Integration with Salesforce (SFDC)
This page describes the integrating steps for Salesforce (SFDC) operational workload in the Cortex Framework Data Foundation. Cortex Framework integrates data from Salesforce with Dataflow pipelines through to BigQuery, while Cloud Composer schedules and monitors these Dataflow pipelines for getting insights from your data.
Configuration file
The config.json
file in the
Cortex Framework Data Foundation repository
configures the settings required to transfer data from
any data source, including Salesforce. This file contains the following
parameters for operational Salesforce workloads:
"SFDC": {
"deployCDC": true,
"createMappingViews": true,
"createPlaceholders": true,
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING_SFDC"
}
}
The following table describes the value for each SFDC operational parameter:
| Parameter | Meaning | Default Value | Description |
SFDC.deployCDC
|
Deploy CDC | true
|
Generate CDC processing scripts to run as DAGs in Cloud Composer. See the documentation for different ingestion options for Salesforce Sales Cloud. |
SFDC.createMappingViews
|
Create mapping views | true
|
The provided DAGs to fetch new records
from the Salesforce APIs update records on landing. This value set to true
generates views in the CDC processed dataset to expose tables with
the "latest version of the truth" from the Raw dataset. If false and
SFDC.deployCDC is true, DAGs are generated
with Change Data Capture (CDC) processing based on SystemModstamp. See details
on CDC processing for Salesforce.
|
SFDC.createPlaceholders
|
Create Placeholders | true
|
Create empty placeholder tables in case they are not generated by the ingestion process to allow the downstream reporting deployment to execute without failure. |
SFDC.datasets.raw
|
Raw landing dataset | - | Used by the CDC process, this is where the replication tool lands the data from Salesforce. If using test data, create an empty dataset. |
SFDC.datasets.cdc
|
CDC Processed Dataset | - | Dataset that works as a source for the reporting views, and target for the records processed DAGs. If using test data, create an empty dataset. |
SFDC.datasets.reporting
|
Reporting Dataset SFDC | "REPORTING_SFDC"
|
Name of the dataset that is accessible to end users for reporting, where views and user-facing tables are deployed. |
SFDC.currencies
|
Filtering currencies | [ "USD" ]
|
If you aren't using test data, enter a
single currency (for example, [ "USD" ]) or multiple currencies
(for example,[ "USD", "CAD" ]) as relevant to your business.
These values are used to replace placeholders in SQL in analytics models
where available.
|
Data Model
This section describes the Salesforce (SFDC) Data Model using the Entity Relationship Diagram (ERD).
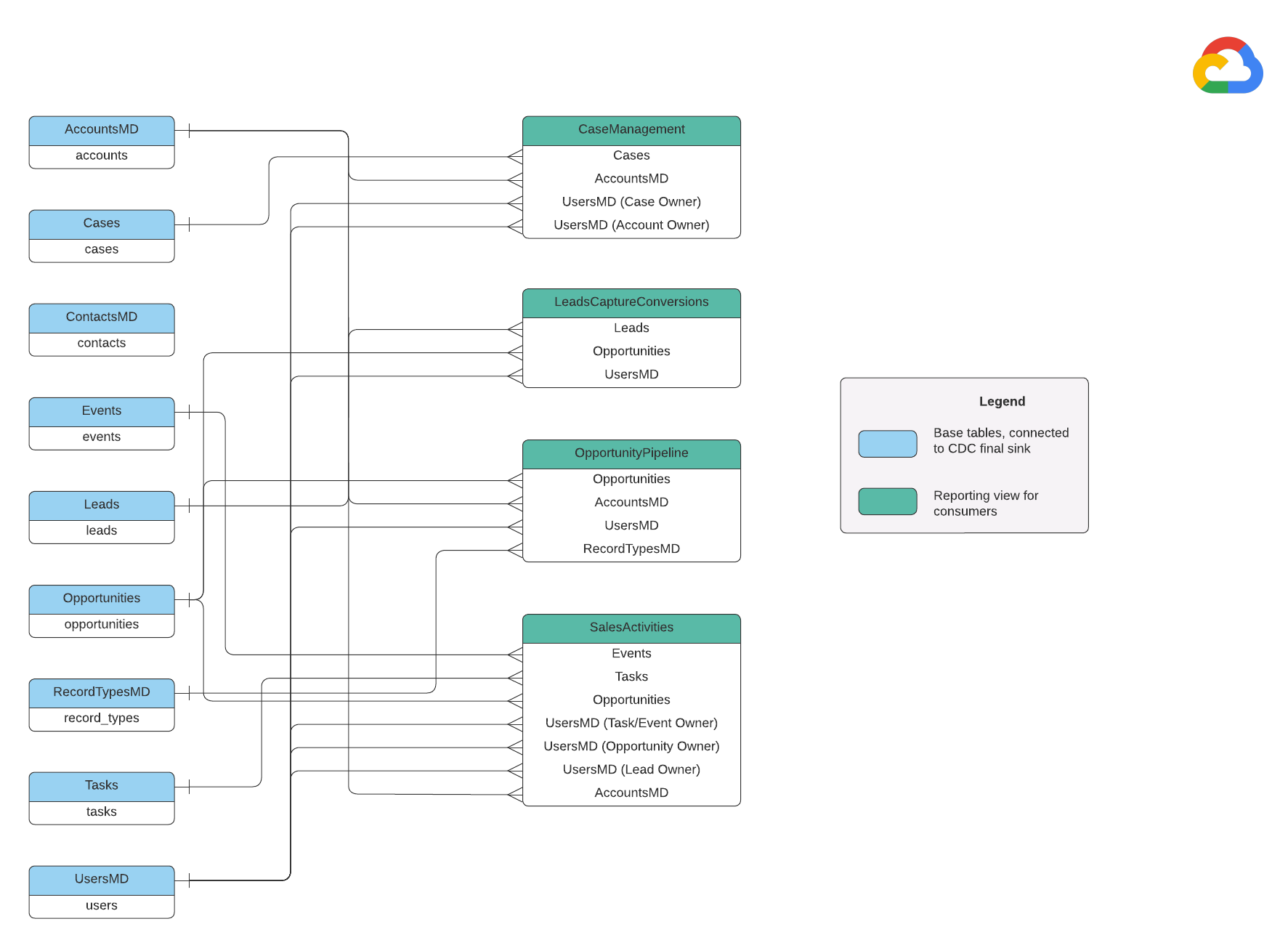
Base views
These are the blue objects in the ERD and are views on CDC tables with
no transforms other than some column name aliases. See scripts in
src/SFDC/src/reporting/ddls.
Reporting views
These are the green objects in the ERD and contain the relevant dimensional
attributes used by the reporting tables. See scripts in
src/SFDC/src/reporting/ddls.
Salesforce data requirements
This section outlines the specifics of how your Salesforce data needs to be structured for use with Cortex Framework.
- Table Structure:
- Naming: Table names use
snake_case(lowercase words separated by underscores) and are plural. For example,some_objects. - Data Types: Columns maintain the same data types as they are represented within Salesforce.
- Readability: Some field names might be slightly adjusted for better clarity in the reporting layer.
- Naming: Table names use
- Empty Tables and Deployment: Any required tables missing from the raw dataset are automatically created as empty tables during the deployment process. This ensures smooth execution of the CDC deployment step.
- CDC Requirements: The
IdandSystemModstampfields are crucial for CDC scripts to track changes in your data. They can have these exact names or different ones. The provided Raw processing scripts fetch these fields automatically from the APIs and update the target replication table.Id: This acts as a unique identifier for each record.SystemModstamp: This field stores a timestamp indicating the last time a record was modified.
- Raw Processing Scripts:The provided Raw processing scripts don't require additional (CDC) processing. This behavior is set during deployment by default.
Source tables for Currency Conversion
Salesforce lets you manage currencies in two ways:
- Basic: This is the default, where all data uses a single currency.
- Advanced: This converts between multiple currencies based on exchange rates (requires enabling Advanced Currency Management).
If you use Advanced Currency Management, Salesforce uses two special tables:
- CurrencyTypes: This table stores information about the different currencies you use (for example, USD, EUR, etc.).
- DatedConversionRates: This table holds the exchange rates between currencies over time.
Cortex Framework expects these tables to be present if you use advanced
currency management. If you don't use advanced currency management, you can
remove entries related to these tables from a configuration file
(src/SFDC/config/ingestion_settings.yaml).
This step prevents unnecessary attempts to extract data from non-existent
tables.
Loading SFDC data into BigQuery
Cortex Framework provides a replication solution based on Python scripts scheduled in Apache Airflow and Salesforce Bulk API 2.0. These Python scripts can be adapted and scheduled in your tool of choice. For more information, see SFDC extraction module.
Cortex Framework also offers three different methods to integrate your data, depending on where your data comes from and how it's managed:
- API Calls: This option is for data that can be accessed directly through an API. Cortex Framework can call the API, grab the data, and store it in a "Raw" dataset within BigQuery. If there are existing records in the dataset, Cortex Framework can update them with the new data.
- Structure Mapping Views: This method is useful if you already have your data loaded into BigQuery through another tool, but the data structure doesn't match what Cortex Framework needs. Cortex Framework uses "views" (like virtual tables) to translate the existing data structure into the format expected by Cortex Framework's reporting features.
CDC (Change Data Capture) Processing Scripts: This option is specifically designed for data that is constantly changing. CDC scripts track these changes and update the data in BigQuery accordingly. These scripts rely on two special fields in your data:
Id: unique identifier for each record.SystemModstamp: a timestamp indicating when a record was changed.
If your data doesn't have these exact names, the scripts can be adjusted to recognize them with different names. You can also add custom fields to your data schema during this process. For example, the source table with data of Account object should have original
IdandSystemModstampfields. If these fields have different names, thensrc/SFDC/src/table_schema/accounts.csvfile must be updated withIdfield's name mapped toAccountIdand whatever system modification timestamp field mapped toSystemModstamp. For more information, see SystemModStamp documentation.
If you've already loaded data through another tool (and it's constantly updated), Cortex can still use it. The CDC scripts come with mapping files that can translate your existing data structure into the format Cortex Framework needs. You can even add custom fields to your data during this process.
Configure API integration and CDC
To bring your Salesforce data into BigQuery, you can use the following ways:
- Cortex scripts for API calls: provides replication scripts for Salesforce or a data replication tool of your choice.The key is that the data you bring in should look the same as if it came from the Salesforce APIs.
- Replication tool and append always : If you are using a tool for replication, this way is for a tool that can either add new data records (_appendalways_pattern) or update existing records.
- Replication tool and add new records: If the tool does not update the records and replicates any changes as new records into a target (Raw) table, Cortex Data Foundation provides the option to create CDC processing scripts. For more information, see CDC process.

To make sure your data matches what Cortex Framework expects, you can adjust the mapping configuration to map your replication tool or existing schemata. This generates mapping views compatible with the structure expected by Cortex Framework Data Foundation.
Use the ingestion_settings.yaml file to configure
the generation of scripts to call the salesforce APIs and replicate the
data into the Raw dataset (section salesforce_to_raw_tables) and the
generation of scripts to process changes incoming into the Raw dataset and
into the CDC processed dataset (section raw_to_cdc_tables).
By default, the scripts provided to read from APIs update changes into the Raw dataset, so CDC processing scripts are not required, and mapping views to align the source schema to the expected schema are created instead.
The generation of CDC processing scripts is not executed if SFDC.createMappingViews=true
in the config.json (default behavior). If CDC scripts are required,
set SFDC.createMappingViews=false. This second step also allows for
mapping between the source schemata into the required schemata as required
by Cortex Framework Data Foundation.
The following example of a setting.yaml configuration file illustrates
the generation of mapping views when a replication tool updates the data
directly into the replicated dataset, as illustrated in option 3 (i.e.,
no CDC is required, only re-mapping of tables and field names). Since no CDC
is required, this option executes as long as the parameter
SFDC.createMappingViews in the config.json file remains true.
salesforce_to_raw_tables:
- base_table: accounts
raw_table: Accounts
api_name: Account
load_frequency: "@daily"
- base_table: cases
raw_table: cases2
api_name: Case
load_frequency: "@daily"
In this example, removing the configuration for a base table or all of them
from the sections skips the generation of DAGs of that base table or the
entire section, as illustrated for salesforce_to_raw_tables. For this
scenario, setting the parameter deployCDC : False has the same effect,
as not CDC processing scripts need to be generated.
Data mapping
You need to map incoming data fields to the format expected by Cortex Data
Foundation. For example, a field named unicornId from your source data system
should be renamed and recognized as AccountId (with a string data type) within Cortex Data
Foundation:
- Source Field:
unicornId(name used in the source system) - Cortex Field:
AccountId(name expected by Cortex) - Data Type:
String(data type expected by Cortex)
Mapping Polymorphic Fields
Cortex Framework Data Foundation supports mapping polymorphic fields, which are fields
whose name can vary but their structure remains consistent. Polymorphic field
type names (for example, Who.Type) can be replicated by
adding a [Field Name]_Type item in the respective mapping CSV files:
src/SFDC/src/table_schema/tasks.csv. For
example, if you need Who.Type field of Task object to be replicated,
add Who_Type,Who_Type,STRING line. This defines a new field named Who.Type
that maps to itself (keeps the same name) and has a string data type.
Modifying DAG Templates
You might need to adjust the DAG templates for CDC or for Raw data processing as required by your instance of Airflow or Cloud Composer. For more information, see Gathering Cloud Composer settings.
If you don't require CDC or raw data generation from API calls,
set deployCDC=false. Alternatively, you can remove the contents of the
sections in ingestion_settings.yaml. If data structures are known to be
consistent with those expected by Cortex Framework Data Foundation, you can skip
the generation of mapping views setting SFDC.createMappingViews=false.
Configuring extraction module
This section presents the steps to use the Salesforce to BigQuery extraction module provided by Data Foundation. Your requirements and flow might vary depending on your system and existing configuration. You can alternatively use other available tools.
Set up credentials and connected App
Login as an administrator to your Salesforce instance to complete the following:
- Create or identify a profile in Salesforce that meets the following requirements:
Permission for Apex REST Services and API Enabledis granted under System Permissions.View Allpermission is granted for all objects that you would like to replicate. For example, Account, and Cases. Check for restrictions or issues with your security administrator.- None permissions granted for related to user interface login, like Salesforce Anywhere in Lightning Experience, Salesforce Anywhere on Mobile, Lightning Experience User,and Lightning Login User. Check for restrictions or issues with your security administrator.
- Create or use identify existing user in Salesforce. You need to know
the user's user name, password, and security token. Consider the following:
- This should ideally be a user dedicated to execute this replication.
- The user should be assigned to the profile you have created or identified in step 1.
- You can see User Name and reset Password here.
- You can reset the security token if you don't have it and it isn't used by another process.
- Create a Connected App. It's the only communication channel to establish connection
to Salesforce from the external world with the help of profile, Salesforce
API, standard user credentials and its security token.
- Follow the instructions to enable OAuth Settings for API Integration.
- Make sure
Require Secret for Web Server FlowandRequire Secretfor Refresh Token Floware enabled in API (Enabled OAuth Settings) section. - See the documentation on how to get your consumer key (which would be later used as your Client ID). Check with your security administrator for issues or restrictions.
- Assign your Connected App to the profile created.
- Select Setup from the top right of the Salesforce home screen.
- In the Quick Find box, enter
profile, then select Profile. Search for the profile created step 1. - Open the profile.
- Click the Assigned Connected Apps link.
- Click Edit.
- Add the newly created Connected App.
- Click the Save button.
Set up Secret Manager
Configure Secret Manager to store connection details. The Salesforce-to-BigQuery module relies on Secret Manager to securely store the credentials it needs to connect to Salesforce and BigQuery. This approach avoids exposing sensitive information like passwords directly in your code or configuration files, enhancing security.
Create a secret with the following specifications. For more details instructions, see Create a secret.
- Secret Name:
airflow-connections-salesforce-conn Secret Value:
http://USERNAME:PASSWORD@https%3A%2F%2FINSTANCE_NAME.lightning.force.com?client_id=CLIENT_ID&security_token=SECRET_TOKEN`Replace the following:
USERNAMEwith your username.PASSWORDwith your password.INSTANCE_NAMEwith instance name.CLIENT_IDwith your client Id.SECRET_TOKENwith your secret token.
For more information, see how to find your instance name.
Cloud Composer libraries for replication
To execute the Python scripts in the DAGs provided by the Cortex Framework Data Foundation, you need to install some dependencies. For Airflow version 1.10, follow the Install Python dependencies for Cloud Composer 1 documentation to install the following packages, in order:
tableauserverclient==0.17
apache-airflow-backport-providers-salesforce==2021.3.3
For Airflow version 2.x, see the Install Python dependencies for Cloud Composer 2 documentation documentation to install apache-airflow-providers-salesforce~=5.2.0.
Use the following command to install each required package:
gcloud composer environments update ENVIRONMENT_NAME \
--location LOCATION \
--update-pypi-package PACKAGE_NAME EXTRAS_AND_VERSION
Replace the following:
ENVIRONMENT_NAMEwith the assigned environment name.LOCATIONwith the location.PACKAGE_NAMEwith the chosen package name.EXTRAS_AND_VERSIONwith the specifications of the extras and version.
The following command is an example of a required package installation:
gcloud composer environments update my-composer-instance \
--location us-central1 \
--update-pypi-package apache-airflow-backport-providers-salesforce>=2021.3.3
Enable Secret Manager as a backend
Enable Google Secret Manager as the security backend. This step instructs you to activate Secret Manager as the primary storage location for sensitive information like passwords and API keys used by your Cloud Composer environment. This enhances security by centralizing and managing credentials in a dedicated service. For more information, see Secret Manager.
Allow the Composer service account to access secrets
This step ensures that the service account associated with Cloud Composer
has the necessary permissions to access secrets stored within Secret Manager.
By default, Cloud Composer uses the Compute Engine service account.
The required permission is Secret Manager Secret Accessor.
This permission lets the service account to retrieve and use secrets stored
in Secret Manager.For a comprehensive guide on configuring access
controls in Secret Manager, see
access control documentation.
BigQuery connection in Airflow
Make sure to create the connection sfdc_cdc_bq according to
Gathering Cloud Composer settings. This connection is likely used by the Salesforce-to-BigQuery module to establish communication with
BigQuery.
What's next?
- For more information about other data sources and workloads, see Data sources and workloads.
- For more information about the steps for deployment in production environments, see Cortex Framework Data Foundation deployment prerequisites.