Neste tutorial, você verá como usar o Dataflow SQL para unir um fluxo de dados do Pub/Sub com dados de uma tabela do BigQuery.
Objetivos
Neste tutorial, você aprenderá a:
- gravar uma consulta SQL do Dataflow que mescle dados de streaming do Pub/Sub com dados da tabela do BigQuery;
- implantar um job do Dataflow com base na IU do Dataflow SQL.
Custos
Neste documento, você usará os seguintes componentes faturáveis do Google Cloud:
- Dataflow
- Cloud Storage
- Pub/Sub
- Data Catalog
Para gerar uma estimativa de custo baseada na projeção de uso deste tutorial, use a calculadora de preços.
Antes de começar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Cloud Dataflow, Compute Engine, Logging, Cloud Storage, Cloud Storage JSON, BigQuery, Cloud Pub/Sub, Cloud Resource Manager and Data Catalog. APIs.
-
Create a service account:
-
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the Project > Owner role to the service account.
To grant the role, find the Select a role list, then select Project > Owner.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
-
Set the environment variable
GOOGLE_APPLICATION_CREDENTIALSto the path of the JSON file that contains your credentials. This variable applies only to your current shell session, so if you open a new session, set the variable again. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Cloud Dataflow, Compute Engine, Logging, Cloud Storage, Cloud Storage JSON, BigQuery, Cloud Pub/Sub, Cloud Resource Manager and Data Catalog. APIs.
-
Create a service account:
-
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the Project > Owner role to the service account.
To grant the role, find the Select a role list, then select Project > Owner.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
-
Set the environment variable
GOOGLE_APPLICATION_CREDENTIALSto the path of the JSON file that contains your credentials. This variable applies only to your current shell session, so if you open a new session, set the variable again. - Instale e inicialize a CLI gcloud. Escolha uma das opções de instalação.
Talvez seja necessário definir a propriedade
projectcomo o projeto que você está usando neste tutorial. - Acesse a IU da Web do SQL do Dataflow no console do Google Cloud. Isso
abre seu projeto acessado mais recentemente. Se quiser alternar para um projeto
diferente, clique no nome do projeto na parte superior da
IU da Web do BigQuery e pesquise aquele que você quer usar.
Acessar a IU da Web do Dataflow SQL
Criar exemplos de fonte
Se você quiser seguir o exemplo fornecido neste tutorial, crie as fontes a seguir e use-as nas etapas abaixo.
- Um tópico do Pub/Sub chamado
transactions: um stream de dados de transação que chega por meio de uma assinatura no tópico do Pub/Sub. Os dados para cada transação incluem informações como produto comprado, preço promocional e a cidade em que ocorreu a compra. Depois de criar o tópico do Pub/Sub, crie um script que publique mensagens no seu tópico. Esse script será executado em uma seção futura deste tutorial. - Uma tabela do BigQuery chamada
us_state_salesregions: uma tabela que fornece um mapeamento de estados para regiões de vendas. Antes de criar esta tabela, é preciso criar um conjunto de dados do BigQuery.
Criar um conjunto de dados e uma tabela do BigQuery
- Na IU da Web do BigQuery,
crie um conjunto de dados do BigQuery. Um conjunto de dados do BigQuery
é um contêiner de nível superior usado para conter suas tabelas. As tabelas do BigQuery precisam pertencer a um conjunto de dados.
- No painel Explorer, abra as ações para seu projeto. No menu, clique em Criar conjunto de dados. Na
captura de tela a seguir, o ID do projeto é
dataflow-sql.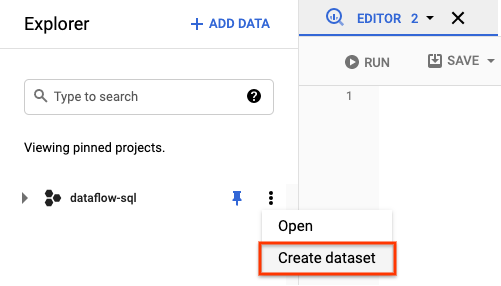
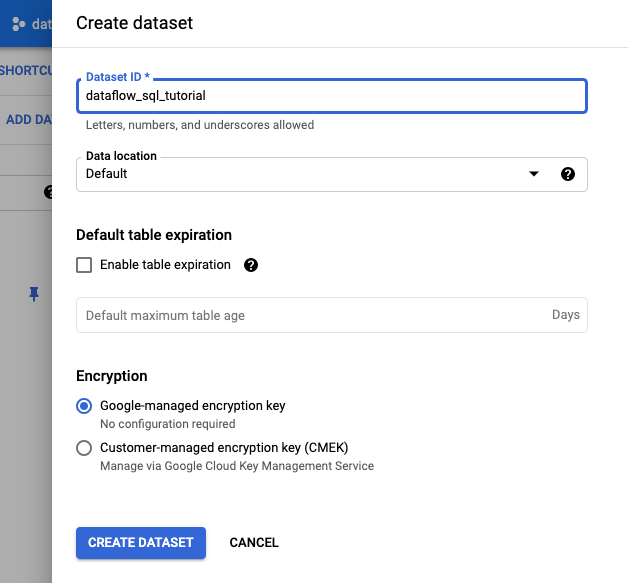
- No painel Criar conjunto de dados que é aberto, em
ID do conjunto de dados, insira
dataflow_sql_tutorial. - Em Local dos dados, selecione uma opção no menu.
- Clique em Criar conjunto de dados.
- No painel Explorer, abra as ações para seu projeto. No menu, clique em Criar conjunto de dados. Na
captura de tela a seguir, o ID do projeto é
- Crie uma tabela do BigQuery.
- Crie um arquivo de texto e nomeie-o como
us_state_salesregions.csv. - Copie e cole os dados a seguir em
us_state_salesregions.csv. Nas próximas etapas, você carregará esses dados na sua tabela do BigQuery.state_id,state_code,state_name,sales_region 1,MO,Missouri,Region_1 2,SC,South Carolina,Region_1 3,IN,Indiana,Region_1 6,DE,Delaware,Region_2 15,VT,Vermont,Region_2 16,DC,District of Columbia,Region_2 19,CT,Connecticut,Region_2 20,ME,Maine,Region_2 35,PA,Pennsylvania,Region_2 38,NJ,New Jersey,Region_2 47,MA,Massachusetts,Region_2 54,RI,Rhode Island,Region_2 55,NY,New York,Region_2 60,MD,Maryland,Region_2 66,NH,New Hampshire,Region_2 4,CA,California,Region_3 8,AK,Alaska,Region_3 37,WA,Washington,Region_3 61,OR,Oregon,Region_3 33,HI,Hawaii,Region_4 59,AS,American Samoa,Region_4 65,GU,Guam,Region_4 5,IA,Iowa,Region_5 32,NV,Nevada,Region_5 11,PR,Puerto Rico,Region_6 17,CO,Colorado,Region_6 18,MS,Mississippi,Region_6 41,AL,Alabama,Region_6 42,AR,Arkansas,Region_6 43,FL,Florida,Region_6 44,NM,New Mexico,Region_6 46,GA,Georgia,Region_6 48,KS,Kansas,Region_6 52,AZ,Arizona,Region_6 56,TN,Tennessee,Region_6 58,TX,Texas,Region_6 63,LA,Louisiana,Region_6 7,ID,Idaho,Region_7 12,IL,Illinois,Region_7 13,ND,North Dakota,Region_7 31,MN,Minnesota,Region_7 34,MT,Montana,Region_7 36,SD,South Dakota,Region_7 50,MI,Michigan,Region_7 51,UT,Utah,Region_7 64,WY,Wyoming,Region_7 9,NE,Nebraska,Region_8 10,VA,Virginia,Region_8 14,OK,Oklahoma,Region_8 39,NC,North Carolina,Region_8 40,WV,West Virginia,Region_8 45,KY,Kentucky,Region_8 53,WI,Wisconsin,Region_8 57,OH,Ohio,Region_8 49,VI,United States Virgin Islands,Region_9 62,MP,Commonwealth of the Northern Mariana Islands,Region_9
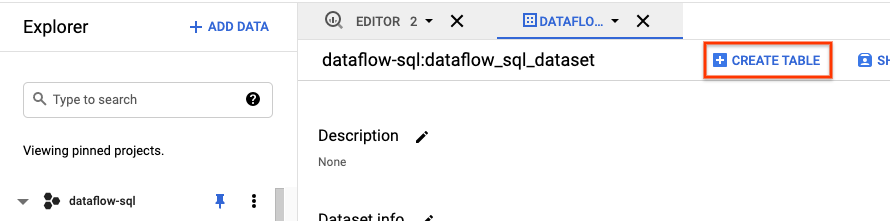
- No painel Explorer da IU do BigQuery, expanda o projeto para ver o conjunto de dados
dataflow_sql_tutorial. - Abra o menu de ações para o conjunto de dados
dataflow_sql_tutoriale clique em Abrir. - Selecione Criar tabela.
- No painel Criar tabela que será aberto:
- Em Criar tabela de, selecione Fazer upload.
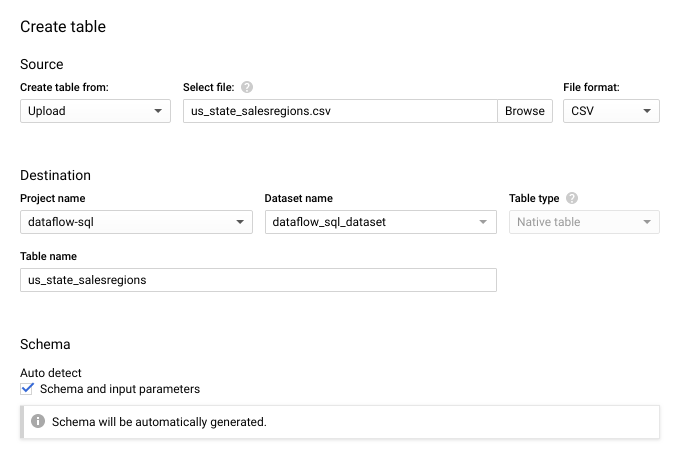
- Em Selecionar arquivo, clique em Procurar e escolha o arquivo
us_state_salesregions.csv. - Em Tabela, insira
us_state_salesregions. - Em Esquema, selecione Detectar automaticamente.
- Clique em Opções avançadas para expandir essa seção.
- Em Linhas de cabeçalho a serem ignoradas, digite
1e clique em Criar tabela.
- Em Criar tabela de, selecione Fazer upload.
- No painel Explorer, clique em
us_state_salesregions. Em Esquema, é possível ver o esquema que foi gerado automaticamente. Em Visualizar, é possível ver os dados da tabela.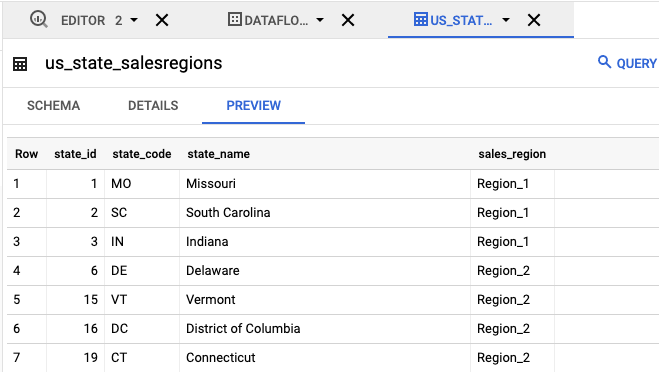
- Crie um arquivo de texto e nomeie-o como
Atribuir um esquema ao seu tópico do Pub/Sub
A atribuição de um esquema permite executar consultas SQL dos dados do seu tópico do Pub/Sub. Atualmente, o Dataflow SQL espera que as mensagens nos tópicos do Pub/Sub sejam serializadas no formato JSON.
Para atribuir um esquema ao
tópico de exemplo do Pub/Sub transactions:
Crie um arquivo de texto e nomeie-o como
transactions_schema.yaml. Copie e cole o texto de esquema a seguir emtransactions_schema.yaml.- column: event_timestamp description: Pub/Sub event timestamp mode: REQUIRED type: TIMESTAMP - column: tr_time_str description: Transaction time string mode: NULLABLE type: STRING - column: first_name description: First name mode: NULLABLE type: STRING - column: last_name description: Last name mode: NULLABLE type: STRING - column: city description: City mode: NULLABLE type: STRING - column: state description: State mode: NULLABLE type: STRING - column: product description: Product mode: NULLABLE type: STRING - column: amount description: Amount of transaction mode: NULLABLE type: FLOATAtribua o esquema usando a Google Cloud CLI.
a. Atualize a CLI gcloud com o comando a seguir. Garanta que a versão da CLI gcloud é 242.0.0 ou posterior.
gcloud components update
b. Execute o comando a seguir em uma janela de linha de comando. Substitua project-id pelo ID do projeto e path-to-file pelo caminho do arquivo
transactions_schema.yaml.gcloud data-catalog entries update \ --lookup-entry='pubsub.topic.`project-id`.transactions' \ --schema-from-file=path-to-file/transactions_schema.yaml
Para mais informações sobre parâmetros de comando e formatos de arquivo de esquema permitidos, consulte a página de documentação de atualização de entradas de catálogo de dados do gcloud.
c. Confirme se o esquema foi atribuído com êxito ao tópico
transactionsdo Pub/Sub. Substitua project-id pelo ID do projeto.gcloud data-catalog entries lookup 'pubsub.topic.`project-id`.transactions'
Encontrar fontes do Pub/Sub
A IU do SQL do Dataflow oferece uma forma de encontrar fontes de dados do Pub/Sub de qualquer projeto a que você tenha acesso, para que não precise lembrar os nomes completos deles.
No exemplo deste tutorial, navegue até o editor do Dataflow SQL e procure o tópico transactions do Pub/Sub que você criou:
Navegue até o SQL Workspace.
No painel Editor do SQL do Dataflow, na barra de pesquisa, procure por
projectid=project-id transactions. Substitua project-id pelo ID do projeto.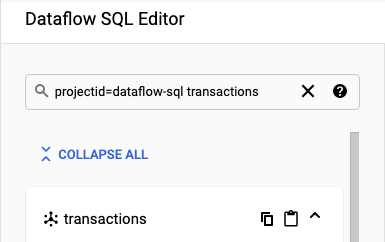
Ver o esquema
- No painel Editor do SQL do Dataflow, clique em transações ou pesquise um tópico do Pub/Sub digitando
projectid=project-id system=cloud_pubsub. selecione o tópico. Em Esquema, é possível visualizar o esquema atribuído ao tópico do Pub/Sub.
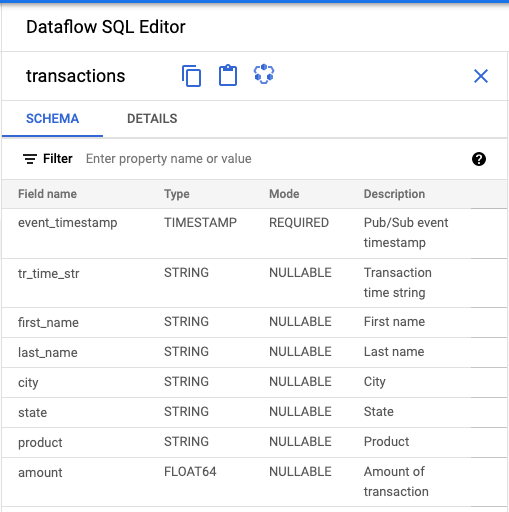
Criar uma consulta SQL
A IU do Dataflow SQL permite criar consultas SQL para executar jobs do Dataflow.
A consulta SQL a seguir é de enriquecimento de dados. Ele acrescenta mais um campo, sales_region, ao stream de eventos do Pub/Sub (transactions), usando uma tabela do BigQuery (us_state_salesregions) que mapeia estados nas regiões de vendas.
Copie e cole a consulta SQL abaixo no Editor de consultas. Substitua project-id pelo ID do projeto:
SELECT tr.*, sr.sales_region FROM pubsub.topic.`project-id`.transactions as tr INNER JOIN bigquery.table.`project-id`.dataflow_sql_tutorial.us_state_salesregions AS sr ON tr.state = sr.state_code
Ao inserir uma consulta na IU do Dataflow SQL, o validador da consulta verifica a sintaxe dela. Se a consulta for válida, será exibido um ícone de marca de seleção verde. Se a consulta for inválida, será exibido um ícone de ponto de exclamação vermelho. Se a sintaxe for inválida, clicar no ícone do validador fornecerá informações sobre o que é necessário corrigir.
A captura de tela a seguir mostra a consulta válida no Editor de consulta. O validador exibe uma marca de seleção verde.

Criar um job do Dataflow para executar sua consulta SQL
Para executar sua consulta SQL, crie um job do Dataflow na IU do Dataflow SQL.
Acima do Editor de consultas, clique em Criar job.
No painel Criar job do Dataflow que é aberto:
- Em Destino, selecione BigQuery.
- Em ID do conjunto de dados, selecione
dataflow_sql_tutorial. - Para Nome da tabela, digite
sales.
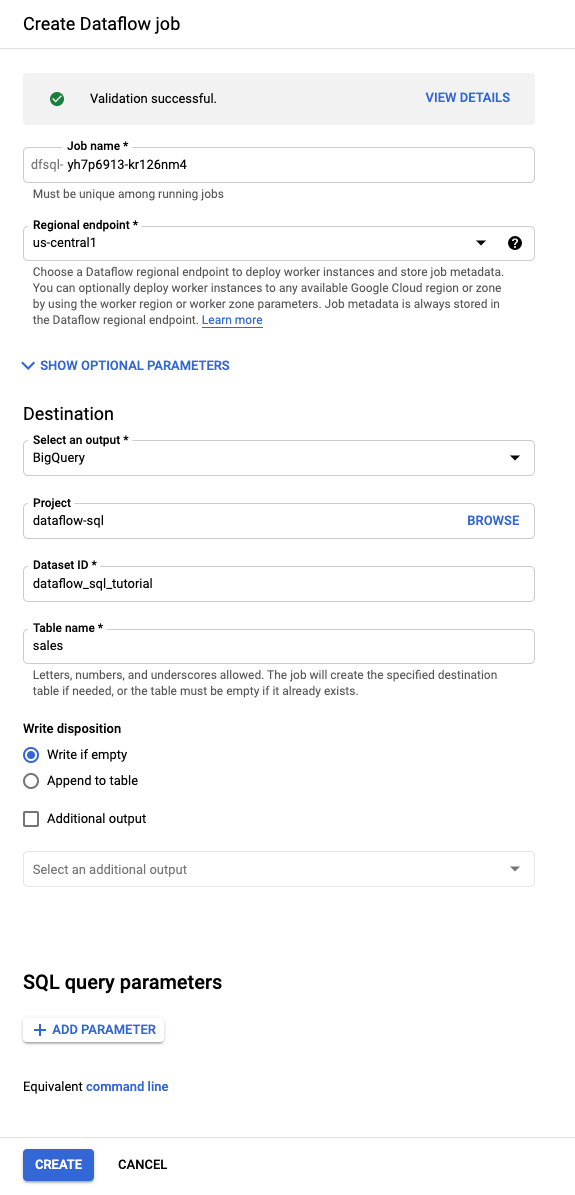
(Opcional) O Dataflow escolhe automaticamente as configurações ideais para seu job do Dataflow SQL, mas é possível expandir o menu dos Parâmetros opcionais para especificar manualmente as seguintes opções de pipeline:
- Número máximo de workers
- Zona
- E-mail da conta de serviço
- Tipo de máquina
- Outros experimentos
- Configuração do endereço IP do worker
- Rede
- Sub-rede
Clique em Criar. O job do Dataflow leva alguns minutos para começar a ser executado.
Ver o job do Dataflow
O Dataflow transforma sua consulta SQL em um pipeline do Apache Beam. Clique em Ver job para abrir a IU da Web do Dataflow, em que é possível ver uma representação gráfica do pipeline.
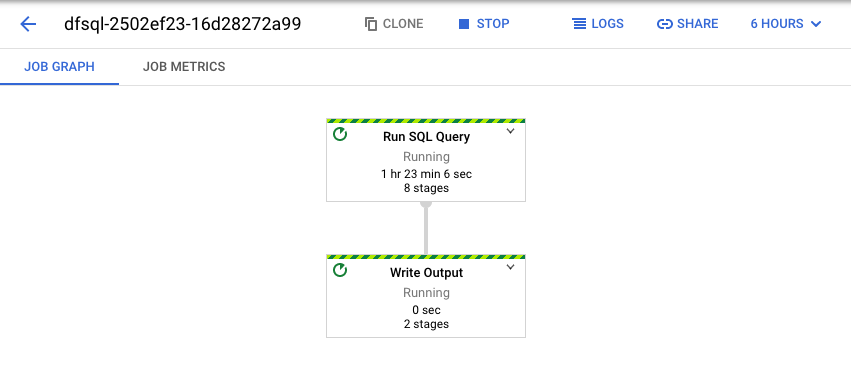
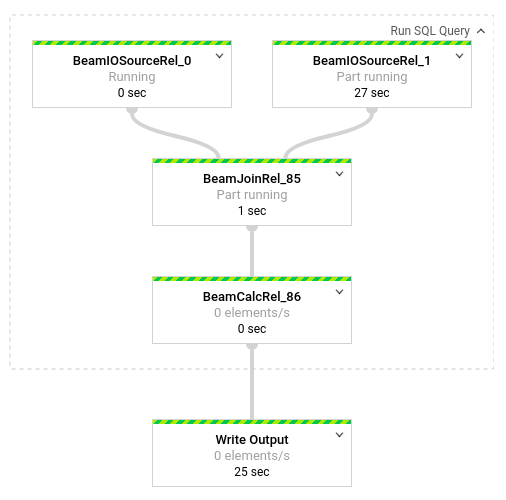
Para ver um detalhamento das transformações que ocorrem no pipeline, clique nas caixas. Por exemplo, se você clicar na caixa superior na representação gráfica, com o rótulo Executar consulta SQL, aparecerá um gráfico que mostra as operações em segundo plano.
As duas primeiras caixas representam as duas entradas que você mesclou: o tópico do Pub/Sub, transactions e a tabela do BigQuery, us_state_salesregions.
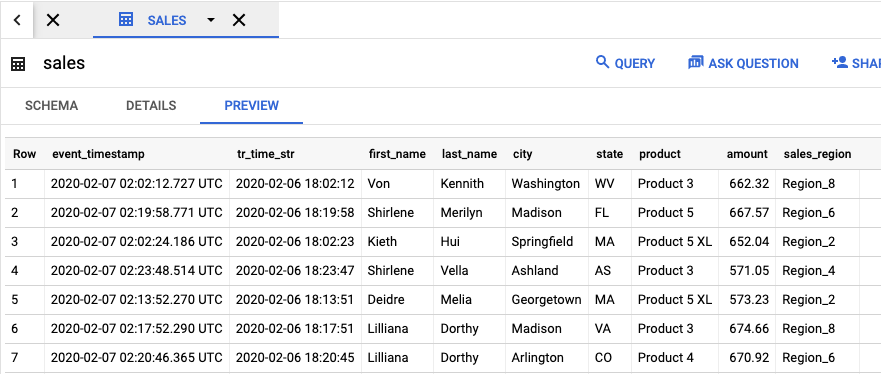
Para ver a tabela de saída que contém os resultados do job, acesse a IU do BigQuery.
No painel Explorer, no projeto, clique no conjunto de dados dataflow_sql_tutorial que você criou. Em seguida, clique na tabela de saída sales. A guia Visualização exibe o conteúdo da tabela de saída.
Ver jobs passados e editar suas consultas
A IU do Dataflow armazena jobs e consultas anteriores na página Jobs.
É possível usar a lista do histórico de jobs para ver consultas SQL anteriores. Por exemplo, você quer modificar sua consulta para agregar vendas por região de vendas a cada 15 segundos. Use a página Jobs para acessar o job em execução que você iniciou anteriormente no tutorial, copie a consulta SQL e execute outro job com uma consulta modificada.
Na página Jobs do Dataflow, clique no job que você quer editar.
Na página Detalhes do job, no painel Informações do job, localize Opções de pipeline na consulta SQL. Encontre a linha de queryString.
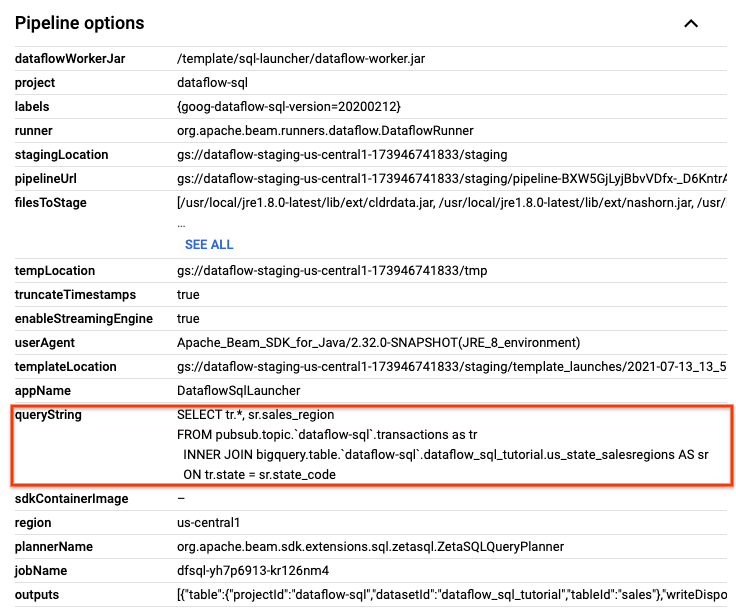
Copie e cole a seguinte consulta SQL no Editor de SQL do Dataflow no SQL Workspace para adicionar janelas em cascata Substitua project-id pelo ID do projeto.
SELECT sr.sales_region, TUMBLE_START("INTERVAL 15 SECOND") AS period_start, SUM(tr.amount) as amount FROM pubsub.topic.`project-id`.transactions AS tr INNER JOIN bigquery.table.`project-id`.dataflow_sql_tutorial.us_state_salesregions AS sr ON tr.state = sr.state_code GROUP BY sr.sales_region, TUMBLE(tr.event_timestamp, "INTERVAL 15 SECOND")
Clique em Criar job para criar um novo job com a consulta modificada.
Limpar
Para evitar cobranças gerados pelos recursos usados neste tutorial na conta de faturamento do Cloud:
Interrompa o script de publicação
transactions_injector.pyse ele ainda estiver em execução.Interrompa os jobs do Dataflow em execução. Acesse a IU da Web do Dataflow no console do Google Cloud.
Acessar a IU da Web do Dataflow
Em cada job criado seguindo este tutorial, siga estas etapas:
Clique no nome do job.
Na página de detalhes do job, clique em Parar. A caixa de diálogo Interromper job será exibida, oferecendo opções para essa ação.
Selecione Cancelar.
Clique em Interromper job. O serviço suspende toda a ingestão de dados e processamento assim que possível. Como Cancelar interrompe imediatamente o processamento, talvez todos os dados "em trânsito" sejam perdidos. Interromper um job pode levar alguns minutos.
Exclua seu conjunto de dados do BigQuery. Acesse a IU da Web do BigQuery no console do Google Cloud.
Acessar a IU da Web do BigQuery
No painel Explorador, na seção Recursos, clique no conjunto de dados dataflow_sql_tutorial criado.
No painel de detalhes, clique em Excluir. Uma caixa de diálogo de confirmação será exibida.
Na caixa de diálogo Excluir conjunto de dados, confirme o comando de exclusão digitando
deletee clique em Excluir.
Exclua seu tópico do Pub/Sub. Acesse a página tópicos do Pub/Sub no console do Google Cloud.
Acesse a página de tópicos do Cloud Pub/Sub
Selecione o tópico
transactions.Clique em Excluir para excluir permanentemente o tópico. Uma caixa de diálogo de confirmação será exibida.
Na caixa de diálogo Excluir tópico, confirme o comando de exclusão digitando
deletee clique em Excluir.Acesse a página de assinaturas do Pub/Sub.
Selecione as assinaturas restantes até
transactions. Se seus jobs não estiverem mais em execução, pode não existir nenhuma assinatura.Clique em Excluir para excluir permanentemente as assinaturas. Na caixa de diálogo de confirmação, clique em Excluir.
Exclua o intervalo de preparo do Dataflow no Cloud Storage. Acesse a página Buckets do Cloud Storage no console do Google Cloud.
Selecione o bucket de preparo do Dataflow.
Clique em Excluir para excluir permanentemente o bucket. Uma caixa de diálogo de confirmação será exibida.
Na caixa de diálogo Excluir bucket, confirme o comando de exclusão digitando
DELETEe clique em Excluir.
A seguir
- Veja uma introdução ao SQL do Dataflow.
- Conheça os conceitos básicos sobre pipeline de streaming.
- Explore a Referência do Dataflow SQL.
- Assista à demonstração de análise de streaming (em inglês) apresentada na Cloud Next 2019.