Intégration à SAP
Cette page décrit les étapes d'intégration des charges de travail opérationnelles SAP (SAP ECC et SAP S/4 HANA) dans Cortex Framework Data Foundation. Cortex Framework peut accélérer l'intégration des données SAP à BigQuery à l'aide de modèles de traitement de données prédéfinis avec des pipelines Dataflow vers BigQuery, tandis que Cloud Composer planifie et surveille ces pipelines Dataflow pour obtenir des insights à partir de vos données opérationnelles SAP.
Le fichier config.json du dépôt Cortex Framework Data Foundation configure les paramètres requis pour transférer des données depuis n'importe quelle source de données, y compris SAP. Ce fichier contient les paramètres suivants pour les charges de travail SAP opérationnelles :
"SAP": {
"deployCDC": true,
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING"
},
"SQLFlavor": "ecc",
"mandt": "100"
}
Le tableau suivant décrit la valeur de chaque paramètre opérationnel SAP :
| Paramètre | Signification | Valeur par défaut | Description |
SAP.deployCDC
|
Déployer la CDC | true
|
Générez des scripts de traitement CDC à exécuter en tant que DAG dans Cloud Composer. |
SAP.datasets.raw
|
Ensemble de données brutes de la page de destination | - | Utilisé par le processus CDC, c'est là que l'outil de réplication dépose les données provenant de SAP. Si vous utilisez des données de test, créez un ensemble de données vide. |
SAP.datasets.cdc
|
Ensemble de données traitées du CDC | - | Ensemble de données qui sert de source pour les vues de reporting et de cible pour les DAG de traitement des enregistrements. Si vous utilisez des données de test, créez un ensemble de données vide. |
SAP.datasets.reporting
|
Ensemble de données de reporting SAP | "REPORTING"
|
Nom de l'ensemble de données accessible aux utilisateurs finaux pour le reporting, où les vues et les tables destinées aux utilisateurs sont déployées. |
SAP.SQLFlavor
|
Saveur SQL pour le système source | "ecc"
|
s4 ou ecc.
Pour les données de test, conservez la valeur par défaut (ecc).
|
SAP.mandt
|
Mandant ou client | "100"
|
Mandant ou client par défaut pour SAP.
Pour les données de test, conservez la valeur par défaut (100).
|
SAP.languages
|
Filtre de langue | ["E","S"]
|
Codes de langue SAP (SPRAS) à utiliser pour les champs concernés (tels que les noms). |
SAP.currencies
|
Filtre de devise | ["USD"]
|
Codes de devise cible SAP (TCURR) pour la conversion de devises. |
Bien qu'aucune version minimale de SAP ne soit requise, les modèles ECC ont été développés sur la version SAP ECC la plus ancienne actuellement compatible. Des différences entre les champs de notre système et ceux d'autres systèmes sont à prévoir, quelle que soit la version.
Modèle de données
Cette section décrit les modèles de données SAP (ECC et S/4 HANA) à l'aide des diagrammes entité-relation (ERD).
SAP ECC

SAP S/4 HANA
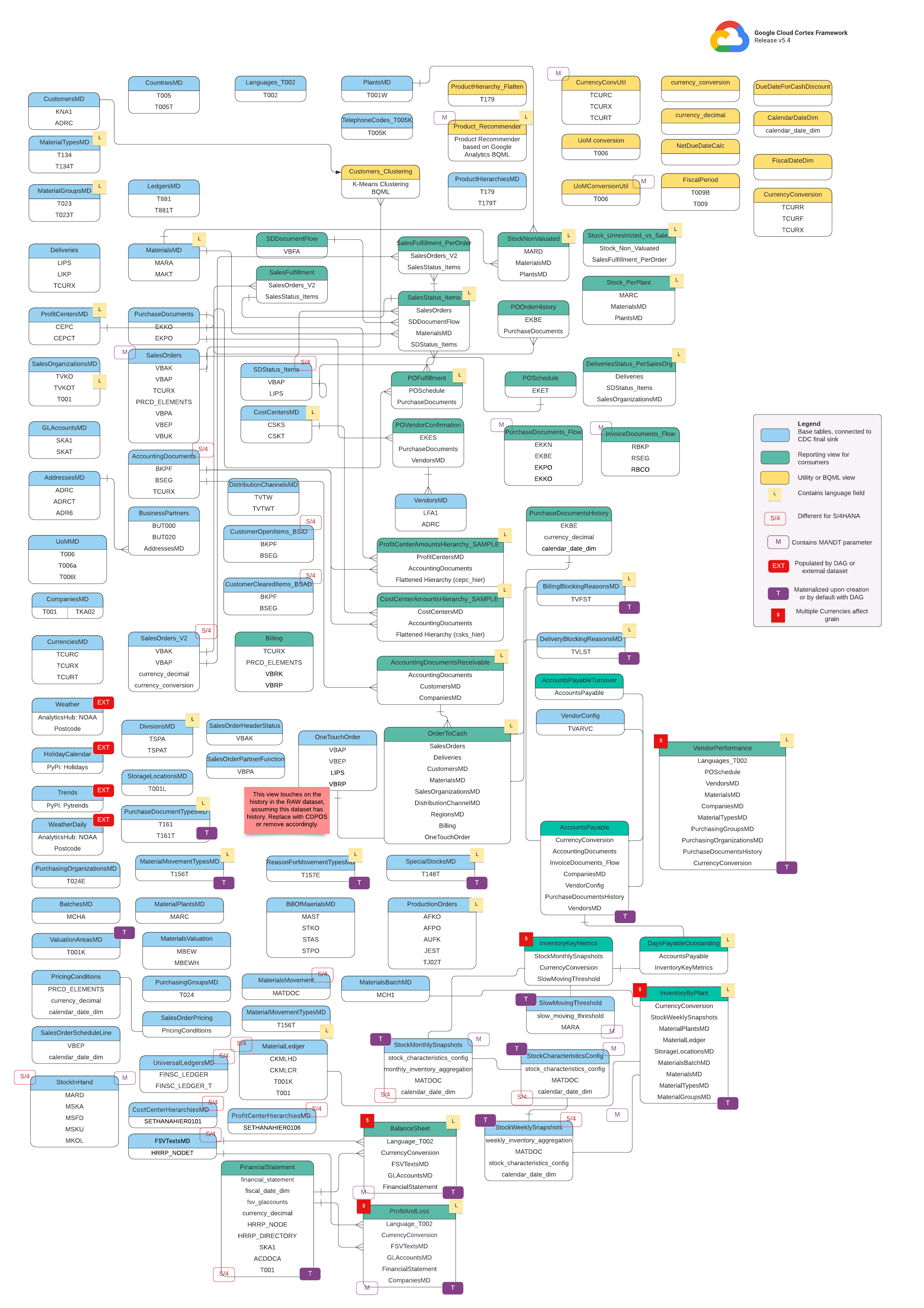
Vues de base
Il s'agit des objets bleus du diagramme ERD, qui sont des vues sur les tables CDC sans transformations, à l'exception de certains alias de noms de colonnes. Consultez les scripts dans src/SAP/SAP_REPORTING.
Vues de rapports
Il s'agit des objets verts du diagramme entité-relation. Ils contiennent les attributs dimensionnels pertinents utilisés par les tables de rapport. Consultez les scripts dans src/SAP/SAP_REPORTING.
Vue Utilitaire ou BQML
Il s'agit des objets jaunes du diagramme entité-relation. Ils contiennent les faits et les dimensions associés. Il s'agit d'un type de vue spécifique utilisé pour l'analyse et le reporting des données. Consultez les scripts sur src/SAP/SAP_REPORTING.
Tags supplémentaires
Les tags à code couleur de ce diagramme entité-relation représentent les fonctionnalités suivantes des tables de rapport :
| Tag | Color | Description |
L
|
Jaune | Ce tag fait référence à un élément ou un attribut de données qui spécifie la langue dans laquelle les données sont stockées ou affichées. |
S/4
|
Rouge | Ce tag indique que des attributs spécifiques sont propres à SAP S/4HANA (cet objet peut ne pas figurer dans SAP ECC). |
MANDT
|
Violet | Cette balise indique que des attributs spécifiques contiennent le paramètre MANDT (qui représente le client ou l'ID client) pour déterminer à quelle instance de client ou d'entreprise appartient un enregistrement de données spécifique. |
EXT
|
Rouge | Ce tag indique que des objets spécifiques sont renseignés par des DAG ou des ensembles de données externes. Cela signifie que l'entité ou la table marquée n'est pas directement stockée dans le système SAP lui-même, mais qu'elle peut être extraite et chargée dans SAP à l'aide d'un DAG ou d'un autre mécanisme. |
T
|
Violet | Cette balise indique que des attributs spécifiques seront automatiquement matérialisés à l'aide du DAG configuré. |
S
|
Rouge | Ce tag indique que les données d'une entité ou de tables sont influencées ou affectées par plusieurs devises. |
Conditions préalables à la réplication SAP
Voici les prérequis pour la réplication des données SAP avec Cortex Framework Data Foundation :
- Intégrité des données : Cortex Framework Data Foundation s'attend à ce que les tables SAP soient répliquées avec des noms de champs, des types et des structures de données identiques à ceux existant dans SAP. Tant que les tables sont répliquées avec le même format, les mêmes noms de champs et la même précision que dans la source, il n'est pas nécessaire d'utiliser un outil de réplication spécifique.
- Nommer les tables : les noms de table BigQuery doivent être créés en minuscules.
- Configuration des tables : la liste des tables utilisées par les modèles SAP est disponible et configurable dans le fichier
cdc_settings.yamlde capture des données modifiées (CDC, Change Data Capture). Si une table n'est pas listée lors du déploiement, les modèles qui en dépendent échoueront, mais les autres modèles non dépendants seront déployés avec succès. - Considérations spécifiques BigQuery Connector pour SAP :
- Mappage de table : pour en savoir plus sur l'option de conversion, consultez la documentation sur le mappage de table par défaut.
- Désactiver la compression des enregistrements : nous vous recommandons de désactiver la compression des enregistrements, car elle peut avoir un impact sur la couche CDC Cortex et sur l'ensemble de données de reporting Cortex.
- Réplication des métadonnées : si vous ne déployez pas de données de test et ne générez pas de scripts DAG CDC lors du déploiement, assurez-vous que la table
DD03Lpour les métadonnées SAP est répliquée depuis SAP dans le projet source. Cette table contient des métadonnées sur les tables, telles que la liste des clés. Elle est nécessaire au bon fonctionnement du générateur CDC et du résolveur de dépendances. Ce tableau vous permet également d'ajouter des tables non couvertes par le modèle (par exemple, des tables personnalisées ou Z) afin de générer des scripts CDC. Gérer les légères variations dans les noms de tables : si un nom de table présente de légères différences, il est possible que certaines vues ne trouvent pas les champs requis, car les systèmes SAP peuvent présenter de légères variations en raison des versions ou des modules complémentaires, ou parce que certains outils de réplication peuvent gérer les caractères spéciaux de manière légèrement différente. Nous vous recommandons d'exécuter le déploiement avec
turboMode : falsepour identifier le plus grand nombre d'échecs en une seule tentative. Voici quelques problèmes courants :- Le préfixe
_est supprimé des champs qui en comportent un (par exemple,_DATAAGING)._ - Dans BigQuery, les champs ne peuvent pas commencer par
/.
Dans ce cas, vous pouvez ajuster la vue défaillante pour sélectionner le champ tel qu'il est défini par l'outil de réplication de votre choix.
- Le préfixe
Répliquer des données brutes depuis SAP
L'objectif de la Data Foundation est d'exposer des modèles de données et d'analyse pour les rapports et les applications. Les modèles consomment les données répliquées à partir d'un système SAP à l'aide d'un outil de réplication de votre choix, comme ceux listés dans les guides d'intégration des données pour SAP.
Les données du système SAP (ECC ou S/4 HANA) sont répliquées sous forme brute.
Les données sont copiées directement de SAP vers BigQuery sans que leur structure soit modifiée. Il s'agit essentiellement d'une image miroir des tables de votre système SAP. BigQuery utilise des noms de tables en minuscules pour son modèle de données. Ainsi, même si vos tables SAP ont des noms en majuscules (comme MANDT), elles sont converties en minuscules (comme mandt) dans BigQuery.
Traitement de la capture de données modifiées (CDC)
Choisissez l'un des modes de traitement CDC suivants proposés par Cortex Framework pour que les outils de réplication chargent les enregistrements depuis SAP :
- Ajouter toujours : insérez chaque modification apportée à un enregistrement avec un code temporel et un indicateur d'opération (Insertion, Mise à jour, Suppression) afin d'identifier la dernière version.
- Mettre à jour à l'arrivée (fusionner ou insérer/mettre à jour) : créez une version mise à jour d'un enregistrement à l'arrivée dans
change data capture processed. Il effectue l'opération CDC dans BigQuery.
La base de données Cortex Framework est compatible avec les deux modes, mais elle fournit des modèles de traitement CDC pour le mode "Ajouter uniquement". Certaines fonctionnalités doivent être commentées pour être mises à jour sur la page de destination. Par exemple, OneTouchOrder.sql et toutes ses requêtes dépendantes. Cette fonctionnalité peut être remplacée par des tables telles que CDPOS.

Configurer des modèles CDC pour les outils répliquant en mode "Toujours ajouter"
Nous vous recommandons vivement de configurer cdc_settings.yaml en fonction de vos besoins.
Certaines fréquences par défaut peuvent entraîner des coûts inutiles si l'entreprise n'a pas besoin d'un tel niveau de fraîcheur des données. Si vous utilisez un outil qui s'exécute en mode "append-always", Cortex Framework Data Foundation fournit des modèles CDC pour automatiser les mises à jour et créer une dernière version de la vérité ou du jumeau numérique dans l'ensemble de données traitées par CDC.
Vous pouvez utiliser la configuration du fichier cdc_settings.yaml si vous devez générer des scripts de traitement CDC. Pour connaître les options disponibles, consultez Configurer le traitement CDC. Pour les données de test, vous pouvez laisser ce fichier par défaut.
Apportez toutes les modifications nécessaires aux modèles de DAG en fonction de votre instance Airflow ou Cloud Composer. Pour en savoir plus, consultez Collecter les paramètres Cloud Composer.
Facultatif : Si vous souhaitez ajouter et traiter des tables individuellement après le déploiement, vous pouvez modifier le fichier cdc_settings.yaml pour ne traiter que les tables dont vous avez besoin et réexécuter le module spécifié en appelant directement src/SAP_CDC/cloudbuild.cdc.yaml.
Configurer le traitement CDC
Lors du déploiement, vous pouvez choisir de fusionner les modifications en temps réel à l'aide d'une vue dans BigQuery ou en planifiant une opération de fusion dans Cloud Composer (ou toute autre instance d'Apache Airflow). Cloud Composer peut planifier les scripts pour traiter les opérations de fusion périodiquement. Les données sont mises à jour vers leur dernière version chaque fois que les opérations de fusion sont exécutées. Toutefois, des opérations de fusion plus fréquentes entraînent des coûts plus élevés. Personnalisez la fréquence planifiée en fonction des besoins de votre entreprise. Pour en savoir plus, consultez la section Planification compatible avec Apache Airflow.
L'exemple de script suivant montre un extrait du fichier de configuration :
data_to_replicate:
- base_table: adrc
load_frequency: "@hourly"
- base_table: adr6
target_table: adr6_cdc
load_frequency: "@daily"
Cet exemple de fichier de configuration effectue les opérations suivantes :
- Créez une copie de
SOURCE_PROJECT_ID.REPLICATED_DATASET.adrcdansTARGET_PROJECT_ID.DATASET_WITH_LATEST_RECORDS.adrc, si ce dernier n'existe pas. - Créez un script CDC dans le bucket spécifié.
- Créez une copie de
SOURCE_PROJECT_ID.REPLICATED_DATASET.adr6dansTARGET_PROJECT_ID.DATASET_WITH_LATEST_RECORDS.adr6_cdcsi ce dernier n'existe pas. - Créez un script CDC dans le bucket spécifié.
Si vous souhaitez créer des DAG ou des vues d'exécution pour traiter les modifications apportées aux tables qui existent dans SAP et qui ne figurent pas dans le fichier, ajoutez-les à ce fichier avant le déploiement. Cela fonctionne tant que la table DD03L est répliquée dans l'ensemble de données source et que le schéma de la table personnalisée est présent dans cette table.
Par exemple, la configuration suivante crée un script CDC pour la table personnalisée zztable_customer et une vue d'exécution pour analyser les modifications en temps réel pour une autre table personnalisée appelée zzspecial_table :
- base_table: zztable_customer
load_frequency: "@daily"
- base_table: zzspecial_table
load_frequency: "RUNTIME"
Exemple de modèle généré
Le modèle suivant génère le traitement des modifications. Les modifications, telles que le nom du champ d'horodatage ou les opérations supplémentaires, peuvent être apportées à ce stade :
MERGE `${target_table}` T
USING (
SELECT *
FROM `${base_table}`
WHERE
recordstamp > (
SELECT IF(
MAX(recordstamp) IS NOT NULL,
MAX(recordstamp),
TIMESTAMP("1940-12-25 05:30:00+00"))
FROM `${target_table}` )
) S
ON ${p_key}
WHEN MATCHED AND S.operation_flag='D' AND S.is_deleted = true THEN
DELETE
WHEN NOT MATCHED AND S.operation_flag='I' THEN
INSERT (${fields})
VALUES
(${fields})
WHEN MATCHED AND S.operation_flag='U' THEN
UPDATE SET
${update_fields}
Si votre entreprise a besoin d'insights en temps quasi réel et que l'outil de réplication le permet, l'outil de déploiement accepte l'option RUNTIME.
Cela signifie qu'aucun script CDC ne sera généré. Au lieu de cela, une vue analyserait et extrairait le dernier enregistrement disponible au moment de l'exécution pour la cohérence immédiate.
Structure des répertoires pour les DAG et les scripts CDC
La structure du bucket Cloud Storage pour les DAG SAP CDC s'attend à ce que les fichiers SQL soient générés dans /data/bq_data_replication, comme dans l'exemple suivant.
Vous pouvez modifier ce chemin avant le déploiement. Si vous ne disposez pas encore d'un environnement Cloud Composer, vous pouvez en créer un par la suite et déplacer les fichiers dans le bucket DAG.
with airflow.DAG("CDC_BigQuery_${base table}",
template_searchpath=['/home/airflow/gcs/data/bq_data_replication/'], ##example
default_args=default_dag_args,
schedule_interval="${load_frequency}") as dag:
start_task = DummyOperator(task_id="start")
copy_records = BigQueryOperator(
task_id='merge_query_records',
sql="${query_file}",
create_disposition='CREATE_IF_NEEDED',
bigquery_conn_id="sap_cdc_bq", ## example
use_legacy_sql=False)
stop_task = DummyOperator (task_id="stop")
start_task >> copy_records >> stop_task
Les scripts qui traitent les données dans Airflow ou Cloud Composer sont générés intentionnellement séparément des scripts spécifiques à Airflow. Cela vous permet de transférer ces scripts vers un autre outil de votre choix.
Champs CDC requis pour les opérations MERGE
Spécifiez les paramètres suivants pour la génération automatique des processus par lot CDC :
- Projet et ensemble de données sources : ensemble de données dans lequel les données SAP sont diffusées ou répliquées. Pour que les scripts CDC fonctionnent par défaut, les tables doivent comporter un champ d'horodatage (appelé "recordstamp") et un champ d'opération avec les valeurs suivantes, toutes définies lors de la réplication :
- I : pour "Insérer".
- U : pour "Update" (Mettre à jour).
- D : pour la suppression.
- Projet et ensemble de données cibles pour le traitement CDC : le script généré par défaut crée les tables à partir d'une copie de l'ensemble de données source si elles n'existent pas.
- Tables répliquées : tables pour lesquelles les scripts doivent être générés
- Fréquence de traitement : fréquence à laquelle les DAG doivent s'exécuter, selon la notation Cron :
- Bucket Cloud Storage cible dans lequel les fichiers de sortie CDC sont copiés.
- Nom de la connexion : nom de la connexion utilisée par Cloud Composer.
- (Facultatif) Nom de la table cible : disponible si le résultat du traitement CDC reste dans le même ensemble de données que la cible.
Optimiser les performances des tables CDC
Pour certains ensembles de données CDC, vous pouvez tirer parti du partitionnement de table et/ou du clustering de table BigQuery. Ce choix dépend des facteurs suivants :
- Taille et données de la table.
- Colonnes disponibles dans le tableau.
- Nécessité de données en temps réel avec des vues.
- Données matérialisées sous forme de tables.
Par défaut, les paramètres CDC n'appliquent pas le partitionnement ni le clustering de tables.
Vous pouvez le configurer comme vous le souhaitez. Pour créer des tables avec des partitions ou des clusters, mettez à jour le fichier cdc_settings.yaml avec les configurations appropriées. Pour en savoir plus, consultez Partition de table et Paramètres du cluster.
- Cette fonctionnalité ne s'applique que lorsqu'un ensemble de données dans
cdc_settings.yamlest configuré pour la réplication en tant que table (par exemple,load_frequency = "@daily") et non défini en tant que vue (load_frequency = "RUNTIME"). - Une table peut être à la fois partitionnée et en cluster.
Si vous utilisez un outil de réplication qui autorise les partitions dans l'ensemble de données brutes, comme BigQuery Connector pour SAP, nous vous recommandons de définir des partitions basées sur le temps dans les tables brutes. Le type de partition fonctionne mieux s'il correspond à la fréquence des DAG CDC dans la configuration cdc_settings.yaml. Pour en savoir plus, consultez Considérations liées à la conception de la modélisation des données SAP dans BigQuery.
Facultatif : Configurer le module d'inventaire SAP
Le module SAP Inventory de Cortex Framework inclut les vues InventoryKeyMetrics et InventoryByPlant, qui fournissent des insights clés sur votre inventaire.
Ces vues sont soutenues par des tables d'instantanés mensuels et hebdomadaires utilisant des DAG spécialisés. Les deux peuvent être exécutés en même temps et ne se gêneront pas mutuellement.
Pour mettre à jour l'une ou les deux tables instantanées, procédez comme suit :
Mettez à jour
SlowMovingThreshold.sqletStockCharacteristicsConfig.sqlpour définir le seuil de rotation lente et les caractéristiques du stock pour différents types de matériaux, en fonction de vos besoins.Pour le chargement initial ou l'actualisation complète, exécutez les DAG
Stock_Monthly_Snapshots_InitialetStock_Weekly_Snapshots_Initial.Pour les actualisations suivantes, planifiez ou exécutez les DAG suivants :
- Mises à jour mensuelles et hebdomadaires :
Stock_Monthly_Snapshots_Periodical_UpdateStock_Weekly_Snapshots_periodical_Update
- Mise à jour quotidienne :
Stock_Monthly_Snapshots_Daily_UpdateStock_Weekly_Snapshots_Update_Daily
- Mises à jour mensuelles et hebdomadaires :
Actualisez les vues intermédiaires
StockMonthlySnapshotsetStockWeeklySnapshots, puis les vuesInventoryKeyMetricsetInventoryByPlants, respectivement, pour afficher les données actualisées.
Facultatif : Configurer la vue "Textes de la hiérarchie des produits"
La vue "Textes de la hiérarchie des produits" aplatit les matériaux et leurs hiérarchies de produits. La table obtenue peut être utilisée pour fournir au module complémentaire Trends une liste de termes permettant de récupérer l'intérêt au fil du temps. Pour configurer cette vue, procédez comme suit :
- Ajustez les niveaux de la hiérarchie et la langue dans le fichier
prod_hierarchy_texts.sql, sous les repères pour## CORTEX-CUSTOMER. Si votre hiérarchie de produits comporte plus de niveaux, vous devrez peut-être ajouter une instruction SELECT supplémentaire semblable à l'expression de table commune
h1_h2_h3.D'autres personnalisations peuvent être disponibles en fonction des systèmes sources. Nous vous recommandons d'impliquer les utilisateurs professionnels ou les analystes dès le début du processus pour les identifier.
Facultatif : Configurer les vues d'aplatissement de la hiérarchie
À partir de la version v6.0, Cortex Framework est compatible avec l'aplatissement de la hiérarchie en tant que vues de rapport. Il s'agit d'une amélioration majeure par rapport à l'ancien outil d'aplatissement de la hiérarchie, car il aplatit désormais l'intégralité de la hiérarchie, optimise mieux S/4 en utilisant des tables spécifiques à S/4 au lieu des anciennes tables ECC, et améliore également considérablement les performances.
Résumé des vues de rapports
Vous trouverez les vues suivantes liées à l'aplatissement de la hiérarchie :
| Type de hiérarchie | Table contenant uniquement une hiérarchie aplatie | Vues pour visualiser la hiérarchie aplatie | Logique d'intégration des P&L à l'aide de cette hiérarchie |
| Version des états financiers (VEF) | fsv_glaccounts
|
FSVHierarchyFlattened
|
ProfitAndLossOverview
|
| Centre de profit | profit_centers
|
ProfitCenterHierarchyFlattened
|
ProfitAndLossOverview_ProfitCenterHierarchy
|
| Centre de coûts | cost_centers
|
CostCenterHierarchyFlattened
|
ProfitAndLossOverview_CostCenterHierarchy
|
Tenez compte des points suivants lorsque vous utilisez des vues d'aplatissement de la hiérarchie :
- Les vues de hiérarchie aplatie uniquement sont fonctionnellement équivalentes aux tables générées par l'ancienne solution d'aplatissement de la hiérarchie.
- Les vues d'ensemble ne sont pas déployées par défaut, car elles sont destinées à présenter uniquement la logique BI. Leur code source se trouve dans le répertoire
src/SAP/SAP_REPORTING.
Configurer l'aplatissement de la hiérarchie
En fonction de la hiérarchie avec laquelle vous travaillez, les paramètres d'entrée suivants sont requis :
| Type de hiérarchie | Paramètre obligatoire | Champ "Source" (ECC) | Champ source (S4) |
| Version des états financiers (VEF) | Plan comptable | ktopl
|
nodecls
|
| Nom de la hiérarchie | versn
|
hryid
|
|
| Centre de profit | Classe de l'ensemble | setclass
|
setclass
|
| Unité organisationnelle : code de contrôle ou clé supplémentaire pour l'ensemble. | subclass
|
subclass
|
|
| Centre de coûts | Classe de l'ensemble | setclass
|
setclass
|
| Unité organisationnelle : code de contrôle ou clé supplémentaire pour l'ensemble. | subclass
|
subclass
|
Si vous n'êtes pas sûr des paramètres exacts, demandez conseil à un consultant SAP spécialisé dans la finance ou le contrôle de gestion.
Une fois les paramètres collectés, mettez à jour les commentaires ## CORTEX-CUSTOMER dans chacun des répertoires correspondants, en fonction de vos besoins :
| Type de hiérarchie | Emplacement du code |
| Version des états financiers (VEF) | src/SAP/SAP_REPORTING/local_k9/fsv_hierarchy
|
| Centre de profit | src/SAP/SAP_REPORTING/local_k9/profitcenter_hierarchy
|
| Centre de coûts | src/SAP/SAP_REPORTING/local_k9/costcenter_hierarchy
|
Le cas échéant, veillez à bien mettre à jour les ## CORTEX-CUSTOMER commentaires dans les vues de rapports concernées sous le répertoire src/SAP/SAP_REPORTING.
Détails de la solution
Les tables sources suivantes sont utilisées pour l'aplatissement de la hiérarchie :
| Type de hiérarchie | Tables sources (ECC) | Tables sources (S4) |
| Version des états financiers (VEF) |
|
|
| Centre de profit |
|
|
| Centre de coûts |
|
|
Visualiser les hiérarchies
La solution d'aplatissement de la hiérarchie SAP de Cortex aplatit l'ensemble de la hiérarchie. Si vous souhaitez créer une représentation visuelle de la hiérarchie chargée comparable à celle affichée par SAP dans l'UI, interrogez l'une des vues permettant de visualiser les hiérarchies aplaties avec la condition IsLeafNode=True.
Migrer depuis l'ancienne solution d'aplatissement de la hiérarchie
Pour migrer depuis l'ancienne solution d'aplatissement de la hiérarchie avant Cortex v6.0, remplacez les tables comme indiqué dans le tableau suivant. Veillez à vérifier l'exactitude des noms de champs, car certains ont été légèrement modifiés. Par exemple, prctr dans cepc_hier est désormais profitcenter dans la table profit_centers.
| Type de hiérarchie | Remplacez ce tableau : | Avec : |
| Version des états financiers (VEF) | ska1_hier
|
fsv_glaccounts
|
| Centre de profit | cepc_hier
|
profit_centers
|
| Centre de coûts | csks_hier
|
cost_centers
|
Facultatif : Configurer le module SAP Finance
Le module Cortex Framework SAP Finance inclut les vues FinancialStatement, BalanceSheet et ProfitAndLoss qui fournissent des insights financiers clés.
Pour mettre à jour ces tables "Finance", procédez comme suit :
Pour le chargement initial
- Après le déploiement, assurez-vous que votre ensemble de données CDC est correctement renseigné (exécutez les DAG CDC si nécessaire).
- Assurez-vous que les vues d'aplatissement de la hiérarchie sont correctement configurées pour les types de hiérarchies que vous utilisez (FSV, centre de coûts et centre de profit).
Exécutez le DAG
financial_statement_initial_load.Si vous les avez déployées sous forme de tables (recommandé), actualisez les éléments suivants dans l'ordre en exécutant les DAG correspondants :
Financial_StatementsBalanceSheetsProfitAndLoss
Pour l'actualisation périodique
- Assurez-vous que les vues d'aplatissement de la hiérarchie sont correctement configurées et actualisées pour les types de hiérarchies que vous utilisez (VSE, centre de coûts et centre de profit).
Planifiez ou exécutez le DAG
financial_statement_periodical_load.Si vous les avez déployées sous forme de tables (recommandé), actualisez les éléments suivants dans l'ordre en exécutant les DAG correspondants :
Financial_StatementsBalanceSheetsProfitAndLoss
Pour visualiser les données de ces tables, consultez les vues "Vue d'ensemble" suivantes :
ProfitAndLossOverview.sqlsi vous utilisez la hiérarchie FSV.ProfitAndLossOverview_CostCenter.sqlsi vous utilisez la hiérarchie des centres de coûts.ProfitAndLossOverview_ProfitCenter.sqlsi vous utilisez la hiérarchie des centres de profit.
Facultatif : Activer les DAG dépendants des tâches
Cortex Framework fournit éventuellement des paramètres de dépendance recommandés pour la plupart des tables SQL SAP (ECC et S/4 HANA), où toutes les tables dépendantes peuvent être mises à jour par un seul DAG. Vous pouvez les personnaliser davantage. Pour en savoir plus, consultez DAG dépendant des tâches.
Étape suivante
- Pour en savoir plus sur les autres sources de données et charges de travail, consultez Sources de données et charges de travail.
- Pour en savoir plus sur les étapes de déploiement dans les environnements de production, consultez Conditions préalables au déploiement de la couche de données du framework Cortex.