您可以使用 RunInference API 建構包含多個模型的管道。多模型管線適用於 A/B 測試和建構組合等工作,可解決需要多個機器學習模型的業務問題。
使用多個模型
以下程式碼範例說明如何使用 RunInference 轉換,將多個模型新增至管道。
使用多個模型建構管道時,您可以採用下列兩種模式之一:
- A/B 分支模式:一部分的輸入資料會傳送至一個模型,其餘資料則傳送至第二個模型。
- 序列模式:輸入資料會依序經過兩個模型。
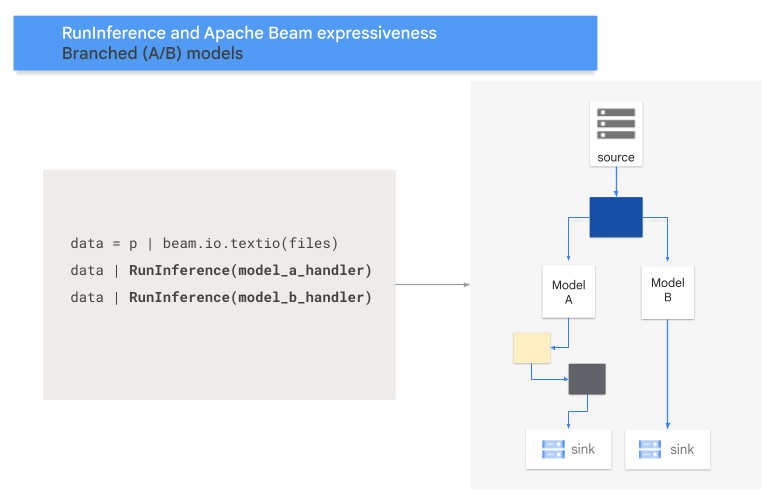
A/B 模式
下列程式碼顯示如何使用 RunInference 轉換,將 A/B 模式新增至管道。
with pipeline as p:
data = p | 'Read' >> beam.ReadFromSource('a_source')
model_a_predictions = data | RunInference(MODEL_HANDLER_A)
model_b_predictions = data | RunInference(MODEL_HANDLER_B)
MODEL_HANDLER_A 和 MODEL_HANDLER_B 是模型處理常式設定程式碼。
下圖以視覺化方式呈現這個程序。
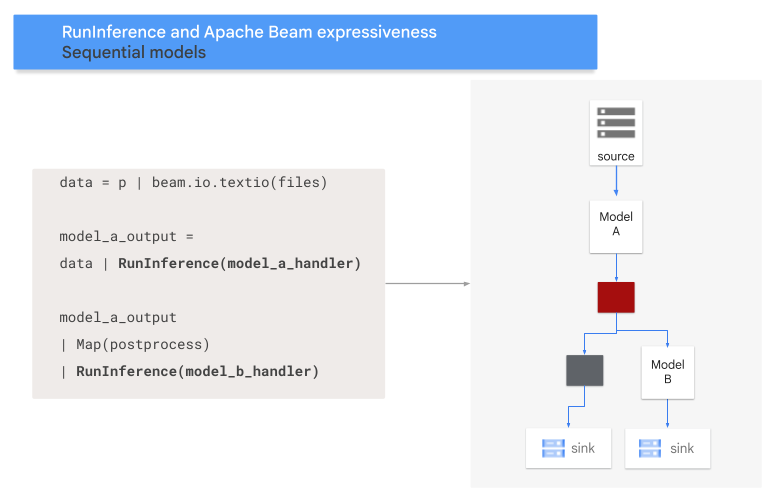
序列模式
下列程式碼顯示如何使用 RunInference 轉換,將序列模式新增至管道。
with pipeline as p:
data = p | 'Read' >> beam.ReadFromSource('A_SOURCE')
model_a_predictions = data | RunInference(MODEL_HANDLER_A)
model_b_predictions = model_a_predictions | beam.Map(some_post_processing) | RunInference(MODEL_HANDLER_B)
MODEL_HANDLER_A 和 MODEL_HANDLER_B 是模型處理常式設定程式碼。
下圖以視覺化方式呈現這個程序。
將模型對應至金鑰
您可以載入多個模型,並使用鍵控模型處理常式將模型對應至鍵。將模型對應至鍵,即可在同一個 RunInference 轉換中使用不同模型。下列範例使用鍵控模型處理常式,透過 CONFIG_1 載入一個模型,並透過 CONFIG_2 載入第二個模型。管道會使用與 CONFIG_1 相關聯的模型,對與 KEY_1 相關聯的範例執行推論。
與 CONFIG_2 相關聯的模型會對與 KEY_2 和 KEY_3 相關聯的範例執行推論。
from apache_beam.ml.inference.base import KeyedModelHandler
keyed_model_handler = KeyedModelHandler([
KeyModelMapping(['KEY_1'], PytorchModelHandlerTensor(CONFIG_1)),
KeyModelMapping(['KEY_2', 'KEY_3'], PytorchModelHandlerTensor(CONFIG_2))
])
with pipeline as p:
data = p | beam.Create([
('KEY_1', torch.tensor([[1,2,3],[4,5,6],...])),
('KEY_2', torch.tensor([[1,2,3],[4,5,6],...])),
('KEY_3', torch.tensor([[1,2,3],[4,5,6],...])),
])
predictions = data | RunInference(keyed_model_handler)
如需更詳細的範例,請參閱「使用多個訓練方式不同的模型執行機器學習推論」。
管理記憶體
同時載入多個模型時,可能會發生記憶體不足錯誤 (OOM)。使用鍵控模型處理常式時,Apache Beam 不會自動限制載入記憶體的模型數量。如果模型無法完全載入記憶體,就會發生記憶體不足錯誤,導致管道失敗。
如要避免這個問題,請使用 max_models_per_worker_hint 參數,限制同時載入記憶體的模型數量。以下範例使用含 max_models_per_worker_hint 參數的鍵控模型處理常式。由於 max_models_per_worker_hint 參數值設為 2,管道會在每個 SDK 工作站程序上同時載入最多兩個模型。
mhs = [
KeyModelMapping(['KEY_1'], PytorchModelHandlerTensor(CONFIG_1)),
KeyModelMapping(['KEY_2', 'KEY_3'], PytorchModelHandlerTensor(CONFIG_2)),
KeyModelMapping(['KEY_4'], PytorchModelHandlerTensor(CONFIG_3)),
KeyModelMapping(['KEY_5', 'KEY_5', 'KEY_6'], PytorchModelHandlerTensor(CONFIG_4)),
]
keyed_model_handler = KeyedModelHandler(mhs, max_models_per_worker_hint=2)
設計管道時,請確保工作站有足夠的記憶體,可同時處理模型和管道轉換。由於模型使用的記憶體可能不會立即釋出,為避免發生 OOM,請加入額外的記憶體緩衝區。
如果您有很多模型,且 max_models_per_worker_hint 參數的值很小,可能會遇到記憶體顛簸。如果系統花費過多執行時間,在記憶體中交換模型,就會發生記憶體顛簸。為避免這個問題,請在推論步驟前,於管道中加入 GroupByKey 轉換。GroupByKey 轉換可確保具有相同鍵和模型的元素位於相同的工作站。
瞭解詳情
- 請參閱 Apache Beam 說明文件,瞭解多模型管道
- 使用多個以不同方式訓練的模型執行機器學習推論。
- 在 Colab 中執行互動式筆記本。