이 문서에서는 Dataplex 범용 카탈로그 Explore를 사용하여 소매업 거래 데이터 세트에서 이상치를 감지하는 방법을 설명합니다.
데이터 탐색 워크벤치 또는 Explore를 통해 데이터 분석가는 실시간 대화형으로 대규모 데이터 세트를 쿼리하고 탐색할 수 있습니다. Explore를 사용하면 데이터에서 유용한 정보를 얻고 Cloud Storage 및 BigQuery에 저장된 데이터를 쿼리할 수 있습니다. Explore에는 서버리스 Spark 플랫폼이 사용되므로 기본 인프라를 관리하고 확장할 필요가 없습니다.
목표
이 튜토리얼에서는 다음 작업을 완료하는 방법을 보여줍니다.
- Explore의 Spark SQL 워크벤치를 사용하여 Spark SQL 쿼리를 작성하고 실행합니다.
- JupyterLab 노트북을 사용하여 결과를 확인합니다.
- 데이터 이상치를 모니터링할 수 있도록 노트북이 반복 실행되도록 예약합니다.
비용
이 문서에서는 비용이 청구될 수 있는 다음과 같은 Google Cloud구성요소를 사용합니다.
프로젝트 사용량을 기준으로 예상 비용을 산출하려면 가격 계산기를 사용합니다.
이 문서에 설명된 태스크를 완료했으면 만든 리소스를 삭제하여 청구가 계속되는 것을 방지할 수 있습니다. 자세한 내용은 삭제를 참조하세요.
시작하기 전에
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
Install the Google Cloud CLI.
-
If you're using an external identity provider (IdP), you must first sign in to the gcloud CLI with your federated identity.
-
To initialize the gcloud CLI, run the following command:
gcloud init -
Create or select a Google Cloud project.
-
Create a Google Cloud project:
gcloud projects create PROJECT_ID
Replace
PROJECT_IDwith a name for the Google Cloud project you are creating. -
Select the Google Cloud project that you created:
gcloud config set project PROJECT_ID
Replace
PROJECT_IDwith your Google Cloud project name.
-
-
Make sure that billing is enabled for your Google Cloud project.
-
Install the Google Cloud CLI.
-
If you're using an external identity provider (IdP), you must first sign in to the gcloud CLI with your federated identity.
-
To initialize the gcloud CLI, run the following command:
gcloud init -
Create or select a Google Cloud project.
-
Create a Google Cloud project:
gcloud projects create PROJECT_ID
Replace
PROJECT_IDwith a name for the Google Cloud project you are creating. -
Select the Google Cloud project that you created:
gcloud config set project PROJECT_ID
Replace
PROJECT_IDwith your Google Cloud project name.
-
-
Make sure that billing is enabled for your Google Cloud project.
탐색 분석을 위한 데이터 준비
Parquet 파일
retail_offline_sales_march를 다운로드합니다.다음과 같이
offlinesales_curated라는 Cloud Storage 버킷을 만듭니다.- In the Google Cloud console, go to the Cloud Storage Buckets page.
- Click Create.
- On the Create a bucket page, enter your bucket information. To go to the next
step, click Continue.
-
In the Get started section, do the following:
- Enter a globally unique name that meets the bucket naming requirements.
- To add a
bucket label,
expand the Labels section (),
click add_box
Add label, and specify a
keyand avaluefor your label.
-
In the Choose where to store your data section, do the following:
- Select a Location type.
- Choose a location where your bucket's data is permanently stored from the Location type drop-down menu.
- If you select the dual-region location type, you can also choose to enable turbo replication by using the relevant checkbox.
- To set up cross-bucket replication, select
Add cross-bucket replication via Storage Transfer Service and
follow these steps:
Set up cross-bucket replication
- In the Bucket menu, select a bucket.
In the Replication settings section, click Configure to configure settings for the replication job.
The Configure cross-bucket replication pane appears.
- To filter objects to replicate by object name prefix, enter a prefix that you want to include or exclude objects from, then click Add a prefix.
- To set a storage class for the replicated objects, select a storage class from the Storage class menu. If you skip this step, the replicated objects will use the destination bucket's storage class by default.
- Click Done.
-
In the Choose how to store your data section, do the following:
- Select a default storage class for the bucket or Autoclass for automatic storage class management of your bucket's data.
- To enable hierarchical namespace, in the Optimize storage for data-intensive workloads section, select Enable hierarchical namespace on this bucket.
- In the Choose how to control access to objects section, select whether or not your bucket enforces public access prevention, and select an access control method for your bucket's objects.
-
In the Choose how to protect object data section, do the
following:
- Select any of the options under Data protection that you
want to set for your bucket.
- To enable soft delete, click the Soft delete policy (For data recovery) checkbox, and specify the number of days you want to retain objects after deletion.
- To set Object Versioning, click the Object versioning (For version control) checkbox, and specify the maximum number of versions per object and the number of days after which the noncurrent versions expire.
- To enable the retention policy on objects and buckets, click the Retention (For compliance) checkbox, and then do the following:
- To enable Object Retention Lock, click the Enable object retention checkbox.
- To enable Bucket Lock, click the Set bucket retention policy checkbox, and choose a unit of time and a length of time for your retention period.
- To choose how your object data will be encrypted, expand the Data encryption section (), and select a Data encryption method.
- Select any of the options under Data protection that you
want to set for your bucket.
-
In the Get started section, do the following:
- Click Create.
파일 시스템에서 객체 업로드의 단계에 따라 다운로드한
offlinesales_march_parquet파일을 사용자가 만든offlinesales_curatedCloud Storage 버킷으로 업로드합니다.레이크 만들기의 단계에 따라 Dataplex 범용 카탈로그 레이크를 만들고 이름을
operations로 지정합니다.영역 추가의 단계에 따라
operations레이크에서 영역을 추가하고 이름을procurement로 지정합니다.애셋 추가의 단계에 따라
procurement영역에서 사용자가 만든offlinesales_curatedCloud Storage 버킷을 애셋으로 추가합니다.
탐색할 테이블 선택
Google Cloud 콘솔에서 Dataplex 범용 카탈로그 탐색 페이지로 이동합니다.
레이크 필드에서
operations레이크를 선택합니다.operations레이크를 클릭합니다.procurement영역으로 이동하고 테이블을 클릭하여 메타데이터를 탐색합니다.다음 이미지에는 선택한 조달 영역에
Offline이라는 테이블이 있으며, 여기에는orderid,product,quantityordered,unitprice,orderdate,purchaseaddress메타데이터가 포함됩니다.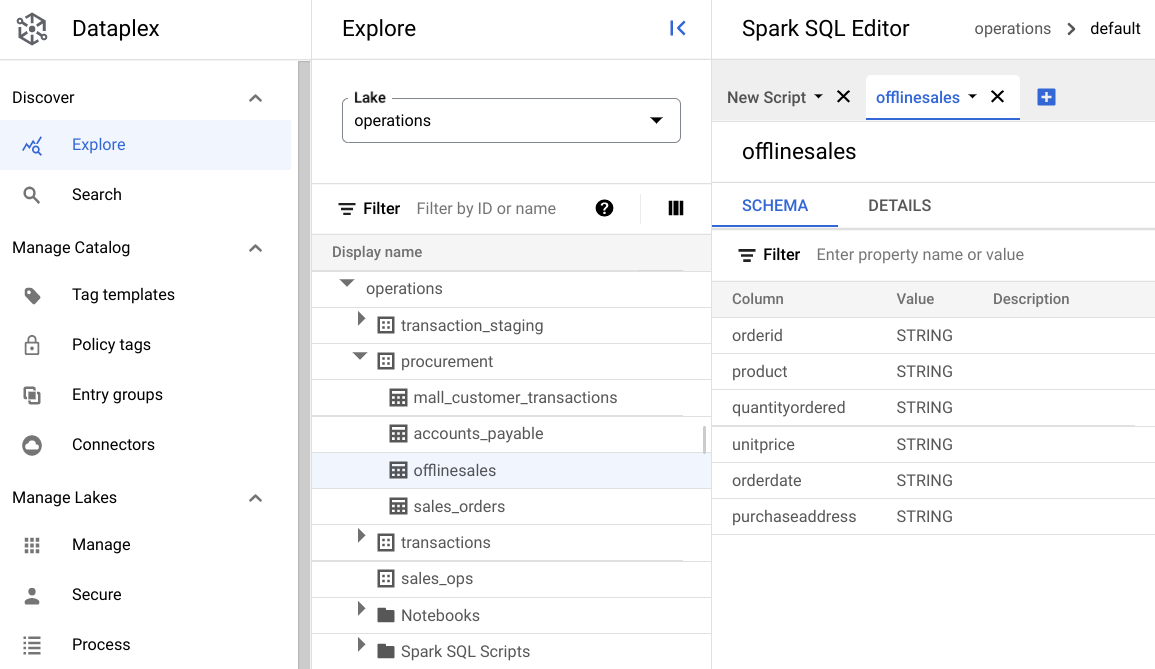
Spark SQL 편집기에서 추가를 클릭합니다. Spark SQL 스크립트가 표시됩니다.
선택사항: 분할 탭 보기에서 스크립트를 열어 메타데이터와 새 스크립트를 나란히 확인합니다. 새 스크립트 탭에서 더보기를 클릭하고 탭을 오른쪽으로 분할 또는 탭을 왼쪽으로 분할을 선택합니다.
데이터 탐색
환경에서는 Spark SQL 쿼리 및 노트북이 레이크 내에서 실행될 수 있도록 서버리스 컴퓨팅 리소스를 제공합니다. Spark SQL 쿼리를 작성하기 전에 쿼리를 실행할 환경을 만드세요.
다음 SparkSQL 쿼리를 사용하여 데이터를 살펴봅니다. SparkSQL 편집기에서 새 스크립트 창에 쿼리를 입력합니다.
테이블의 10개 행 샘플
다음 쿼리를 입력합니다.
select * from procurement.offlinesales where orderid != 'orderid' limit 10;실행을 클릭합니다.
데이터 세트의 총 거래 수 가져오기
다음 쿼리를 입력합니다.
select count(*) from procurement.offlinesales where orderid!='orderid';실행을 클릭합니다.
데이터 세트에서 다양한 제품 유형 수 찾기
다음 쿼리를 입력합니다.
select count(distinct product) from procurement.offlinesales where orderid!='orderid';실행을 클릭합니다.
거래 금액이 큰 제품 찾기
매출을 제품 유형 및 평균 판매 가격으로 분류하여 거래 금액이 큰 제품을 파악합니다.
다음 쿼리를 입력합니다.
select product,avg(quantityordered * unitprice) as avg_sales_amount from procurement.offlinesales where orderid!='orderid' group by product order by avg_sales_amount desc;실행을 클릭합니다.
다음 이미지는 avg_sales_amount라는 열에 표시된 대형 트랜잭션 값이 있는 판매 항목을 식별하기 위해 product라는 열을 사용하는 Results 창을 보여줍니다.
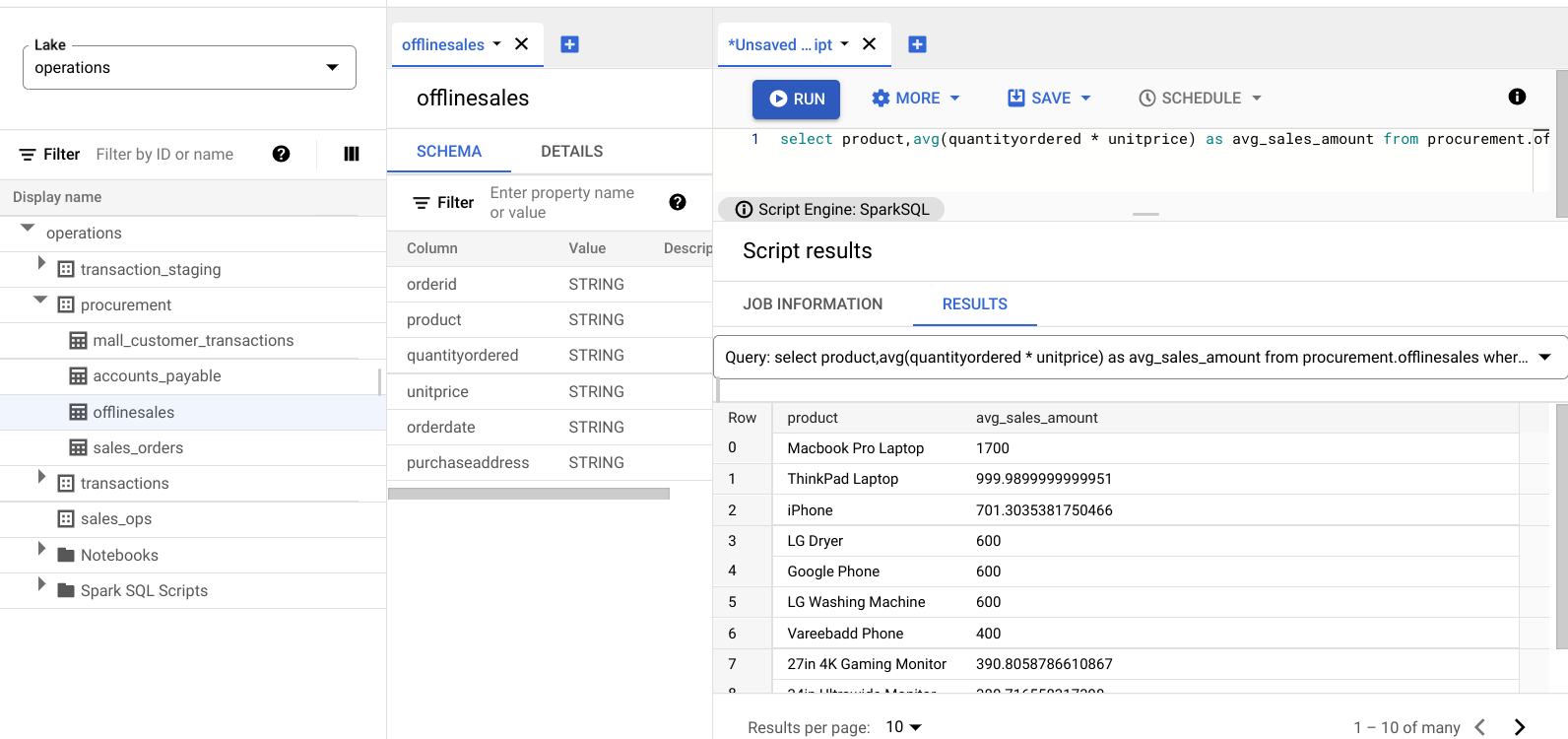
변동 계수를 사용한 이상치 감지
마지막 쿼리에서는 노트북의 평균 트랜잭션 금액이 높다는 것을 확인했습니다. 다음 쿼리는 데이터 세트에서 비정상이 아닌 노트북 트랜잭션을 감지하는 방법을 보여줍니다.
다음 쿼리는 '변동 계수' 측정항목 rsd_value를 사용하여 비정상적인 거래(평균 값과 비교하여 값 분포가 낮은 경우)를 찾습니다. 변동 계수가 낮을수록 이상치가 적다는 의미입니다.
다음 쿼리를 입력합니다.
WITH stats AS ( SELECT product, AVG(quantityordered * unitprice) AS avg_value, STDDEV(quantityordered * unitprice) / AVG(quantityordered * unitprice) AS rsd_value FROM procurement.offlinesales GROUP BY product) SELECT orderid, orderdate, product, (quantityordered * unitprice) as sales_amount, ABS(1 - (quantityordered * unitprice)/ avg_value) AS distance_from_avg FROM procurement.offlinesales INNER JOIN stats USING (product) WHERE rsd_value <= 0.2 ORDER BY distance_from_avg DESC LIMIT 10실행을 클릭합니다.
스크립트 결과를 참조하세요.
다음 이미지에서 결과 창은 product라는 열을 사용하여 변동 계수가 0.2 이내인 트랜잭션 값이 있는 판매 항목을 식별합니다.
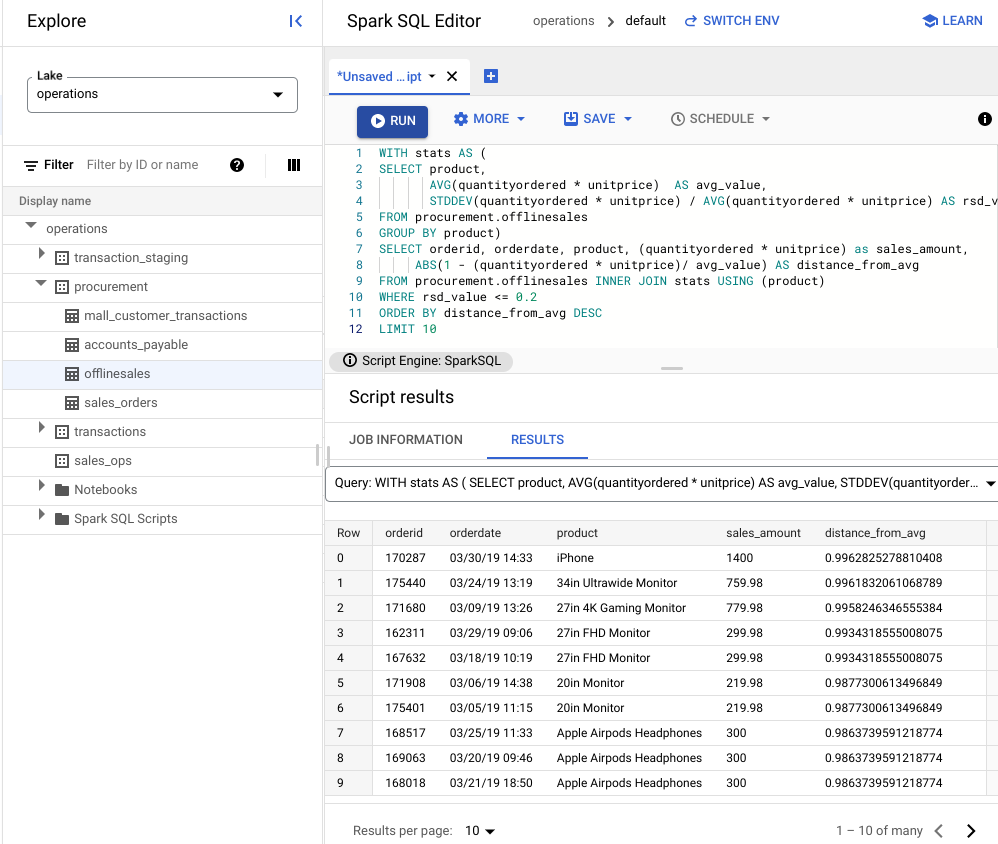
JupyterLab 노트북을 사용하여 이상치 시각화
ML 모델을 빌드하여 대규모로 이상치를 감지하고 시각화합니다.
별도의 탭에서 노트북을 열고 노트북이 로드될 때까지 기다립니다. Spark SQL 쿼리를 실행한 세션은 계속됩니다.
필요한 패키지를 가져오고 트랜잭션 데이터가 포함된 BigQuery 외부 테이블에 연결합니다. 다음 코드를 실행합니다.
from google.cloud import bigquery from google.api_core.client_options import ClientOptions import os import warnings warnings.filterwarnings('ignore') import pandas as pd project = os.environ['GOOGLE_CLOUD_PROJECT'] options = ClientOptions(quota_project_id=project) client = bigquery.Client(client_options=options) client = bigquery.Client() #Load data into DataFrame sql = '''select * from procurement.offlinesales limit 100;''' df = client.query(sql).to_dataframe()아이솔레이션 포레스트 알고리즘을 실행하여 데이터 세트에서 이상치를 찾습니다.
to_model_columns = df.columns[2:4] from sklearn.ensemble import IsolationForest clf=IsolationForest(n_estimators=100, max_samples='auto', contamination=float(.12), \ max_features=1.0, bootstrap=False, n_jobs=-1, random_state=42, verbose=0) clf.fit(df[to_model_columns]) pred = clf.predict(df[to_model_columns]) df['anomaly']=pred outliers=df.loc[df['anomaly']==-1] outlier_index=list(outliers.index) #print(outlier_index) #Find the number of anomalies and normal points here points classified -1 are anomalous print(df['anomaly'].value_counts())매트플롯립 시각화를 사용하여 예측된 이상치를 표시합니다.
import numpy as np from sklearn.decomposition import PCA pca = PCA(2) pca.fit(df[to_model_columns]) res=pd.DataFrame(pca.transform(df[to_model_columns])) Z = np.array(res) plt.title("IsolationForest") plt.contourf( Z, cmap=plt.cm.Blues_r) b1 = plt.scatter(res[0], res[1], c='green', s=20,label="normal points") b1 =plt.scatter(res.iloc[outlier_index,0],res.iloc[outlier_index,1], c='green',s=20, edgecolor="red",label="predicted outliers") plt.legend(loc="upper right") plt.show()
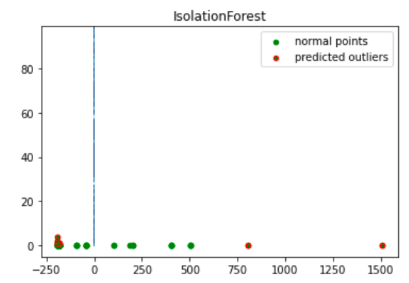
이 이미지는 이상치가 빨간색으로 강조 표시된 트랜잭션 데이터를 보여줍니다.
노트북 예약
Explore를 사용하면 주기적으로 실행되도록 노트북을 예약할 수 있습니다. 단계를 따라 만든 Jupyter 노트북을 예약합니다.
Dataplex 범용 카탈로그는 주기적으로 노트북을 실행하는 예약 태스크를 만듭니다. 태스크 진행 상태를 모니터링하려면 일정 보기를 클릭합니다.
노트북 공유 또는 내보내기
Explore를 사용하면 IAM 권한을 사용하여 조직의 다른 사용자와 노트북을 공유할 수 있습니다.
역할을 검토합니다. 이 노트북의 사용자에게 Dataplex 범용 카탈로그 뷰어(roles/dataplex.viewer), Dataplex 범용 카탈로그 편집자(roles/dataplex.editor), Dataplex 범용 카탈로그 관리자(roles/dataplex.admin) 역할을 부여하거나 취소합니다. 노트북을 공유한 후에는 레이크 수준에서 뷰어 또는 편집자 역할을 가진 사용자가 레이크로 이동하여 공유 노트북으로 작업할 수 있습니다.
삭제
이 튜토리얼에서 사용된 리소스 비용이 Google Cloud 계정에 청구되지 않도록 하려면 리소스가 포함된 프로젝트를 삭제하거나 프로젝트를 유지하고 개별 리소스를 삭제하세요.
프로젝트 삭제
Delete a Google Cloud project:
gcloud projects delete PROJECT_ID
개별 리소스 삭제
-
버킷을 삭제합니다.
gcloud storage buckets delete BUCKET_NAME
-
인스턴스를 삭제합니다.
gcloud compute instances delete INSTANCE_NAME
다음 단계
- Dataplex 범용 카탈로그 Explore 자세히 알아보기
- 스크립트 및 노트북 예약