SAP와 통합
이 페이지에서는 Cortex Framework Data Foundation에서 SAP 운영 워크로드(SAP ECC 및 SAP S/4 HANA)를 통합하는 단계를 설명합니다. Cortex Framework는 BigQuery를 통해 Dataflow 파이프라인을 사용하여 사전 정의된 데이터 처리 템플릿으로 SAP 데이터와 BigQuery의 통합을 가속화할 수 있으며, Cloud Composer는 SAP 운영 데이터에서 통계를 얻기 위해 이러한 Dataflow 파이프라인을 예약하고 모니터링합니다.
Cortex Framework Data Foundation 저장소의 config.json 파일은 SAP를 비롯한 모든 데이터 소스에서 데이터를 전송하는 데 필요한 설정을 구성합니다. 이 파일에는 운영 SAP 워크로드에 관한 다음 매개변수가 포함되어 있습니다.
"SAP": {
"deployCDC": true,
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING"
},
"SQLFlavor": "ecc",
"mandt": "100"
}
다음 표에서는 각 SAP 운영 매개변수의 값을 설명합니다.
| 매개변수 | 의미 | 기본값 | 설명 |
SAP.deployCDC
|
CDC 배포 | true
|
Cloud Composer에서 DAG로 실행할 CDC 처리 스크립트를 생성합니다. |
SAP.datasets.raw
|
원시 시작 데이터 세트 | - | CDC 프로세스에서 사용되며, 복제 도구가 SAP에서 데이터를 가져오는 위치입니다. 테스트 데이터를 사용하는 경우 빈 데이터 세트를 만듭니다. |
SAP.datasets.cdc
|
CDC 처리된 데이터 세트 | - | 보고 뷰의 소스로 작동하고 레코드 처리 DAG의 타겟으로 작동하는 데이터 세트입니다. 테스트 데이터를 사용하는 경우 빈 데이터 세트를 만듭니다. |
SAP.datasets.reporting
|
보고 데이터 세트 SAP | "REPORTING"
|
보고를 위해 최종 사용자가 액세스할 수 있는 데이터 세트의 이름입니다. 뷰와 사용자 대상 테이블이 배포됩니다. |
SAP.SQLFlavor
|
소스 시스템의 SQL 버전 | "ecc"
|
s4 또는 ecc입니다.
테스트 데이터의 경우 기본값 (ecc)을 유지합니다.
|
SAP.mandt
|
Mandant 또는 Client | "100"
|
SAP의 기본 mandant 또는 클라이언트입니다.
테스트 데이터의 경우 기본값 (100)을 유지합니다.
|
SAP.languages
|
언어 필터 | ["E","S"]
|
관련 필드 (예: 이름)에 사용할 SAP 언어 코드 (SPRAS)입니다. |
SAP.currencies
|
통화 필터 | ["USD"]
|
통화 변환을 위한 SAP 타겟 통화 코드 (TCURR)입니다. |
필요한 최소 버전의 SAP는 없지만 ECC 모델은 현재 지원되는 가장 오래된 SAP ECC 버전에서 개발되었습니다. 버전에 관계없이 YouTube 시스템과 다른 시스템 간의 필드 차이는 예상됩니다.
데이터 모델
이 섹션에서는 엔티티 관계 다이어그램 (ERD)을 사용하여 SAP (ECC 및 S/4 HANA) 데이터 모델을 설명합니다.
SAP ECC

SAP S/4 HANA
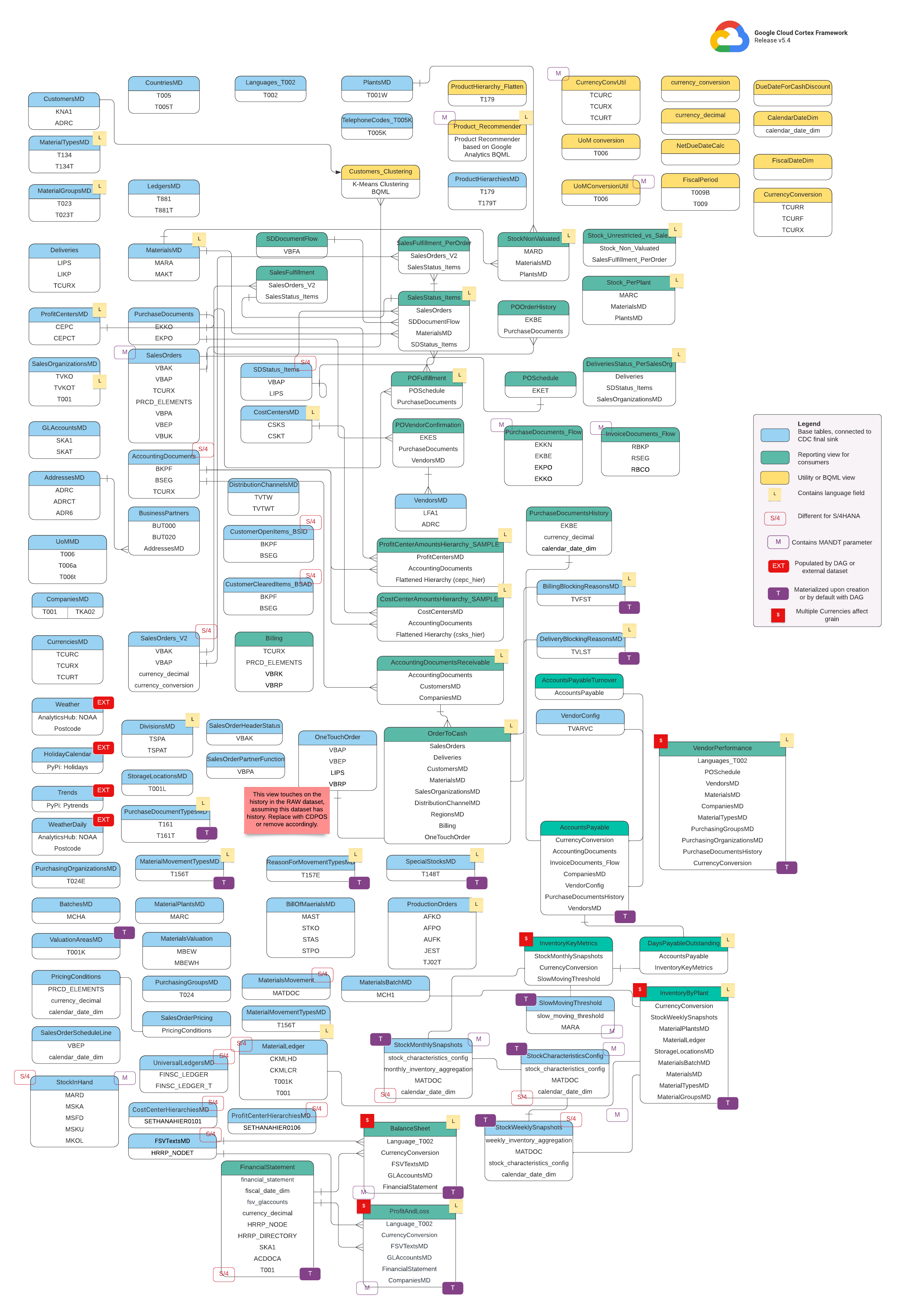
기본 뷰
ERD의 파란색 객체이며 일부 열 이름 별칭 외에는 변환이 없는 CDC 테이블의 뷰입니다. src/SAP/SAP_REPORTING의 스크립트를 참고하세요.
보고 보기
ERD의 녹색 객체이며 보고 테이블에서 사용하는 관련 측정기준 속성이 포함되어 있습니다. src/SAP/SAP_REPORTING의 스크립트를 참고하세요.
유틸리티 또는 BQML 보기
ERD의 노란색 객체이며 데이터 분석 및 보고에 사용되는 특정 유형의 뷰에 조인된 팩트와 측정기준이 포함됩니다. src/SAP/SAP_REPORTING의 스크립트를 참고하세요.
추가 태그
이 ERD의 색상으로 구분된 태그는 보고 테이블의 다음 기능을 나타냅니다.
| 태그 | 색상 | 설명 |
L
|
노란색 | 이 태그는 데이터가 저장되거나 표시되는 언어를 지정하는 데이터 요소 또는 속성을 나타냅니다. |
S/4
|
빨간색 | 이 태그는 특정 속성이 SAP S/4 HANA에만 적용됨을 나타냅니다(이 객체는 SAP ECC에 없을 수 있음). |
MANDT
|
보라색 | 이 태그는 특정 속성에 특정 데이터 레코드가 속한 클라이언트 또는 회사 인스턴스를 결정하는 MANDT 매개변수(클라이언트 또는 클라이언트 ID를 나타냄)가 포함되어 있음을 나타냅니다. |
EXT
|
빨간색 | 이 태그는 특정 객체가 DAG 또는 외부 데이터 세트로 채워져 있음을 나타냅니다. 이는 표시된 항목 또는 표가 SAP 시스템 자체에 직접 저장되지 않지만 DAG 또는 기타 메커니즘을 사용하여 추출하여 SAP에 로드할 수 있음을 의미합니다. |
T
|
보라색 | 이 태그는 구성된 DAG를 사용하여 특정 속성이 자동으로 구체화됨을 나타냅니다. |
S
|
빨간색 | 이 태그는 항목 또는 테이블 내 데이터가 여러 통화의 영향을 받거나 영향을 미침을 나타냅니다. |
SAP 복제의 기본 요건
Cortex Framework Data Foundation을 사용한 SAP 복제 데이터의 다음 필수 요건을 고려하세요.
- 데이터 무결성: Cortex Framework Data Foundation에서는 SAP 테이블이 SAP에 있는 것과 동일한 필드 이름, 유형, 데이터 구조로 복제될 것으로 예상합니다. 테이블이 소스와 동일한 형식, 필드 이름, 세부사항으로 복제되는 한 특정 복제 도구를 사용할 필요가 없습니다.
- 테이블 이름 지정: BigQuery 테이블 이름은 소문자로 만들어야 합니다.
- 표 구성: SAP 모델에서 사용되는 표 목록은 CDC (변경 데이터 캡처)
cdc_settings.yaml파일에서 확인하고 구성할 수 있습니다. 배포 중에 테이블이 나열되지 않으면 테이블에 종속된 모델은 실패하지만 종속되지 않은 다른 모델은 성공적으로 배포됩니다. - SAP용 BigQuery 커넥터 관련 고려사항:
- 표 매핑: 변환 옵션에 관해서는 기본 표 매핑 문서를 따르세요.
- 레코드 압축 사용 중지: Cortex CDC 레이어와 Cortex 보고 데이터 세트에 모두 영향을 줄 수 있는 레코드 압축을 사용 중지하는 것이 좋습니다.
- 메타데이터 복제: 배포 중에 테스트 데이터를 배포하고 CDC DAG 스크립트를 생성하지 않는 경우 소스 프로젝트의 SAP에서 SAP 메타데이터용 테이블
DD03L가 복제되었는지 확인합니다. 이 표에는 키 목록과 같은 테이블에 관한 메타데이터가 포함되어 있으며 CDC 생성기와 종속성 리졸버가 작동하는 데 필요합니다. 이 표를 사용하면 모델에서 다루지 않는 표(예: 맞춤 표 또는 Z 표)를 추가하여 CDC 스크립트를 생성할 수도 있습니다. 사소한 테이블 이름 변형 처리: 테이블 이름에 사소한 차이가 있는 경우 SAP 시스템에 버전이나 부가기능으로 인해 사소한 변형이 있거나 일부 복제 도구에서 특수 문자를 약간 다르게 처리할 수 있으므로 일부 뷰에서 필수 필드를 찾지 못할 수 있습니다. 한 번의 시도로 가장 많은 실패를 발견하려면
turboMode : false로 배포를 실행하는 것이 좋습니다. 일반적인 문제는 다음과 같습니다._로 시작하는 필드 (예:_DATAAGING)에서_이 삭제됩니다.- BigQuery에서 필드는
/로 시작할 수 없습니다.
이 경우 실패한 뷰를 조정하여 선택한 복제 도구에서 필드가 배치된 대로 선택할 수 있습니다.
SAP에서 원시 데이터 복제
데이터 파운데이션의 목적은 보고 및 애플리케이션을 위해 데이터 및 분석 모델을 노출하는 것입니다. 모델은 SAP용 데이터 통합 가이드에 나열된 것과 같은 기본 복제 도구를 사용하여 SAP 시스템에서 복제된 데이터를 사용합니다.
SAP 시스템 (ECC 또는 S/4 HANA)의 데이터가 원시 형식으로 복제됩니다.
데이터는 구조 변경 없이 SAP에서 BigQuery로 직접 복사됩니다. 기본적으로 SAP 시스템의 테이블 미러 이미지입니다. BigQuery는 데이터 모델에 소문자 테이블 이름을 사용합니다. 따라서 SAP 테이블의 이름이 대문자 (예: MANDT)인 경우에도 BigQuery에서는 소문자 (예: mandt)로 변환됩니다.
변경 데이터 캡처 (CDC) 처리
복제 도구가 SAP에서 레코드를 로드할 수 있도록 Cortex Framework에서 제공하는 다음 CDC 처리 모드 중 하나를 선택합니다.
- Append-always: 타임스탬프와 작업 플래그 (삽입, 업데이트, 삭제)를 사용하여 레코드의 모든 변경사항을 삽입하므로 마지막 버전을 식별할 수 있습니다.
- 랜딩 시 업데이트 (병합 또는 upsert):
change data capture processed에 랜딩할 때 레코드의 업데이트된 버전을 만듭니다. BigQuery에서 CDC 작업을 실행합니다.
Cortex Framework 데이터 기반은 두 모드를 모두 지원하지만 항상 추가의 경우 CDC 처리 템플릿을 제공합니다. 일부 기능은 착륙 시 업데이트를 위해 주석 처리해야 합니다. 예를 들어 OneTouchOrder.sql 및 모든 종속 쿼리입니다. 이 기능은 CDPOS와 같은 테이블로 대체할 수 있습니다.

항상 추가 모드로 복제하는 도구의 CDC 템플릿 구성
필요에 따라 cdc_settings.yaml을 구성하는 것이 좋습니다.
비즈니스에 이러한 수준의 데이터 업데이트 빈도가 필요하지 않은 경우 일부 기본 빈도로 인해 불필요한 비용이 발생할 수 있습니다. 항상 추가 모드로 실행되는 도구를 사용하는 경우 Cortex Framework Data Foundation은 CDC 템플릿을 제공하여 업데이트를 자동화하고 CDC 처리된 데이터 세트에서 최신 버전의 진실 또는 디지털 트윈을 만듭니다.
CDC 처리 스크립트를 생성해야 하는 경우 cdc_settings.yaml 파일의 구성을 사용할 수 있습니다. 옵션은 CDC 처리 설정을 참고하세요. 테스트 데이터의 경우 이 파일을 기본값으로 둘 수 있습니다.
Airflow 또는 Cloud Composer 인스턴스에 따라 DAG 템플릿을 필요한 대로 모두 변경합니다. 자세한 내용은 Cloud Composer 설정 수집을 참고하세요.
선택사항: 배포 후 테이블을 개별적으로 추가하고 처리하려면 cdc_settings.yaml 파일을 수정하여 필요한 테이블만 처리하고 src/SAP_CDC/cloudbuild.cdc.yaml을 직접 호출하는 지정된 모듈을 다시 실행합니다.
CDC 처리 설정
배포 중에 BigQuery의 뷰를 사용하거나 Cloud Composer (또는 기타 Apache Airflow 인스턴스)에서 병합 작업을 예약하여 변경사항을 실시간으로 병합할 수 있습니다. Cloud Composer는 병합 작업을 주기적으로 처리하도록 스크립트를 예약할 수 있습니다. 병합 작업이 실행될 때마다 데이터가 최신 버전으로 업데이트되지만 병합 작업이 더 자주 실행되면 비용이 증가합니다. 비즈니스 요구사항에 따라 예약된 빈도를 맞춤설정합니다. 자세한 내용은 Apache Airflow에서 지원하는 일정 예약을 참고하세요.
다음 예시 스크립트는 구성 파일의 일부를 보여줍니다.
data_to_replicate:
- base_table: adrc
load_frequency: "@hourly"
- base_table: adr6
target_table: adr6_cdc
load_frequency: "@daily"
이 구성 샘플 파일은 다음을 수행합니다.
TARGET_PROJECT_ID.DATASET_WITH_LATEST_RECORDS.adrc이 없으면SOURCE_PROJECT_ID.REPLICATED_DATASET.adrc에서TARGET_PROJECT_ID.DATASET_WITH_LATEST_RECORDS.adrc로 복사합니다.- 지정된 버킷에 CDC 스크립트를 만듭니다.
TARGET_PROJECT_ID.DATASET_WITH_LATEST_RECORDS.adr6_cdc이 없으면SOURCE_PROJECT_ID.REPLICATED_DATASET.adr6에서TARGET_PROJECT_ID.DATASET_WITH_LATEST_RECORDS.adr6_cdc로 복사합니다.- 지정된 버킷에 CDC 스크립트를 만듭니다.
SAP에 있고 파일에 나열되지 않은 테이블의 변경사항을 처리하는 DAG 또는 런타임 뷰를 만들려면 배포 전에 이 파일에 추가하세요. 테이블 DD03L이 소스 데이터 세트에 복제되고 맞춤 테이블의 스키마가 해당 테이블에 있는 경우에 작동합니다.
예를 들어 다음 구성은 맞춤 테이블 zztable_customer의 CDC 스크립트와 런타임 뷰를 만들어 zzspecial_table이라는 다른 맞춤 테이블의 변경사항을 실시간으로 스캔합니다.
- base_table: zztable_customer
load_frequency: "@daily"
- base_table: zzspecial_table
load_frequency: "RUNTIME"
생성된 템플릿 샘플
다음 템플릿은 변경사항 처리를 생성합니다. 타임스탬프 필드의 이름이나 추가 작업과 같은 수정사항은 이 시점에서 수정할 수 있습니다.
MERGE `${target_table}` T
USING (
SELECT *
FROM `${base_table}`
WHERE
recordstamp > (
SELECT IF(
MAX(recordstamp) IS NOT NULL,
MAX(recordstamp),
TIMESTAMP("1940-12-25 05:30:00+00"))
FROM `${target_table}` )
) S
ON ${p_key}
WHEN MATCHED AND S.operation_flag='D' AND S.is_deleted = true THEN
DELETE
WHEN NOT MATCHED AND S.operation_flag='I' THEN
INSERT (${fields})
VALUES
(${fields})
WHEN MATCHED AND S.operation_flag='U' THEN
UPDATE SET
${update_fields}
또는 비즈니스에 거의 실시간 통계가 필요하고 복제 도구에서 이를 지원하는 경우 배포 도구는 RUNTIME 옵션을 허용합니다.
즉, CDC 스크립트가 생성되지 않습니다. 대신 뷰는 런타임에 즉각적 일관성을 위해 사용 가능한 최신 레코드를 스캔하고 가져옵니다.
CDC DAG 및 스크립트의 디렉터리 구조
SAP CDC DAG의 Cloud Storage 버킷 구조는 다음 예와 같이 SQL 파일이 /data/bq_data_replication에 생성될 것으로 예상합니다.
배포 전에 이 경로를 수정할 수 있습니다. 아직 Cloud Composer 환경이 없는 경우 나중에 환경을 만들고 파일을 DAG 버킷으로 이동하면 됩니다.
with airflow.DAG("CDC_BigQuery_${base table}",
template_searchpath=['/home/airflow/gcs/data/bq_data_replication/'], ##example
default_args=default_dag_args,
schedule_interval="${load_frequency}") as dag:
start_task = DummyOperator(task_id="start")
copy_records = BigQueryOperator(
task_id='merge_query_records',
sql="${query_file}",
create_disposition='CREATE_IF_NEEDED',
bigquery_conn_id="sap_cdc_bq", ## example
use_legacy_sql=False)
stop_task = DummyOperator (task_id="stop")
start_task >> copy_records >> stop_task
Airflow 또는 Cloud Composer에서 데이터를 처리하는 스크립트는 Airflow 전용 스크립트와 별도로 생성됩니다. 이를 통해 원하는 다른 도구로 스크립트를 포팅할 수 있습니다.
병합 작업에 필요한 CDC 필드
CDC 일괄 처리의 자동 생성을 위해 다음 매개변수를 지정합니다.
- 소스 프로젝트 + 데이터 세트: SAP 데이터가 스트리밍되거나 복제되는 데이터 세트입니다. CDC 스크립트가 기본적으로 작동하려면 테이블에 타임스탬프 필드 (recordstamp라고 함)와 다음 값이 있는 작업 필드가 있어야 하며, 이 모든 필드는 복제 중에 설정됩니다.
- I: 삽입
- U: 업데이트
- D: 삭제
- CDC 처리를 위한 대상 프로젝트 + 데이터 세트: 기본적으로 생성된 스크립트는 소스 데이터 세트의 복사본에서 테이블이 없는 경우 테이블을 생성합니다.
- 복제된 테이블: 스크립트를 생성해야 하는 테이블
- 처리 빈도: 크론 표기법에 따라 DAG가 실행되는 빈도입니다.
- CDC 출력 파일이 복사되는 타겟 Cloud Storage 버킷입니다.
- 연결 이름: Cloud Composer에서 사용하는 연결의 이름입니다.
- (선택사항) 대상 테이블 이름: CDC 처리 결과가 대상과 동일한 데이터 세트에 남아 있는 경우 사용할 수 있습니다.
CDC 테이블의 성능 최적화
특정 CDC 데이터 세트의 경우 BigQuery 테이블 파티셔닝, 테이블 클러스터링 또는 둘 다를 활용할 수 있습니다. 이 선택은 다음 요인에 따라 달라집니다.
- 표의 크기와 데이터입니다.
- 표에서 사용할 수 있는 열입니다.
- 뷰를 사용한 실시간 데이터 필요
- 표로 구체화된 데이터입니다.
기본적으로 CDC 설정은 테이블 파티션 나누기 또는 테이블 클러스터링을 적용하지 않습니다.
가장 적합한 방식에 따라 구성할 수 있습니다. 파티션 또는 클러스터가 있는 테이블을 만들려면 관련 구성으로 cdc_settings.yaml 파일을 업데이트합니다. 자세한 내용은 테이블 파티션 및 클러스터 설정을 참고하세요.
- 이 기능은
cdc_settings.yaml의 데이터 세트가 테이블로 복제되도록 구성된 경우 (예:load_frequency = "@daily")에만 적용되며 뷰 (load_frequency = "RUNTIME")로 정의된 경우에는 적용되지 않습니다. - 테이블은 파티션을 나눈 테이블과 클러스터링된 테이블 모두일 수 있습니다.
SAP용 BigQuery 커넥터와 같이 원시 데이터 세트에서 파티션을 허용하는 복제 도구를 사용하는 경우 원시 테이블에서 시간 기반 파티션을 설정하는 것이 좋습니다. 파티션 유형은 cdc_settings.yaml 구성의 CDC DAG 빈도와 일치하는 경우 더 효과적입니다. 자세한 내용은 BigQuery에서 SAP 데이터 모델링 시 설계 고려사항을 참고하세요.
선택사항: SAP 인벤토리 모듈 구성
Cortex Framework SAP Inventory 모듈에는 재고에 관한 주요 통계를 제공하는 InventoryKeyMetrics 및 InventoryByPlant 뷰가 포함되어 있습니다.
이러한 뷰는 전문 DAG를 사용하는 월별 및 주별 스냅샷 테이블을 기반으로 합니다. 두 가지 모두 동시에 실행할 수 있으며 서로 간섭하지 않습니다.
스냅샷 테이블을 하나 또는 둘 다 업데이트하려면 다음 단계를 따르세요.
요구사항에 따라 다양한 소재 유형의 느린 이동 임계값과 재고 특성을 정의하도록
SlowMovingThreshold.sql및StockCharacteristicsConfig.sql를 업데이트합니다.초기 로드 또는 전체 새로고침의 경우
Stock_Monthly_Snapshots_Initial및Stock_Weekly_Snapshots_InitialDAG를 실행합니다.후속 새로고침의 경우 다음 DAG를 예약하거나 실행합니다.
- 월별 및 주간 업데이트:
Stock_Monthly_Snapshots_Periodical_UpdateStock_Weekly_Snapshots_periodical_Update
- 일일 업데이트:
Stock_Monthly_Snapshots_Daily_UpdateStock_Weekly_Snapshots_Update_Daily
- 월별 및 주간 업데이트:
새로고침된 데이터를 표시하기 위해 중간
StockMonthlySnapshots및StockWeeklySnapshots뷰를 새로고침한 후 각각InventoryKeyMetrics및InventoryByPlants뷰를 새로고침합니다.
선택사항: 제품 계층 구조 텍스트 보기 구성
제품 계층 구조 텍스트 뷰는 재료와 해당 제품 계층 구조를 평면화합니다. 결과 테이블을 사용하여 Trends 부가기능에 시간에 따른 관심도를 가져올 용어 목록을 제공할 수 있습니다. 다음 단계에 따라 이 뷰를 구성합니다.
## CORTEX-CUSTOMER마커 아래의prod_hierarchy_texts.sql파일에서 계층 구조의 수준과 언어를 조정합니다.제품 계층 구조에 더 많은 수준이 포함되어 있는 경우 공통 테이블 표현식
h1_h2_h3과 유사한 SELECT 문을 추가해야 할 수 있습니다.소스 시스템에 따라 추가 맞춤설정이 있을 수 있습니다. 이러한 문제를 파악할 수 있도록 프로세스 초기에 비즈니스 사용자나 분석가를 참여시키는 것이 좋습니다.
선택사항: 계층 구조 평면화 뷰 구성
v6.0 출시부터 Cortex Framework는 계층 구조 평면화를 보고 뷰로 지원합니다. 이제 전체 계층 구조를 평면화하고, 기존 ECC 테이블 대신 S/4 전용 테이블을 활용하여 S/4에 맞게 더 잘 최적화하며, 성능도 크게 개선되므로 기존 계층 구조 평면화 도구에 비해 크게 개선되었습니다.
보고 보기 요약
계층 구조 평면화와 관련된 다음 뷰를 찾습니다.
| 계층 구조 유형 | 플랫 계층 구조만 포함하는 표 | 평면화된 계층 구조를 시각화하는 뷰 | 이 계층 구조를 사용하는 손익계산서 통합 논리 |
| 재무제표 버전 (FSV) | fsv_glaccounts
|
FSVHierarchyFlattened
|
ProfitAndLossOverview
|
| 수익 센터 | profit_centers
|
ProfitCenterHierarchyFlattened
|
ProfitAndLossOverview_ProfitCenterHierarchy
|
| 비용 센터 | cost_centers
|
CostCenterHierarchyFlattened
|
ProfitAndLossOverview_CostCenterHierarchy
|
계층 구조 평면화 뷰를 사용할 때는 다음 사항을 고려하세요.
- 계층 구조 평면화 전용 보기는 기존 계층 구조 평면화 도구 솔루션에서 생성된 표와 기능적으로 동일합니다.
- 개요 뷰는 BI 로직만 표시하기 위한 것이므로 기본적으로 배포되지 않습니다. 소스 코드는
src/SAP/SAP_REPORTING디렉터리에서 찾을 수 있습니다.
계층 구조 평면화 구성
작업 중인 계층 구조에 따라 다음 입력 매개변수가 필요합니다.
| 계층 구조 유형 | 필수 매개변수 | 소스 필드 (ECC) | 소스 필드 (S4) |
| 재무제표 버전 (FSV) | 계정 차트 | ktopl
|
nodecls
|
| 계층 구조 이름 | versn
|
hryid
|
|
| 수익 센터 | 세트의 클래스 | setclass
|
setclass
|
| 조직 단위: 세트의 관리 영역 또는 추가 키입니다. | subclass
|
subclass
|
|
| 비용 센터 | 세트의 클래스 | setclass
|
setclass
|
| 조직 단위: 세트의 관리 영역 또는 추가 키입니다. | subclass
|
subclass
|
정확한 매개변수를 잘 모르겠다면 재무 또는 관리 SAP 컨설턴트에게 문의하세요.
매개변수가 수집되면 요구사항에 따라 각 해당 디렉터리 내에서 ## CORTEX-CUSTOMER 주석을 업데이트합니다.
| 계층 구조 유형 | 코드 위치 |
| 재무제표 버전 (FSV) | src/SAP/SAP_REPORTING/local_k9/fsv_hierarchy
|
| 수익 센터 | src/SAP/SAP_REPORTING/local_k9/profitcenter_hierarchy
|
| 비용 센터 | src/SAP/SAP_REPORTING/local_k9/costcenter_hierarchy
|
해당하는 경우 src/SAP/SAP_REPORTING 디렉터리 아래의 관련 보고 뷰 내에서 ## CORTEX-CUSTOMER 주석을 적절히 업데이트해야 합니다.
솔루션 세부정보
다음 소스 테이블은 계층 구조 평탄화에 사용됩니다.
| 계층 구조 유형 | 소스 테이블 (ECC) | 소스 테이블 (S4) |
| 재무제표 버전 (FSV) |
|
|
| 수익 센터 |
|
|
| 비용 센터 |
|
|
계층 구조 시각화
Cortex의 SAP 계층 구조 평면화 솔루션은 전체 계층 구조를 평면화합니다. SAP에서 UI에 표시하는 것과 비교할 수 있는 로드된 계층 구조의 시각적 표현을 만들려면 IsLeafNode=True 조건으로 평면화된 계층 구조를 시각화하는 뷰 중 하나를 쿼리하세요.
기존 계층 구조 평면화 도구 솔루션에서 마이그레이션
Cortex v6.0 이전의 기존 계층 구조 평면화 솔루션에서 이전하려면 다음 표와 같이 표를 대체하세요. 일부 필드 이름이 약간 수정되었으므로 필드 이름이 정확한지 확인하세요. 예를 들어 cepc_hier의 prctr은 이제 profit_centers 테이블의 profitcenter입니다.
| 계층 구조 유형 | 이 표를 다음으로 바꿉니다. | 참석: |
| 재무제표 버전 (FSV) | ska1_hier
|
fsv_glaccounts
|
| 수익 센터 | cepc_hier
|
profit_centers
|
| 비용 센터 | csks_hier
|
cost_centers
|
선택사항: SAP 재무 모듈 구성
Cortex Framework SAP Finance 모듈에는 주요 재무 통계를 제공하는 FinancialStatement, BalanceSheet, ProfitAndLoss 뷰가 포함되어 있습니다.
이러한 재무 표를 업데이트하려면 다음 단계를 따르세요.
초기 로드
- 배포 후 CDC 데이터 세트가 올바르게 채워졌는지 확인합니다(필요한 경우 CDC DAG 실행).
- 사용 중인 계층 구조 유형 (FSV, 비용 센터, 수익 센터)에 맞게 계층 구조 평면화 보기가 올바르게 구성되어 있는지 확인합니다.
financial_statement_initial_loadDAG를 실행합니다.테이블로 배포된 경우 (권장) 해당 DAG를 실행하여 다음을 순서대로 새로고침합니다.
Financial_StatementsBalanceSheetsProfitAndLoss
주기적 새로고침
- 사용 중인 계층 구조 유형 (FSV, 비용 센터, 수익 센터)에 대해 계층 구조 평면화 보기가 올바르게 구성되고 최신 상태로 새로고침되는지 확인합니다.
financial_statement_periodical_loadDAG를 예약하거나 실행합니다.테이블로 배포된 경우 (권장) 해당 DAG를 실행하여 다음을 순서대로 새로고침합니다.
Financial_StatementsBalanceSheetsProfitAndLoss
이러한 테이블의 데이터를 시각화하려면 다음 개요 뷰를 참고하세요.
- FSV 계층 구조를 사용하는 경우
ProfitAndLossOverview.sql ProfitAndLossOverview_CostCenter.sql비용 센터 계층 구조를 사용하는 경우ProfitAndLossOverview_ProfitCenter.sql(수익 센터 계층 구조를 사용하는 경우)
선택사항: 작업 종속 DAG 사용 설정
Cortex Framework는 모든 종속 테이블을 단일 DAG로 업데이트할 수 있는 대부분의 SAP SQL 테이블 (ECC 및 S/4 HANA)에 권장되는 종속 항목 설정을 선택적으로 제공합니다. 추가로 맞춤설정할 수 있습니다. 자세한 내용은 작업 종속 DAG를 참고하세요.
다음 단계
- 기타 데이터 소스 및 워크로드에 대한 자세한 내용은 데이터 소스 및 워크로드를 참고하세요.
- 프로덕션 환경에서의 배포 단계에 관한 자세한 내용은 Cortex Framework 데이터 기반 배포 필수사항을 참고하세요.