde cualquier nodo seleccionado en el gráfico hasta la entrada raíz. Cuando seleccionas un nodo y haces clic en Visualizar ruta, el grafo destaca solo los nodos y procesos que forman la ruta de linaje directa hacia la entrada raíz.
Para ver la visualización de la ruta de linaje, en el panel Explorador de linaje, aplica un filtro para crear una vista enfocada del gráfico. Luego, en la vista enfocada Graph, selecciona un nodo. En el panel de detalles del nodo seleccionado, haz clic en Visualizar ruta.
La visualización de la ruta de linaje está disponible para el linaje a nivel de la tabla y de la columna. También puedes usar la visualización de la ruta de linaje en la vista de lista.
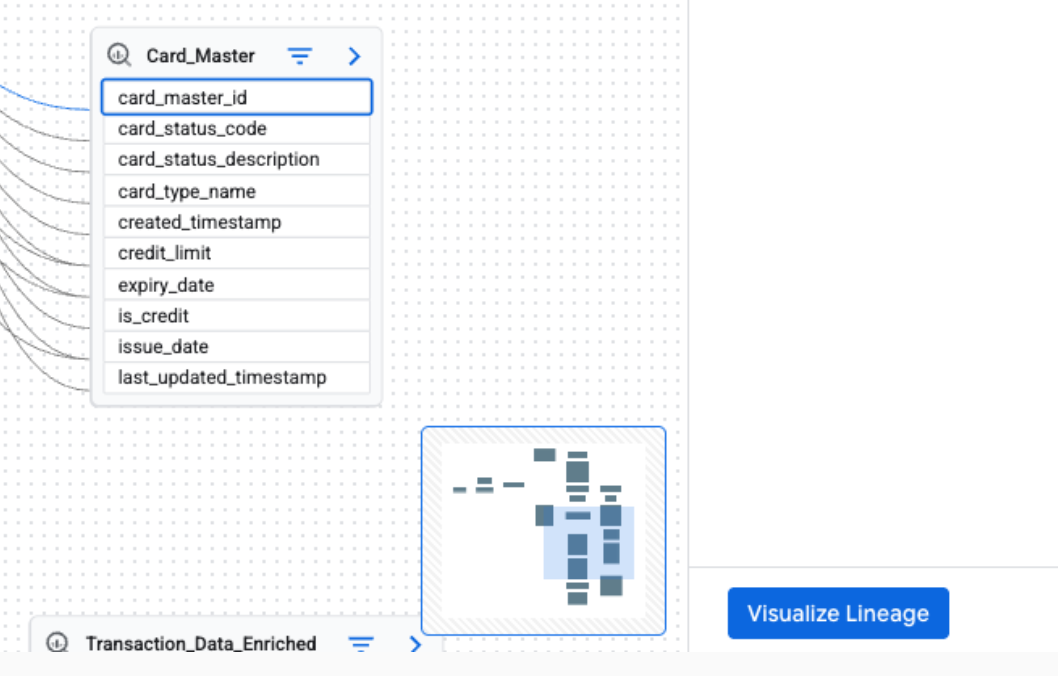
Vista de lista de linaje
La vista de Lista ofrece una representación tabular y estructurada del linaje, sincronizada con la vista de Gráfico. Facilita la ordenación, el filtrado y la descarga de activos de datos. Esta vista es ideal para analizar las relaciones entre la fuente y el destino, detallar los recursos involucrados y exportar los datos de linaje.
La vista de lista está disponible para el linaje a nivel de la tabla y de la columna. Puedes alternar entre las siguientes vistas de lista detalladas y simplificadas.
Vista de lista simplificada: Esta vista es útil para obtener una lista condensada y única de todos los recursos involucrados en el linaje. Las columnas como Sistema, Proyecto, Entidad, FQN (nombre completamente calificado), Dirección y Profundidad te ayudan a ver todos los recursos de datos en el linaje, dónde residen, su fuente original y su distancia del recurso central que se analiza. Es ideal para obtener una descripción general de alto nivel de todas las entidades que participan en el flujo de datos. Es la vista predeterminada.
Vista de lista detallada: Esta vista está diseñada para analizar las relaciones individuales entre la fuente y el destino. Si proporcionas columnas separadas para Fuente y Destino, puedes ver cada vínculo de transformación de datos específico. Esta vista es ideal para tareas que requieren una comprensión profunda de cómo se mueven los datos entre pares específicos de recursos, como auditar flujos de datos individuales, comprender las dependencias entre las tablas o exportar registros de linaje detallados para cada conexión.
Vista de lista del linaje a nivel de la tabla
En esta vista, se muestran las relaciones entre las tablas en su totalidad. Usa los filtros proporcionados para seleccionar las columnas que necesitas.
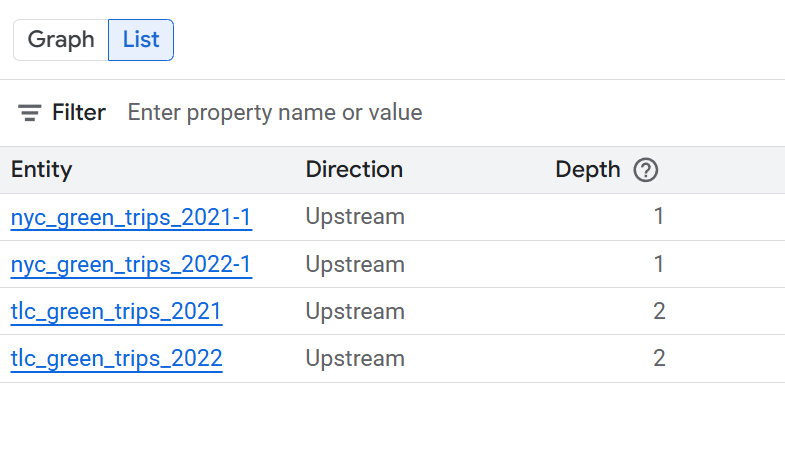
Expande las siguientes secciones para ver las columnas disponibles en las vistas de lista a nivel de la tabla.
Columnas disponibles en la vista de lista simplificada a nivel de la tabla
- Sistema: Es el sistema en el que se encuentra el recurso de datos. Algunos ejemplos son BigQuery.
- Proyecto: Es el ID del proyecto Google Cloud que contiene el activo de datos.
- Entidad: Es el nombre del recurso de datos. Los ejemplos incluyen un nombre de tabla.
- FQN: Es el nombre completamente calificado (FQN) de la entidad o columna de la fuente original.
- Dirección: Indica si el recurso que se muestra en la lista es upstream (fuente) o downstream (destino) en el flujo de linaje.
- Profundidad: Es la cantidad de pasos de linaje desde el recurso central que se analiza.
Columnas disponibles en la vista de lista detallada a nivel de la tabla
- Sistema de origen: Es el sistema en el que se encuentra el recurso de datos de origen. Algunos ejemplos son BigQuery.
- Proyecto de origen: ID del proyecto que contiene el activo de datos de origen Google Cloud
- Fuente: Es el nombre del recurso de datos de origen. Los ejemplos incluyen el nombre de una tabla.
- FQDN de origen: Es el FQDN de la entidad de origen.
- Sistema de destino: Es el sistema en el que se encuentra el recurso de datos de destino. Algunos ejemplos son BigQuery.
- Proyecto de destino: ID del proyecto Google Cloud que contiene el activo de datos de destino.
- Destino: Es el nombre del recurso de datos de destino. Los ejemplos incluyen el nombre de una tabla.
- FQDN de destino: Es el FQDN de la entidad de destino.
- Dirección: Indica si el recurso que se muestra en la lista es upstream (fuente) o downstream (destino) en el flujo de linaje.
- Profundidad: Es la cantidad de pasos de linaje desde el recurso central que se analiza.
Vista de lista del linaje a nivel de columna
En esta vista, se muestran las relaciones entre las columnas individuales de las tablas de origen y destino. Usa los filtros proporcionados para seleccionar las columnas que necesitas.
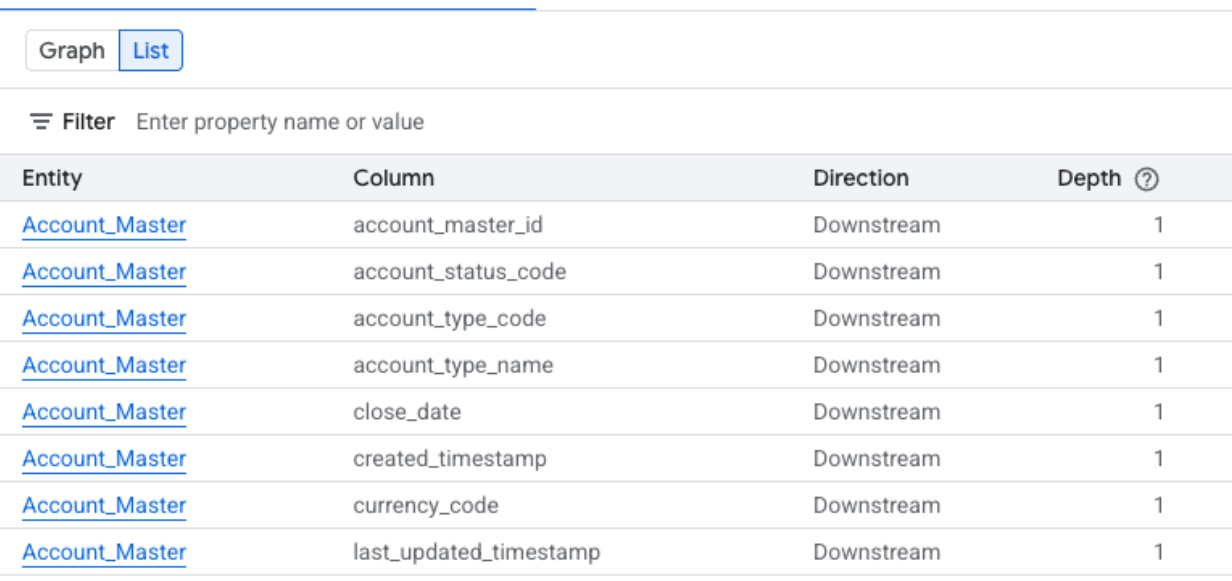
Expande las siguientes secciones para ver las columnas disponibles en las vistas de lista a nivel de la columna.
Columnas disponibles en la vista de lista simplificada a nivel de la columna
- Sistema: Es el sistema en el que se encuentra el recurso de datos. Algunos ejemplos son BigQuery.
- Proyecto: Es el ID del proyecto Google Cloud que contiene el activo de datos.
- Entidad: Es el nombre del recurso de datos. Los ejemplos incluyen un nombre de tabla.
- Columna: Es la columna específica elegida en el panel Lineage Explorer dentro de la entidad.
- FQN: Es el nombre completamente calificado (FQN) de la entidad o columna de la fuente original.
- Dirección: Indica si el recurso que se muestra en la lista es upstream (fuente) o downstream (destino) en el flujo de linaje.
- Profundidad: Es la cantidad de pasos de linaje desde el recurso central que se analiza.
Columnas disponibles en la vista de lista detallada a nivel de columna
- Sistema de origen: Es el sistema en el que se encuentra el recurso de datos de origen.
- Proyecto de origen: ID del proyecto que contiene el activo de datos de origen. Google Cloud
- FQDN de origen: Es el FQDN de la columna de origen.
- Sistema de destino: Es el sistema en el que se encuentra el recurso de datos de destino.
- Proyecto de destino: Es el ID del proyecto Google Cloud que contiene el recurso de datos de destino.
- FQDN de destino: Es el FQDN de la columna objetivo.
- Dirección: Indica si el flujo de datos es upstream o downstream.
- Tipos de dependencia: Describe la naturaleza de la relación entre las columnas.
- Profundidad: Es la cantidad de pasos de linaje desde el recurso central que se analiza.
¿Qué sigue?
Obtén más información sobre las fuentes de linaje.
Obtén información para usar el linaje de datos con sistemas de Google Cloud .