Pode usar a API RunInference para criar pipelines que contenham vários modelos. Os pipelines
com vários modelos são úteis para tarefas como testes A/B e criação de conjuntos para
resolver problemas empresariais que requerem mais do que um modelo de ML.
Use vários modelos
Os exemplos de código seguintes mostram como usar a transformação RunInference para adicionar vários modelos ao seu pipeline.
Quando cria pipelines com vários modelos, pode usar um de dois padrões:
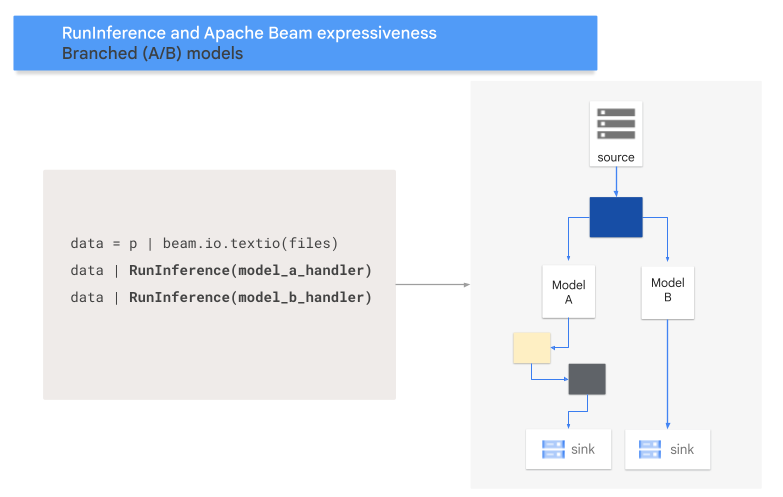
- Padrão de ramificação A/B: uma parte dos dados de entrada é enviada para um modelo e o resto dos dados é enviado para um segundo modelo.
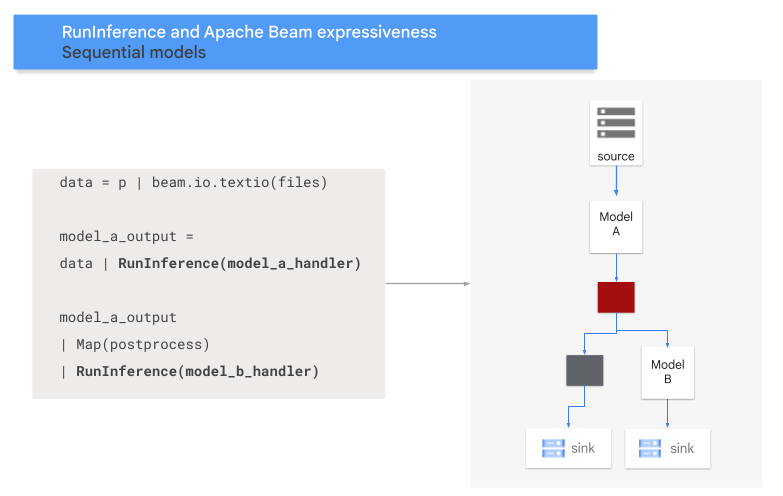
- Padrão de sequência: os dados de entrada percorrem dois modelos, um após o outro.
Padrão A/B
O código seguinte mostra como adicionar um padrão A/B ao seu pipeline com a transformação RunInference.
with pipeline as p:
data = p | 'Read' >> beam.ReadFromSource('a_source')
model_a_predictions = data | RunInference(MODEL_HANDLER_A)
model_b_predictions = data | RunInference(MODEL_HANDLER_B)
MODEL_HANDLER_A e MODEL_HANDLER_B são o código de configuração do controlador do modelo.
O diagrama seguinte apresenta uma representação visual deste processo.
Padrão de sequência
O código seguinte mostra como adicionar um padrão de sequência ao seu pipeline com a transformação RunInference.
with pipeline as p:
data = p | 'Read' >> beam.ReadFromSource('A_SOURCE')
model_a_predictions = data | RunInference(MODEL_HANDLER_A)
model_b_predictions = model_a_predictions | beam.Map(some_post_processing) | RunInference(MODEL_HANDLER_B)
MODEL_HANDLER_A e MODEL_HANDLER_B são o código de configuração do controlador do modelo.
O diagrama seguinte apresenta uma representação visual deste processo.
Mapeie modelos para chaves
Pode carregar vários modelos e mapeá-los para chaves através de um processador de modelos com chaves.
A associação de modelos a chaves permite usar diferentes modelos na mesma transformação RunInference.
O exemplo seguinte usa um controlador de modelo com chave que
carrega um modelo através de CONFIG_1 e um segundo modelo através de CONFIG_2.
O pipeline usa o modelo associado a CONFIG_1 para executar a inferência em exemplos associados a KEY_1.
O modelo associado a CONFIG_2 executa a inferência em exemplos associados a KEY_2 e KEY_3.
from apache_beam.ml.inference.base import KeyedModelHandler
keyed_model_handler = KeyedModelHandler([
KeyModelMapping(['KEY_1'], PytorchModelHandlerTensor(CONFIG_1)),
KeyModelMapping(['KEY_2', 'KEY_3'], PytorchModelHandlerTensor(CONFIG_2))
])
with pipeline as p:
data = p | beam.Create([
('KEY_1', torch.tensor([[1,2,3],[4,5,6],...])),
('KEY_2', torch.tensor([[1,2,3],[4,5,6],...])),
('KEY_3', torch.tensor([[1,2,3],[4,5,6],...])),
])
predictions = data | RunInference(keyed_model_handler)
Para um exemplo mais detalhado, consulte o artigo Execute a inferência de ML com vários modelos preparados de forma diferente.
Faça a gestão da memória
Quando carrega vários modelos em simultâneo, podem ocorrer erros de falta de memória (OOM). Quando usa um controlador de modelo com chave, o Apache Beam não limita automaticamente o número de modelos carregados na memória. Quando os modelos não cabem todos na memória, ocorre um erro de falta de memória e o pipeline falha.
Para evitar este problema, use o parâmetro max_models_per_worker_hint para limitar o número de modelos que são carregados na memória ao mesmo tempo. O exemplo seguinte
usa um controlador de modelo com chave com o parâmetro max_models_per_worker_hint.
Uma vez que o valor do parâmetro max_models_per_worker_hint está definido como 2,
o pipeline carrega um máximo de dois modelos em cada processo de trabalho do SDK em simultâneo.
mhs = [
KeyModelMapping(['KEY_1'], PytorchModelHandlerTensor(CONFIG_1)),
KeyModelMapping(['KEY_2', 'KEY_3'], PytorchModelHandlerTensor(CONFIG_2)),
KeyModelMapping(['KEY_4'], PytorchModelHandlerTensor(CONFIG_3)),
KeyModelMapping(['KEY_5', 'KEY_5', 'KEY_6'], PytorchModelHandlerTensor(CONFIG_4)),
]
keyed_model_handler = KeyedModelHandler(mhs, max_models_per_worker_hint=2)
Ao criar o seu pipeline, certifique-se de que os trabalhadores têm memória suficiente para os modelos e as transformações do pipeline. Uma vez que a memória usada pelos modelos pode não ser libertada imediatamente, para evitar erros de falta de memória, inclua um buffer de memória adicional.
Se tiver muitos modelos e usar um valor baixo com o parâmetro max_models_per_worker_hint, pode ocorrer um problema de memória. A instabilidade da memória ocorre quando é usado um tempo de execução excessivo para trocar modelos na memória. Para evitar este problema, inclua uma transformação GroupByKey no pipeline antes do passo de inferência. A transformação GroupByKey garante que os elementos com a mesma chave e modelo estão localizados no mesmo trabalhador.
Saiba mais
- Leia acerca dos pipelines de vários modelos na documentação do Apache Beam
- Executar inferência de ML com vários modelos preparados de forma diferente.
- Execute um bloco de notas interativo no Colab.