Mantenha tudo organizado com as coleções
Salve e categorize o conteúdo com base nas suas preferências.
Nesta página, explicamos por que e como usar o
recurso MLTransform
para preparar seus dados para o treinamento de modelos de machine learning (ML). Ao combinar várias transformações de processamento de dados em uma classe, o MLTransform simplifica o processo de aplicação de operações de processamento de dados de ML do Apache Beam no fluxo de trabalho.
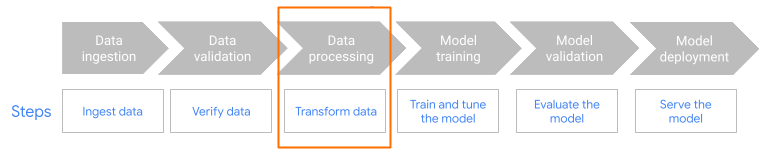
Figura 1. O fluxo de trabalho completo do Dataflow ML. Use
MLTransform na etapa de pré-processamento do fluxo de trabalho.
Benefícios
A classe MLTransform oferece os seguintes benefícios:
Transforme seus dados sem escrever códigos complexos ou gerenciar bibliotecas.
Gere embeddings que podem ser usados para enviar dados a bancos de dados de vetores ou executar inferência.
Encadeie vários tipos de operações de processamento de maneira eficiente com uma só interface.
Suporte e limitações
A classe MLTransform tem as seguintes limitações:
Disponível para pipelines que usam as versões 2.53.0 e posteriores do SDK do Apache Beam para Python.
Use a classe MLTransform do Apache Beam com a API text-embeddings da Vertex AI para gerar embeddings de texto. Os embeddings de texto são uma maneira de representar o texto como vetores numéricos, o que é necessário para muitas tarefas de processamento de linguagem natural (PLN).
Use a classe MLTransform do Apache Beam com modelos do Hugging Face Hub para gerar embeddings de texto. O framework SentenceTransformers da Hugging Face usa Python para gerar embeddings de sentenças, textos e imagens.
Compute um vocabulário exclusivo de um conjunto de dados e depois mapeie cada palavra ou token com um índice distinto de números inteiros. Use essa transformação para transformar dados textuais em representações numéricas para tarefas de machine learning.
Dimensione os dados para usá-los no treinamento do seu modelo de ML. A classe MLTransform do Apache Beam inclui várias transformações de dimensionamento de dados.
Para conferir uma lista completa de transformações disponíveis, consulte Transformações na documentação do Apache Beam.
Usar o MLTransform
Para usar a classe MLTransform para pré-processar dados, inclua o seguinte código no seu pipeline:
[[["Fácil de entender","easyToUnderstand","thumb-up"],["Meu problema foi resolvido","solvedMyProblem","thumb-up"],["Outro","otherUp","thumb-up"]],[["Difícil de entender","hardToUnderstand","thumb-down"],["Informações incorretas ou exemplo de código","incorrectInformationOrSampleCode","thumb-down"],["Não contém as informações/amostras de que eu preciso","missingTheInformationSamplesINeed","thumb-down"],["Problema na tradução","translationIssue","thumb-down"],["Outro","otherDown","thumb-down"]],["Última atualização 2025-04-22 UTC."],[[["\u003cp\u003e\u003ccode\u003eMLTransform\u003c/code\u003e streamlines the application of Apache Beam ML data processing operations by combining multiple transforms into a single class.\u003c/p\u003e\n"],["\u003cp\u003eThis class provides benefits such as transforming data without complex code, generating embeddings for vector databases, and efficiently chaining multiple processing operations.\u003c/p\u003e\n"],["\u003cp\u003e\u003ccode\u003eMLTransform\u003c/code\u003e supports both batch and streaming pipelines for text embedding generation using Vertex AI and Hugging Face, as well as batch pipelines for data processing transforms using TFT.\u003c/p\u003e\n"],["\u003cp\u003eThere are several examples available, including generating text embeddings with Vertex AI or Hugging Face, computing a vocabulary, and scaling data for ML models.\u003c/p\u003e\n"],["\u003cp\u003eTo use \u003ccode\u003eMLTransform\u003c/code\u003e, you must include specific code in your pipeline, replacing placeholder values with your transform name, bucket name, data, and transform function name.\u003c/p\u003e\n"]]],[],null,["# Preprocess data with MLTransform\n\nThis page explains why and how to use the\n[`MLTransform`](https://github.com/apache/beam/blob/3d501ee9dc208af2efef009daa98c49819b73ddc/sdks/python/apache_beam/ml/transforms/base.py#L112)\nfeature to prepare your data for training machine learning (ML) models. By\ncombining multiple data processing transforms in one class, `MLTransform`\nstreamlines the process of applying Apache Beam ML data processing\noperations to your workflow.\n\nFor information about using `MLTransform` for embedding generation tasks, see\n[Generate embeddings with MLTransform](/dataflow/docs/machine-learning/ml-generate-embeddings).\n\n**Figure 1.** The complete Dataflow ML workflow. Use `MLTransform` in the preprocessing step of the workflow.\n\nBenefits\n--------\n\nThe `MLTransform` class provides the following benefits:\n\n- Transform your data without writing complex code or managing underlying libraries.\n- Efficiently chain multiple types of processing operations with one interface.\n- Generate embeddings that you can use to push data into vector databases or\n to run inference.\n\n For more information about embedding generation, see\n [Generate embeddings with MLTransform](/dataflow/docs/machine-learning/ml-generate-embeddings).\n\nSupport and limitations\n-----------------------\n\nThe `MLTransform` class has the following limitations:\n\n- Available for pipelines that use the Apache Beam Python SDK versions 2.53.0 and later.\n- Pipelines must use [default windows](https://beam.apache.org/documentation/programming-guide/#single-global-window).\n\n**Data processing transforms that use TFT:**\n\n- Support Python 3.9, 3.10, 3.11.\n- Support batch pipelines.\n\nUse cases\n---------\n\nThe example notebooks demonstrate how to use `MLTransform` for\nembeddings-specific use cases.\n\n[I want to compute a vocabulary from a dataset](/dataflow/docs/notebooks/compute_and_apply_vocab)\n: Compute a unique vocabulary from a dataset and then map each word or token to\n a distinct integer index. Use this transform to change textual data into\n numerical representations for machine learning tasks.\n\n[I want to scale my data to train my ML model](/dataflow/docs/notebooks/scale_data)\n: Scale your data so that you can use it to train your ML model. The\n Apache Beam `MLTransform` class includes multiple data scaling transforms.\n\nFor a full list of available transforms, see\n[Transforms](https://beam.apache.org/documentation/ml/preprocess-data#transforms)\nin the Apache Beam documentation.\n\nUse MLTransform\n---------------\n\nTo use the `MLTransform` class to preprocess data, include the following code in\nyour pipeline: \n\n import apache_beam as beam\n from apache_beam.ml.transforms.base import MLTransform\n from apache_beam.ml.transforms.tft import \u003cvar translate=\"no\"\u003eTRANSFORM_NAME\u003c/var\u003e\n import tempfile\n\n data = [\n {\n \u003cvar translate=\"no\"\u003eDATA\u003c/var\u003e\n },\n ]\n\n artifact_location = gs://\u003cvar translate=\"no\"\u003eBUCKET_NAME\u003c/var\u003e\n \u003cvar translate=\"no\"\u003e\u003cspan class=\"devsite-syntax-nv\"\u003eTRANSFORM_FUNCTION_NAME\u003c/span\u003e\u003c/var\u003e = \u003cvar translate=\"no\"\u003eTRANSFORM_NAME\u003c/var\u003e(columns=['x'])\n\n with beam.Pipeline() as p:\n transformed_data = (\n p\n | beam.Create(data)\n | MLTransform(write_artifact_location=artifact_location).with_transform(\n \u003cvar translate=\"no\"\u003eTRANSFORM_FUNCTION_NAME\u003c/var\u003e)\n | beam.Map(print))\n\nReplace the following values:\n\n- \u003cvar translate=\"no\"\u003eTRANSFORM_NAME\u003c/var\u003e: the name of the [transform](https://beam.apache.org/documentation/ml/preprocess-data/#transforms) to use\n- \u003cvar translate=\"no\"\u003eBCUKET_NAME\u003c/var\u003e: the name of your [Cloud Storage bucket](/storage/docs/buckets#naming)\n- \u003cvar translate=\"no\"\u003eDATA\u003c/var\u003e: the input data to transform\n- \u003cvar translate=\"no\"\u003eTRANSFORM_FUNCTION_NAME\u003c/var\u003e: the name that you assign to your transform function in your code\n\nWhat's next\n-----------\n\n- For more details about `MLTransform`, see [Preprocess data](https://beam.apache.org/documentation/ml/preprocess-data) in the Apache Beam documentation.\n- For more examples, see [`MLTransform` for data processing](https://beam.apache.org/documentation/transforms/python/elementwise/mltransform) in the Apache Beam transform catalog.\n- Run an [interactive notebook in Colab](https://colab.sandbox.google.com/github/apache/beam/blob/master/examples/notebooks/beam-ml/mltransform_basic.ipynb)."]]