En este instructivo, se muestra cómo usar Dataflow SQL para unir una transmisión de datos de Pub/Sub con datos de una tabla de BigQuery.
Objetivos
En este instructivo, realizarás lo siguiente:
- Escribirás una consulta de SQL de Dataflow que una los datos de transmisión de Pub/Sub con los datos de la tabla de BigQuery.
- Implementarás un trabajo de Dataflow desde la IU de Dataflow SQL.
Costos
En este documento, usarás los siguientes componentes facturables de Google Cloud:
- Dataflow
- Cloud Storage
- Pub/Sub
- Data Catalog
Para generar una estimación de costos en función del uso previsto, usa la calculadora de precios.
Antes de comenzar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Cloud Dataflow, Compute Engine, Logging, Cloud Storage, Cloud Storage JSON, BigQuery, Cloud Pub/Sub, Cloud Resource Manager and Data Catalog. APIs.
-
Create a service account:
-
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the Project > Owner role to the service account.
To grant the role, find the Select a role list, then select Project > Owner.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
-
Set the environment variable
GOOGLE_APPLICATION_CREDENTIALSto the path of the JSON file that contains your credentials. This variable applies only to your current shell session, so if you open a new session, set the variable again. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Cloud Dataflow, Compute Engine, Logging, Cloud Storage, Cloud Storage JSON, BigQuery, Cloud Pub/Sub, Cloud Resource Manager and Data Catalog. APIs.
-
Create a service account:
-
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the Project > Owner role to the service account.
To grant the role, find the Select a role list, then select Project > Owner.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
-
Set the environment variable
GOOGLE_APPLICATION_CREDENTIALSto the path of the JSON file that contains your credentials. This variable applies only to your current shell session, so if you open a new session, set the variable again. - Instala e inicializa la CLI de gcloud Elige una de las opciones de instalación.
Es posible que debas establecer la propiedad
projecten el proyecto que usas para esta explicación. - Ve a la IU web de Dataflow SQL en la consola de Google Cloud. Esto abrirá el último proyecto al que accediste. Para cambiar a un proyecto diferente, haz clic en el nombre del proyecto en la parte superior de la IU web de Dataflow SQL y busca el proyecto que quieres usar.
Ir a la IU web de Dataflow SQL
Crea fuentes de ejemplo
Si quieres seguir el ejemplo proporcionado en este instructivo, crea las siguientes fuentes y úsalas en los pasos del instructivo.
- Un tema de Pub/Sub con el nombre
transactions: una transmisión de datos de transacción que llega mediante una suscripción al tema de Pub/Sub. Los datos de cada transacción incluyen información sobre el producto comprado, el precio de oferta, y la ciudad y el estado donde se realizó la compra. Después de crear el tema de Pub/Sub, debes crear una secuencia de comandos que publique mensajes en tu tema. Ejecutarás esta secuencia de comandos en una sección posterior de este instructivo. - Una tabla de BigQuery llamada
us_state_salesregions: una tabla que proporciona una asignación de estados a regiones de ventas. Antes de crear esta tabla, debes crear un conjunto de datos de BigQuery.
Crea un conjunto de datos y una tabla de BigQuery
- En la IU web de BigQuery, crea un conjunto de datos de BigQuery. Un conjunto de datos de BigQuery es un contenedor de nivel superior que se usa para guardar tus tablas. Las tablas de BigQuery deben pertenecer a un conjunto de datos.
- En el panel Explorador, abre las acciones de tu proyecto. En el menú, haz clic en Crear conjunto de datos. En la captura de pantalla siguiente, el ID del proyecto es
dataflow-sql.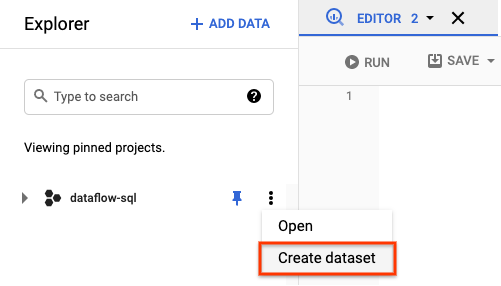
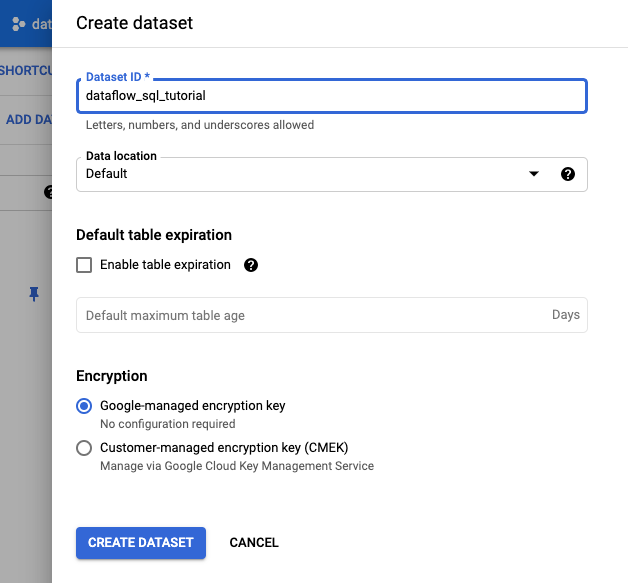
- En el panel Crear conjunto de datos que se abre, en ID del conjunto de datos, ingresa
dataflow_sql_tutorial. - En Ubicación de los datos, selecciona una opción del menú.
- Haga clic en Crear conjunto de datos.
- En el panel Explorador, abre las acciones de tu proyecto. En el menú, haz clic en Crear conjunto de datos. En la captura de pantalla siguiente, el ID del proyecto es
- Crea una tabla de BigQuery.
- Crea un archivo de texto y asígnale el nombre
us_state_salesregions.csv. - Copia y pega los datos siguientes en
us_state_salesregions.csv. En los próximos pasos, cargarás estos datos en la tabla de BigQuery.state_id,state_code,state_name,sales_region 1,MO,Missouri,Region_1 2,SC,South Carolina,Region_1 3,IN,Indiana,Region_1 6,DE,Delaware,Region_2 15,VT,Vermont,Region_2 16,DC,District of Columbia,Region_2 19,CT,Connecticut,Region_2 20,ME,Maine,Region_2 35,PA,Pennsylvania,Region_2 38,NJ,New Jersey,Region_2 47,MA,Massachusetts,Region_2 54,RI,Rhode Island,Region_2 55,NY,New York,Region_2 60,MD,Maryland,Region_2 66,NH,New Hampshire,Region_2 4,CA,California,Region_3 8,AK,Alaska,Region_3 37,WA,Washington,Region_3 61,OR,Oregon,Region_3 33,HI,Hawaii,Region_4 59,AS,American Samoa,Region_4 65,GU,Guam,Region_4 5,IA,Iowa,Region_5 32,NV,Nevada,Region_5 11,PR,Puerto Rico,Region_6 17,CO,Colorado,Region_6 18,MS,Mississippi,Region_6 41,AL,Alabama,Region_6 42,AR,Arkansas,Region_6 43,FL,Florida,Region_6 44,NM,New Mexico,Region_6 46,GA,Georgia,Region_6 48,KS,Kansas,Region_6 52,AZ,Arizona,Region_6 56,TN,Tennessee,Region_6 58,TX,Texas,Region_6 63,LA,Louisiana,Region_6 7,ID,Idaho,Region_7 12,IL,Illinois,Region_7 13,ND,North Dakota,Region_7 31,MN,Minnesota,Region_7 34,MT,Montana,Region_7 36,SD,South Dakota,Region_7 50,MI,Michigan,Region_7 51,UT,Utah,Region_7 64,WY,Wyoming,Region_7 9,NE,Nebraska,Region_8 10,VA,Virginia,Region_8 14,OK,Oklahoma,Region_8 39,NC,North Carolina,Region_8 40,WV,West Virginia,Region_8 45,KY,Kentucky,Region_8 53,WI,Wisconsin,Region_8 57,OH,Ohio,Region_8 49,VI,United States Virgin Islands,Region_9 62,MP,Commonwealth of the Northern Mariana Islands,Region_9
- En el panel Explorador de la IU de BigQuery, expande tu proyecto para ver el conjunto de datos
dataflow_sql_tutorial. - Abre el menú de acciones para el conjunto de datos
dataflow_sql_tutorialy haz clic en Abrir. - Haz clic en Crear tabla.
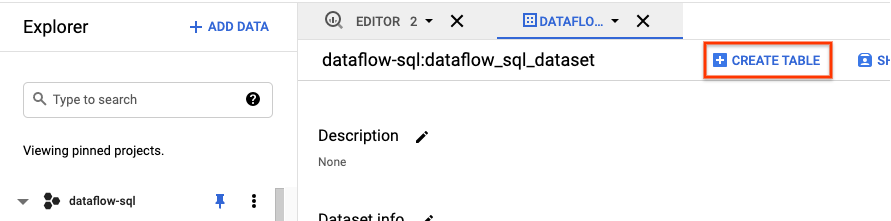
- En el panel Crear tabla que se abre, haz lo siguiente:
- Para Crear tabla desde (Create table from), selecciona Subir (Upload).
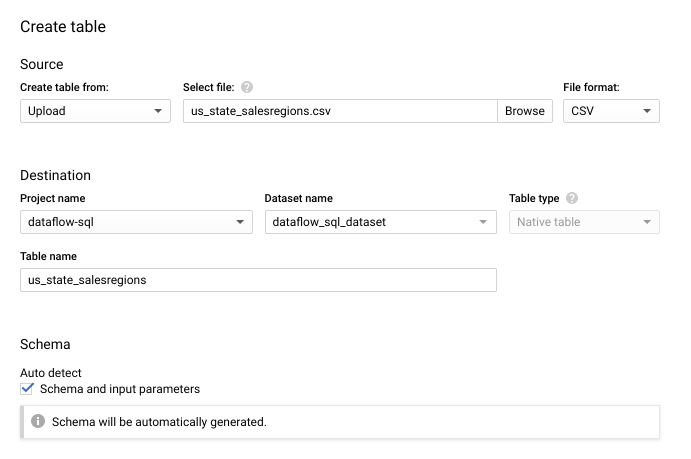
- En Seleccionar archivo, haz clic en Explorar y selecciona tu archivo
us_state_salesregions.csv. - En Tabla, ingresa
us_state_salesregions. - En Esquema, selecciona Detección automática.
- Haz clic en Opciones avanzadas para expandir la sección Opciones avanzadas.
- En Filas de encabezado que se omitirán, ingresa
1y, luego, haz clic en Crear tabla.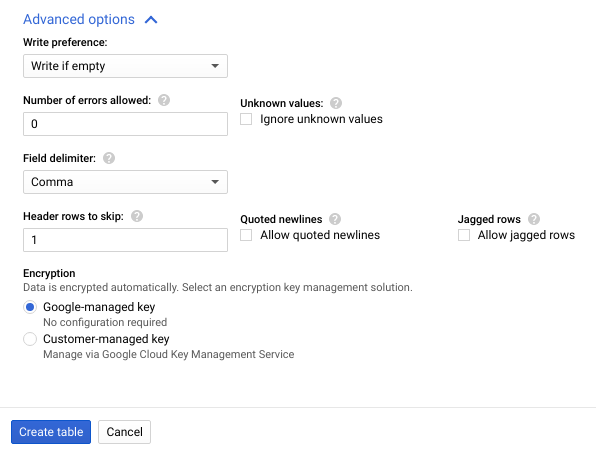
- Para Crear tabla desde (Create table from), selecciona Subir (Upload).
- En el panel Explorador, haz clic en
us_state_salesregions. En Esquema, puedes ver el esquema que se generó de manera automática. En Vista previa, puedes ver los datos de la tabla.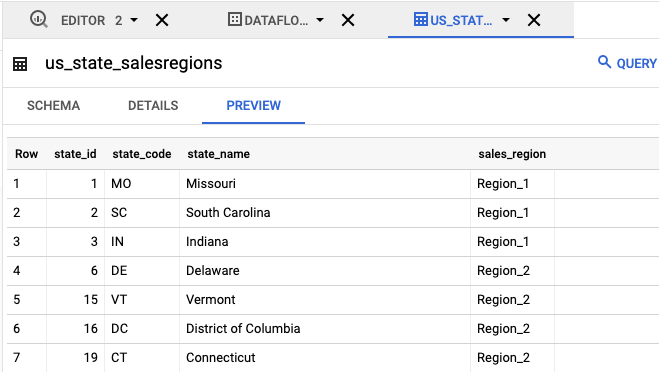
- Crea un archivo de texto y asígnale el nombre
Asigna un esquema a tu tema de Pub/Sub
Asignar un esquema te permite ejecutar consultas de SQL en los datos del tema de Pub/Sub. Actualmente, Dataflow SQL espera que los mensajes en los temas de Pub/Sub se serialicen en formato JSON.
Para asignar un esquema al ejemplo de tema de Cloud Pub/Sub transactions:
Crea un archivo de texto y asígnale el nombre
transactions_schema.yaml. Copia y pega el texto de esquema siguiente entransactions_schema.yaml.- column: event_timestamp description: Pub/Sub event timestamp mode: REQUIRED type: TIMESTAMP - column: tr_time_str description: Transaction time string mode: NULLABLE type: STRING - column: first_name description: First name mode: NULLABLE type: STRING - column: last_name description: Last name mode: NULLABLE type: STRING - column: city description: City mode: NULLABLE type: STRING - column: state description: State mode: NULLABLE type: STRING - column: product description: Product mode: NULLABLE type: STRING - column: amount description: Amount of transaction mode: NULLABLE type: FLOATAsigna el esquema con Google Cloud CLI.
a. Actualiza la CLI de gcloud con el siguiente comando Asegúrate de que la versión de la CLI de gcloud sea 242.0.0 o superior.
gcloud components update
b. Ejecuta el comando siguiente en una ventana de línea de comandos. Reemplaza project-id por el ID del proyecto y path-to-file por la ruta de acceso a tu archivo
transactions_schema.yaml.gcloud data-catalog entries update \ --lookup-entry='pubsub.topic.`project-id`.transactions' \ --schema-from-file=path-to-file/transactions_schema.yaml
Para obtener más información sobre los parámetros del comando y los formatos de archivo de esquema permitidos, consulta la página de documentación de actualización de entradas de Data Catalog en Gcloud.
c. Confirma que tu esquema se asignó de forma correcta al tema de Pub/Sub
transactions(opcional). Reemplaza project-id con el ID del proyecto.gcloud data-catalog entries lookup 'pubsub.topic.`project-id`.transactions'
Busca fuentes de Pub/Sub
La IU de Dataflow SQL proporciona una forma de encontrar objetos de fuente de datos de Pub/Sub para cualquier proyecto al que tengas acceso, por lo que no es necesario que recuerdes sus nombres completos.
Para el ejemplo de este instructivo, navega hacia el editor de Dataflow SQL y busca el tema transactions de Pub/Sub que creaste:
Navega hasta el lugar de trabajo de SQL.
En el panel Editor de Dataflow SQL, en la barra de búsqueda, busca
projectid=project-id transactions. Reemplaza project-id con el ID de tu proyecto.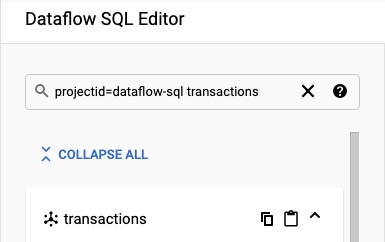
Observa el esquema
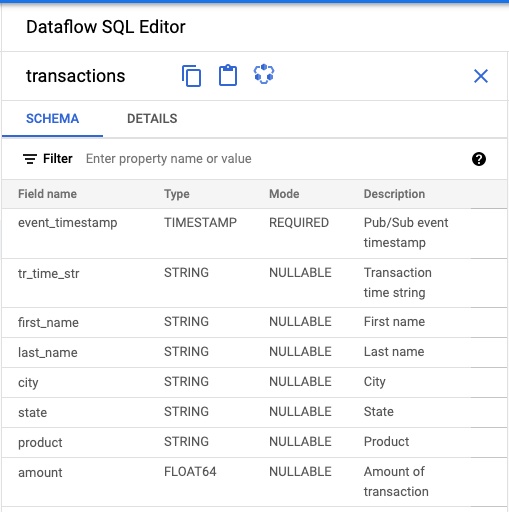
- En el panel Editor de Dataflow SQL de la IU de Dataflow SQL, haz clic en transacciones o escribe
projectid=project-id system=cloud_pubsubpara buscar un tema de Pub/Sub, y selecciona el tema. En Esquema, podrás ver el esquema que asignaste al tema de Pub/Sub.
Crea una consulta de SQL
La IU de Dataflow SQL te permite crear consultas de SQL para ejecutar tus trabajos de Dataflow.
La consulta de SQL siguiente es una consulta de enriquecimiento de datos. Agrega un campo adicional, sales_region, a la transmisión de eventos de Pub/Sub (transactions), mediante una tabla de BigQuery (us_state_salesregions) que asigne estados a las regiones de ventas.
Copia y pega la consulta de SQL siguiente en el Editor de consultas. Reemplaza project-id por el ID del proyecto.
SELECT tr.*, sr.sales_region FROM pubsub.topic.`project-id`.transactions as tr INNER JOIN bigquery.table.`project-id`.dataflow_sql_tutorial.us_state_salesregions AS sr ON tr.state = sr.state_code
Cuando ingresas una consulta en la IU de Dataflow SQL, la consulta validador verifica la sintaxis de consulta. Si la consulta es válida, se muestra un ícono de marca de verificación verde. Si la consulta no es válida, se muestra un ícono de signo de exclamación rojo. Si la sintaxis de la consulta no es válida, se proporcionará información sobre lo que se debe corregir si haces clic en el ícono del validador.
En la captura de pantalla siguiente, se muestra la consulta válida en el Editor de consultas. El validador muestra una marca de verificación verde.

Crea un trabajo de Dataflow para ejecutar la consulta de SQL
Para ejecutar tu consulta de SQL, crea un trabajo de Dataflow desde la IU de Dataflow SQL.
En el Editor de consultas, haz clic en Crear trabajo.
En el panel Crear trabajo de Dataflow que se abre, haz lo siguiente:
- En Destino, selecciona BigQuery.
- En ID del conjunto de datos, selecciona
dataflow_sql_tutorial. - En Nombre de la tabla, ingresa
sales.
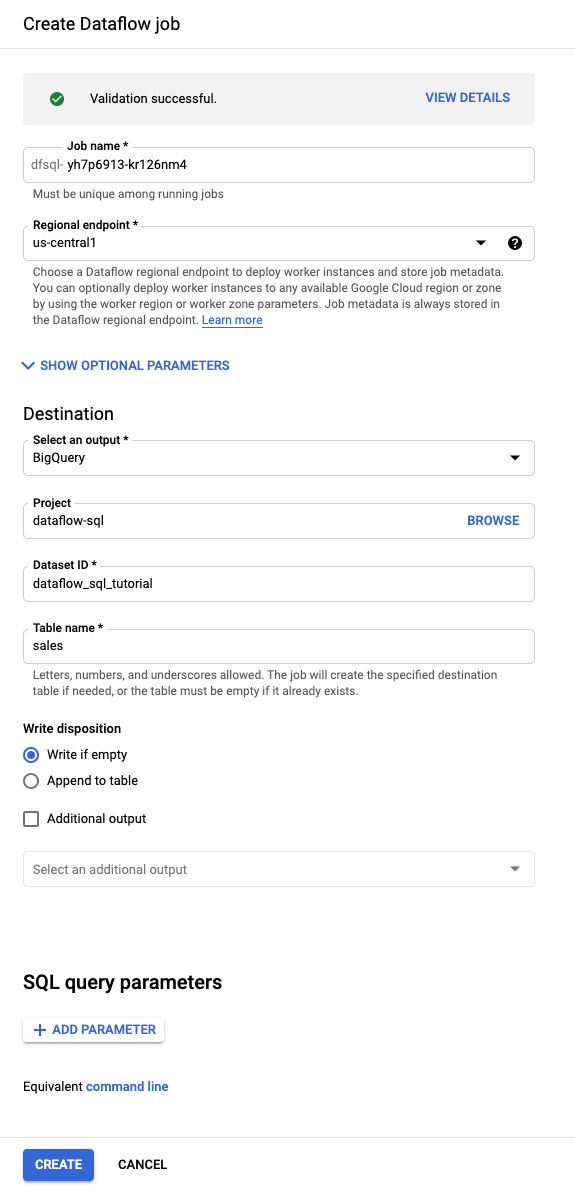
Opcional: Dataflow elige automáticamente la configuración óptima para tu trabajo de Dataflow SQL, pero puedes expandir el menú Parámetros opcionales para especificar manualmente las siguientes opciones de canalización:
- Cantidad máxima de trabajadores
- Zona
- Correo electrónico de la cuenta de servicio
- Tipo de máquina
- Experimentos adicionales
- Configuración de la dirección IP del trabajador
- Red
- Subred
Haz clic en Crear. Tu trabajo de Dataflow tarda unos minutos en comenzar a ejecutarse.
Visualiza el trabajo de Dataflow
Dataflow convierte tu consulta de SQL en una canalización de Apache Beam. Haz clic en Ver trabajo para abrir la IU web de Dataflow, en la que podrás ver una representación gráfica de tu canalización.
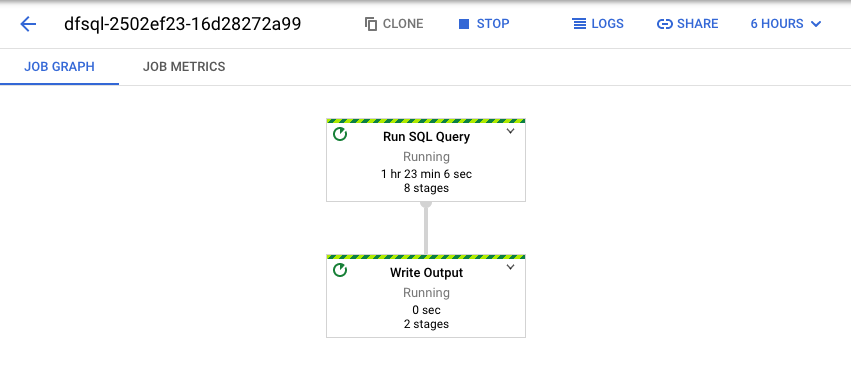
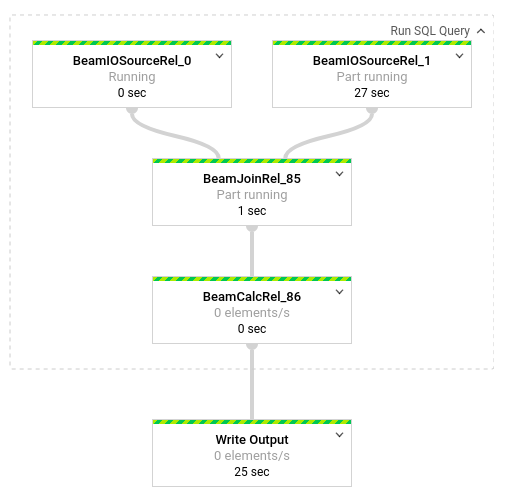
Para ver un desglose de las transformaciones que se generan en la canalización, haz clic en las casillas. Por ejemplo, si haces clic en el primer cuadro de la representación gráfica que tiene la etiqueta Ejecutar consulta en SQL, aparecerá un gráfico con las operaciones que se realizan en segundo plano.
Los dos primeros cuadros representan las dos entradas que uniste: el tema de Pub/Sub, transactions, y la tabla de BigQuery, us_state_salesregions.
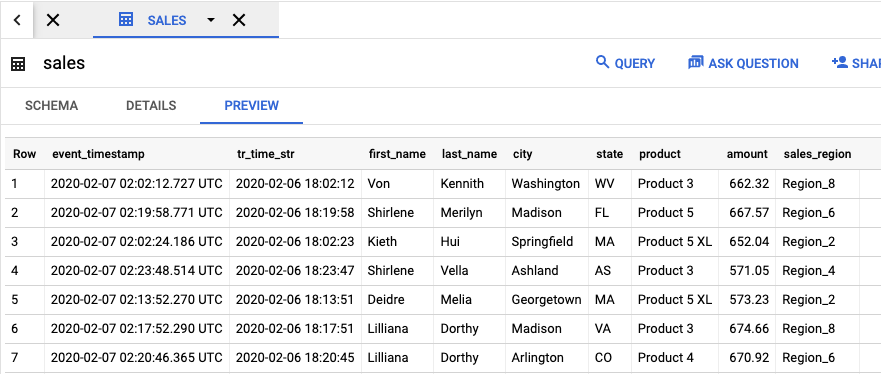
Para ver la tabla de resultados con los resultados del trabajo, ve a la IU de BigQuery.
En el panel Explorador, en tu proyecto, haz clic en el conjunto de datos dataflow_sql_tutorial que creaste. Luego, haz clic en la tabla de resultados, sales. En la pestaña Vista previa, se muestran los contenidos de la tabla de resultados.
Visualiza los trabajos anteriores y edita tus consultas
La IU de Dataflow almacena trabajos y consultas anteriores en la página Trabajos.
Puedes usar la lista del historial de trabajos para ver las consultas de SQL anteriores. Por ejemplo, en caso de que quieras modificar tu consulta para agregar ventas por región de ventas cada 15 segundos. Usa la página Trabajos para acceder al trabajo en ejecución que iniciaste antes en el instructivo, copia la consulta de SQL y ejecuta otro trabajo con una consulta modificada.
En la página Trabajos de Dataflow, haz clic en el trabajo que deseas editar.
En la página Detalles del trabajo, en el panel Información del trabajo, en Opciones de canalización, busca la consulta en SQL. Busca la fila para queryString.
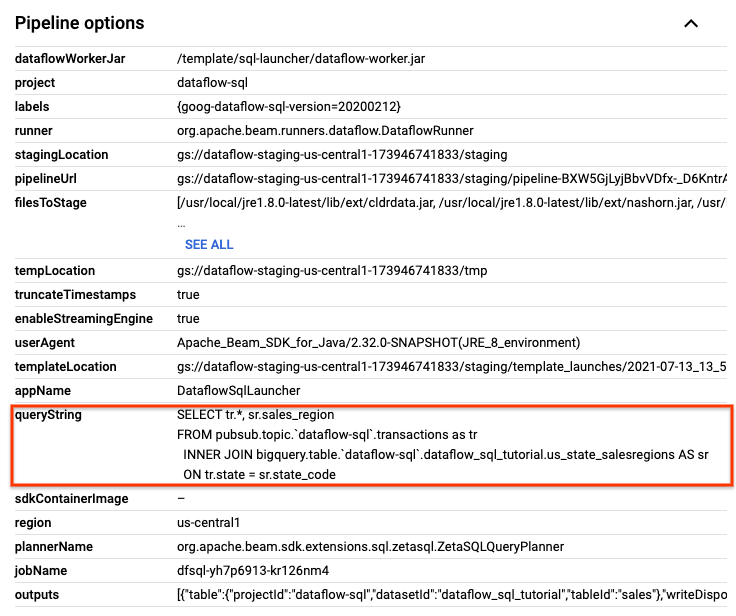
Copia y pega la siguiente consulta en SQL en el Editor de Dataflow SQL en el lugar de trabajo de SQL para agregar períodos de saltos de tamaño constante. Reemplaza project-id con el ID de tu proyecto.
SELECT sr.sales_region, TUMBLE_START("INTERVAL 15 SECOND") AS period_start, SUM(tr.amount) as amount FROM pubsub.topic.`project-id`.transactions AS tr INNER JOIN bigquery.table.`project-id`.dataflow_sql_tutorial.us_state_salesregions AS sr ON tr.state = sr.state_code GROUP BY sr.sales_region, TUMBLE(tr.event_timestamp, "INTERVAL 15 SECOND")
Haz clic en Crear trabajo para crear uno nuevo con la consulta modificada.
Limpia
Para evitar que se generen cargos en tu cuenta de facturación de Cloud por los recursos que se usaron en este instructivo, sigue estos pasos:
Detén tu secuencia de comandos de publicación
transactions_injector.pysi aún se está ejecutando.Detén tus trabajos de Dataflow en ejecución. Ve a la IU web de Dataflow en la consola de Google Cloud.
Para cada trabajo que creaste a partir de esta explicación, sigue estos pasos:
Haz clic en el nombre del trabajo.
En la página Detalles del trabajo, haz clic en Detener. Aparecerá el cuadro de diálogo Detener trabajo con las opciones para detenerlo:
Selecciona Cancelar.
Haz clic en Detener trabajo. El servicio detiene la transferencia y procesamiento de todos los datos lo antes posible. Debido a que Cancelar detiene el procesamiento de manera inmediata, es posible que pierdas los datos “en tránsito”. Detener un trabajo puede tardar unos minutos.
Borra tu conjunto de datos de BigQuery. Ve a la IU web de BigQuery en la consola de Google Cloud.
En el panel Explorador, en la sección Recursos, haz clic en el conjunto de datos dataflow_sql_tutorial que creaste.
En el panel de detalles, haz clic en Borrar. Se abrirá un cuadro de diálogo de confirmación.
En el cuadro de diálogo Borrar conjunto de datos, ingresa
deletepara confirmar el comando de eliminación y, luego, haz clic en Borrar.
Borra tu tema de Pub/Sub. Ve a la página Temas de Pub/Sub en la consola de Google Cloud.
Ir a la página de temas de Cloud Pub/Sub
Selecciona el tema
transactions.Haz clic en Borrar para borrar el tema de forma definitiva. Se abrirá un cuadro de diálogo de confirmación.
En el cuadro de diálogo Borrar tema, ingresa
deletepara confirmar el comando de eliminación y, luego, haz clic en Borrar.Ve a la página de suscripciones de Pub/Sub.
Selecciona las suscripciones a
transactionsrestantes. Si tus trabajos ya no están en ejecución, es posible que no haya ninguna suscripción.Haz clic en Borrar para borrar las suscripciones de manera permanente. En el diálogo de confirmación, haz clic en Borrar.
Borra el bucket de etapa de pruebas de Dataflow en Cloud Storage. Ve a la página Buckets de Cloud Storage en la consola de Google Cloud.
Selecciona el bucket de etapa de pruebas de Dataflow.
Haz clic en Borrar para borrar el depósito de manera permanente. Se abrirá un cuadro de diálogo de confirmación.
En el cuadro de diálogo Borrar bucket, ingresa
DELETEpara confirmar el comando de eliminación y, luego, haz clic en Borrar.
¿Qué sigue?
- Consulta la introducción a Dataflow SQL.
- Obtén información acerca de los conceptos básicos de la canalización de transmisión.
- Explora la referencia de Dataflow SQL.
- Mira el video streaming analytics demo (Demostración de las estadísticas de transmisión) de Cloud Next 2019.