Intégration à Oracle EBS
L'intégration d'Oracle EBS (E-Business Suite) prend en charge les modèles de données de cycle de facturation avec l'ingestion de données à l'aide d'Incorta. Incorta utilise une instance hébergée ou privée pour ingérer les données Oracle dans un ensemble de données CDC BigQuery et gère le traitement CDC. À partir de là, Cortex Framework transforme et matérialise les données CDC en composants de reporting à l'aide de Cloud Composer pour orchestrer les tâches BigQuery.
Le diagramme suivant décrit comment les données Oracle EBS sont disponibles via la charge de travail opérationnelle Oracle EBS:
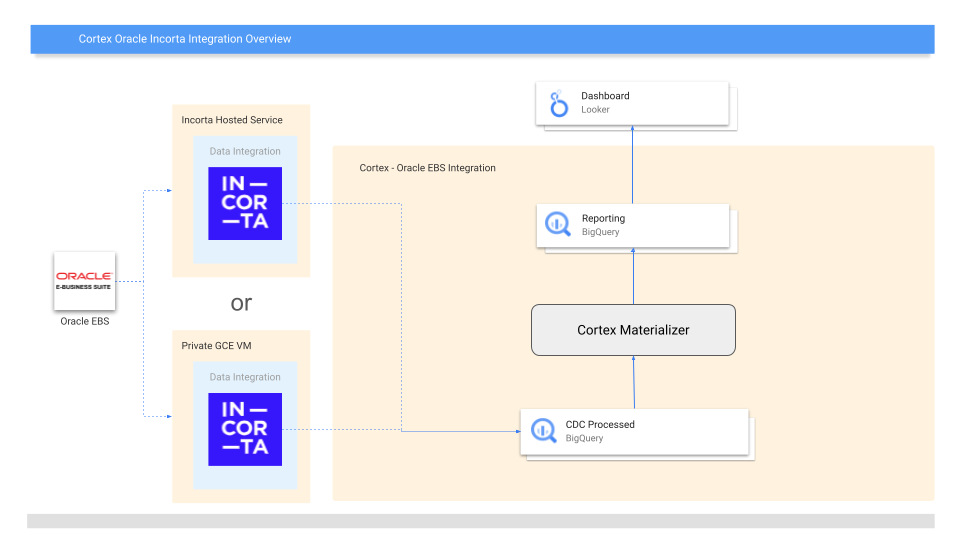
Configuration du déploiement
Le tableau suivant présente les paramètres permettant de configurer la charge de travail Oracle EBS : Le fichier config.json configure les paramètres requis pour transférer des données à partir de n'importe quelle source de données, y compris Oracle EBS. Ce fichier contient les paramètres suivants pour Oracle EBS:
| Paramètre | Signification | Valeur par défaut | Description | Champ source Oracle correspondant |
|---|---|---|---|---|
OracleEBS.itemCategorySetIDs |
Ensembles de catégories d'articles | [1100000425] |
Liste des ensembles à utiliser pour classer les éléments. | MTL_ITEM_CATEGORIES.CATEGORY_SET_ID |
OracleEBS.currencyConversionType |
Type de conversion de devise | "Corporate" |
Type de conversion de devise à utiliser dans les tableaux agrégés. | GL_DAILY_RATES.CONVERSION_TYPE |
OracleEBS.currencyConversionTargets |
Cibles de conversion de devises | ["USD"] |
Liste des devises cibles à inclure dans les tableaux cumulés. | GL_DAILY_RATES.TO_CURRENCY |
OracleEBS.languages |
Langues | ["US"] |
Liste des langues dans lesquelles présenter les traductions de champs tels que les descriptions d'articles. | FND_LANGUAGES.LANGUAGE_CODE |
OracleEBS.datasets.cdc |
Ensemble de données du CDC | - | Ensemble de données du CDC. | - |
OracleEBS.datasets.reporting |
Ensemble de données de rapport | "REPORTING_OracleEBS" |
Ensemble de données de rapport. | - |
Ingestion de données
Contactez un représentant Incorta et consultez le guide de configuration Oracle EBS pour Google Cortex pour en savoir plus sur l'ingestion de données d'Oracle vers BigQuery.
Configurations recommandées
Bien qu'Incorta prenne en charge la planification d'ingestions de données à différents intervalles, nous vous recommandons de planifier l'exécution quotidienne des tâches d'ingestion de données Incorta pour des performances et une fraîcheur des données optimales. Si votre cas d'utilisation nécessite de gérer les données supprimées, veillez à les activer en suivant les instructions de la documentation Incorta, Gérer les suppressions de sources.
Configurations de création de rapports
Cette section décrit les configurations de création de rapports nécessaires pour votre environnement.
Connexion Cloud Composer Airflow
Créez une connexion BigQuery Airflow nommée oracleebs_reporting_bq qui sera utilisée par l'opérateur BigQuery pour effectuer des transformations de rapports. Pour en savoir plus, consultez la documentation sur la gestion des connexions Airflow.
Paramètres du générateur de matériaux
Vous trouverez les paramètres de la matérialisation dans src/OracleEBS/config/reporting_settings.yaml.
Par défaut, les tables dimension, en-tête et agrégation sont matérialisées quotidiennement. Les tables de la couche de reporting sont également partitionnées par date.
Si nécessaire, vous pouvez personnaliser les partitions et le clustering. Pour en savoir plus, consultez les pages Paramètres du cluster et Partitionnement de table.
Modèle de données
Cette section décrit le modèle de données logiques de l'ordre à la trésorerie Oracle EBS. Chaque sous-section explique le diagramme des relations entre entités (ERD) Oracle EBS suivant.
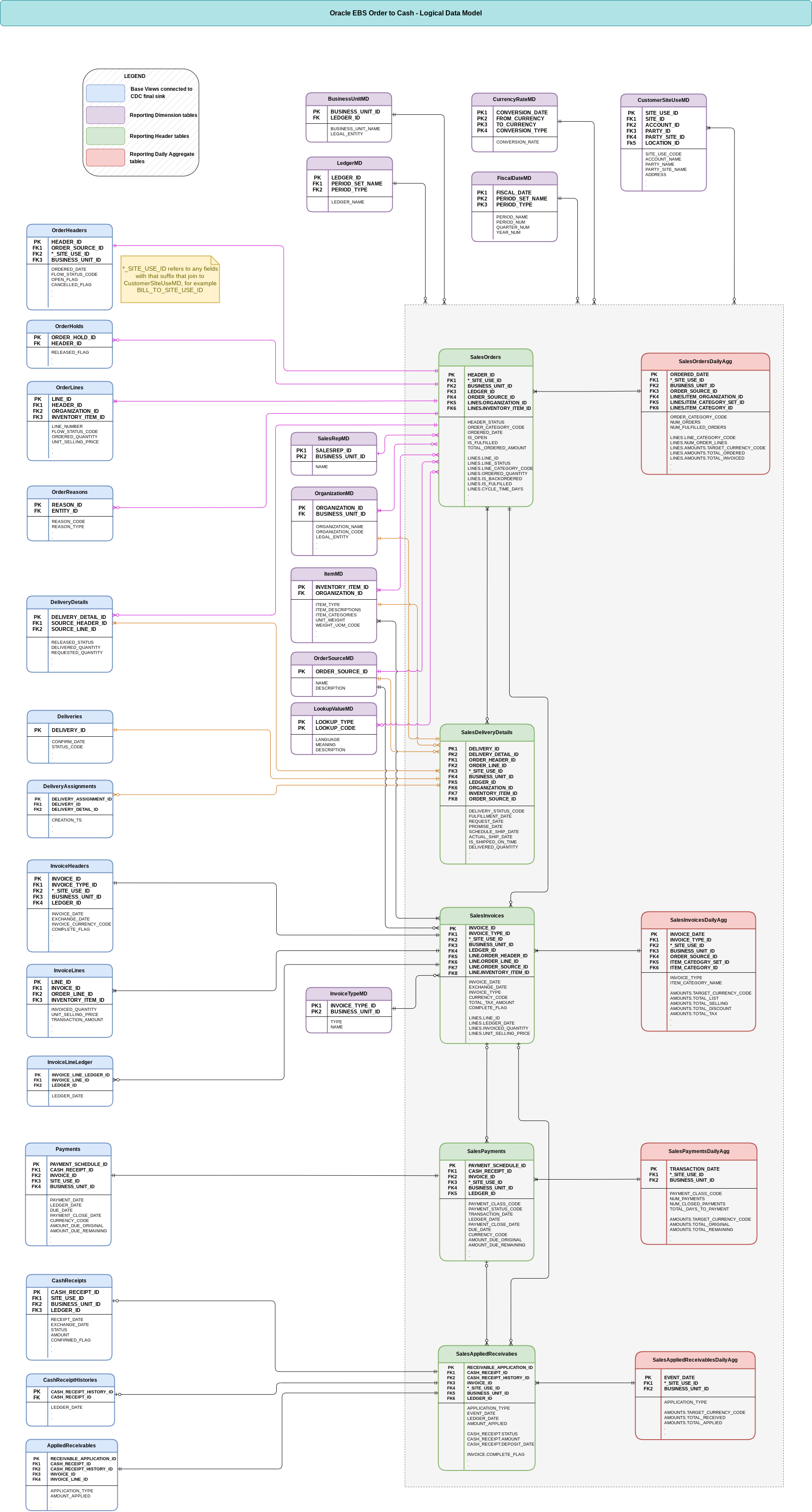
Vues de base des faits
Il s'agit des objets bleus de l'ERD. Il s'agit de vues sur les tables CDC sans autre transformation que certains alias de nom de colonne.
Tables des dimensions
Il s'agit des objets violets de l'ERD et ils contiennent les attributs dimensionnels pertinents utilisés par les tableaux de rapports. Par défaut, ces dimensions sont filtrées en fonction des valeurs des paramètres de configuration de déploiement, le cas échéant. Cette intégration utilise également la dimension du calendrier grégorien Cortex K9 pour les attributs de date, qui est déployée par défaut.
Tables d'en-tête
Il s'agit des objets verts de l'ERD. Ils contiennent les faits et les dimensions joints qui décrivent les entités commerciales telles que les commandes et les factures au niveau de l'en-tête. Les tables d'en-tête sont partitionnées en fonction d'une date d'événement principale correspondant à chaque entité, par exemple ORDERED_DATE ou INVOICE_DATE.
Lignes imbriquées et répétées
Les tables SalesOrders et SalesInvoices contiennent des champs répétés imbriqués nommés LINES. Ces champs regroupent les différentes lignes de commande et de facture sous les en-têtes associés. Pour interroger ces champs imbriqués, utilisez l'opérateur UNNEST pour aplatir les éléments en lignes, comme indiqué dans les exemples de scripts fournis (src/OracleEBS/src/reporting/ddls/samples/).
Attributs imbriqués et répétés
Certaines tables contiennent des champs répétés imbriqués supplémentaires, tels que ITEM_CATEGORIES ou ITEM_DESCRIPTIONS, dans lesquels plusieurs valeurs du même attribut peuvent s'appliquer à l'entité. Si vous démêlez ces attributs répétés, veillez à filtrer jusqu'à une seule valeur d'attribut pour éviter de sur-dénombrer les mesures.
Créances appliquées
SalesAppliedReceivables est un tableau unique en ce sens que les entités peuvent faire référence à des factures seules ou à une facture avec un reçu en espèces. Par conséquent, il existe des champs INVOICE et CASH_RECEIPT imbriqués (mais pas répétés), où le champ CASH_RECEIPT n'est renseigné que lorsque APPLICATION_TYPE = 'CASH'.
Tables agrégées
Il s'agit des objets rouges de l'ERD et de l'agrégation des tables d'en-tête aux mesures quotidiennes. Chacune de ces tables est également partitionnée par une date d'événement principale. Les tableaux agrégables ne contiennent que des mesures additives (par exemple, des totaux et des sommes) et n'incluent pas de mesures telles que des moyennes et des ratios. Cela signifie que les utilisateurs doivent dériver les mesures non additives pour s'assurer qu'elles peuvent être dérivées de manière appropriée lors de l'agrégation à un niveau plus élevé, par exemple mensuel.
Consultez des exemples de scripts tels que src/OracleEBS/src/reporting/ddls/samples/SalesOrderAggMetrics.sql.
Montants de conversion de devises
Chaque table agrégative utilise la dimension CurrencyRateMD pour créer un champ répété imbriqué de AMOUNTS contenant des mesures de devise converties dans chacune des devises cibles spécifiées dans la configuration de déploiement.
Lorsque vous utilisez ces mesures, veillez à filtrer sur une seule devise cible ou un groupe de devises cibles pour les rapports afin d'éviter de trop compter. Vous pouvez également le voir dans les exemples de scripts tels que src/OracleEBS/src/reporting/ddls/samples/SalesOrderAggMetrics.sql.
Attributs et mesures de ligne imbriqués
La table SalesOrdersDailyAgg contient un champ répété imbriqué nommé LINES pour différencier les attributs et mesures au niveau de la ligne (par exemple, ITEM_CATEGORY_NAME et AMOUNTS) des attributs et mesures au niveau de l'en-tête (par exemple, BILL_TO_CUSTOMER_NAME et NUM_ORDERS). Veillez à interroger ces grains séparément pour éviter de trop compter.
Bien que les factures comportent également une notion d'en-têtes par rapport aux lignes, la table SalesInvoicesDailyAgg ne contient que des mesures au niveau des lignes. Elle ne suit donc pas la même structure que SalesOrdersDailyAgg.
Étape suivante
- Pour en savoir plus sur les autres sources de données et charges de travail, consultez la page Sources de données et charges de travail.
- Pour en savoir plus sur les étapes de déploiement dans les environnements de production, consultez la section Conditions préalables au déploiement de Cortex Framework Data Foundation.