Integración con Salesforce Marketing Cloud
En esta página se describen las configuraciones necesarias para incorporar datos de Salesforce Marketing Cloud (SFMC) como fuente de datos de la carga de trabajo de marketing de Cortex Framework Data Foundation.
SFMC es una plataforma de automatización de marketing digital que ofrece Salesforce. Ofrece a las empresas un conjunto completo de herramientas para gestionar y automatizar diversas actividades de marketing en varios canales. Cortex Framework actúa como motor de análisis de datos y de IA que te ayuda a entender los resultados, identificar áreas de mejora y optimizar tu estrategia de marketing para obtener mejores resultados.
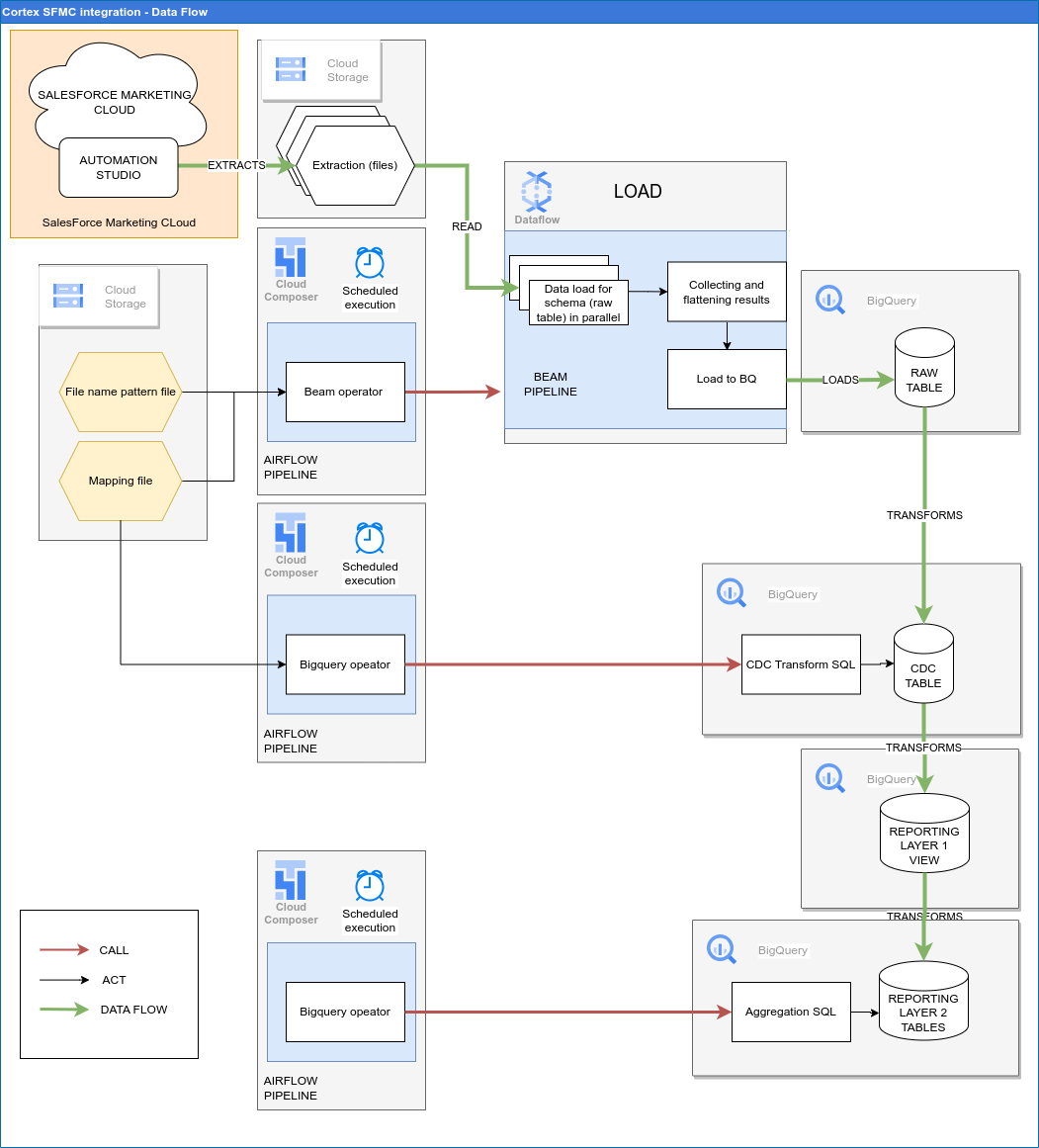
En el siguiente diagrama se describe cómo se puede acceder a los datos de SFMC a través de la carga de trabajo de marketing de Cortex Framework Data Foundation:
Archivo de configuración
El archivo config.json configura los ajustes necesarios para conectarse a fuentes de datos y transferir datos de varias cargas de trabajo. Este archivo contiene los siguientes parámetros de SFMC:
"marketing": {
"deploySFMC": true,
"SFMC": {
"deployCDC": true,
"fileTransferBucket": "",
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING_SFMC"
}
}
}
En la siguiente tabla se describe el valor de cada parámetro de marketing:
| Parámetro | Significado | Valor predeterminado | Descripción |
marketing.deploySFMC
|
Implementar SFMC | true
|
Ejecuta la implementación de la fuente de datos de SFMC. |
marketing.SFMC.deployCDC
|
Implementar secuencias de comandos de CDC para SFMC | true
|
Genera scripts de procesamiento de CDC de Salesforce Marketing Cloud (SFMC) para ejecutarlos como DAGs en Cloud Composer. |
marketing.SFMC.fileTransferBucket
|
Segmento con archivos de extracción de datos | - | Segmento en el que se almacenan los archivos de extracción de datos de Automation Studio de Salesforce Marketing Cloud (SFMC). |
marketing.SFMC.datasets.cdc
|
Conjunto de datos de CDC para SFMC | Conjunto de datos de CDC de Salesforce Marketing Cloud (SFMC). | |
marketing.SFMC.datasets.raw
|
Conjunto de datos sin procesar de SFMC | Conjunto de datos sin procesar de Salesforce Marketing Cloud (SFMC). | |
marketing.SFMC.datasets.reporting
|
Conjunto de datos de informes de SFMC | "REPORTING_SFMC"
|
Conjunto de datos de informes de Salesforce Marketing Cloud (SFMC). |
Modelo de datos
En esta sección se describe el modelo de datos de Salesforce Marketing Cloud (SFMC) mediante el diagrama de relaciones entre entidades (DER).

Vistas básicas
Son los objetos azules del diagrama ER y son vistas de tablas de CDC sin transformaciones, salvo algunos alias de nombres de columna. Consulta las secuencias de comandos en src/marketing/src/SFMC/src/reporting/ddls.
Vistas de informes
Son los objetos verdes del diagrama ER y son vistas de informes que contienen métricas agregadas. Consulta las secuencias de comandos en src/marketing/src/SFMC/src/reporting/ddls.
Extracción de datos con Automation Studio
Automation Studio de SFMC permite a los consumidores de SFMC exportar sus datos de SFMC a varios sistemas de almacenamiento. Data Foundation de Cortex Framework busca un conjunto de archivos creados con Automation Studio en un segmento de Cloud Storage. También debe usar SFMC Email Studio en este proceso.
Para configurar los procesos de extracción y exportación de datos, sigue estos pasos:
- Configura un segmento de Cloud Storage. Este segmento almacena los archivos
exportados de SFMC. Asigna al segmento el nombre
marketing.SFMC.fileTransferBucketconfig parameter. Consulta las instrucciones en la documentación de Salesforce. Crea extensiones de datos. Por cada entidad de la que quiera extraer datos, cree una extensión de datos en Email Studio. Es necesario para identificar las fuentes de datos de la base de datos interna de SFMC.
- Lista todos los campos definidos en
src/SFMC/config/table_schemade la entidad. Si necesitas personalizarlo para extraer más o menos campos, asegúrate de que la lista de campos esté alineada en estos pasos, así como en los archivos de esquema de la tabla. Por ejemplo:
Entity: unsubscribe Fields: AccountID OYBAccountID JobID ListID BatchID SubscriberID SubscriberKey EventDate IsUnique Domain- Lista todos los campos definidos en
Crea actividades de consulta de SQL. Crea una actividad de consulta de SQL para cada entidad. Esta actividad está conectada a la extensión de datos correspondiente que se creó anteriormente. Consulta la documentación de Salesforce para este paso:
- Define una consulta SQL con todos los campos pertinentes. La consulta debe seleccionar todos los campos relevantes de la entidad definida en la extensión de datos del paso anterior.
- Selecciona la extensión de datos correcta como destino.
- Seleccione Sobrescribir en Acción de datos.
- Consulta el siguiente ejemplo de consulta:
SELECT AccountID, OYBAccountID, JobID, ListID, BatchID, SubscriberID, SubscriberKey, EventDate, IsUnique, Domain FROM _UnsubscribeCrea actividades de extracción de datos. Consulte la documentación de Salesforce para obtener información sobre cómo crear una actividad de extracción de datos para cada entidad. Esta actividad obtiene los datos de la extensión de datos de Salesforce y los extrae en un archivo CSV. Para este paso:
- Usa el patrón de nomenclatura correcto. Debe coincidir con el patrón definido en Configuración.
Por ejemplo, para la entidad
Unsubscribe, el nombre de archivo puede serunsubscribe_%%Year%%_%%Month%%_%%Day%% %%Hour%%.csv. - En Tipo de extracción, selecciona
Data Extension Extract. - Selecciona las opciones Tiene encabezados de columna y Texto entre comillas.
- Usa el patrón de nomenclatura correcto. Debe coincidir con el patrón definido en Configuración.
Por ejemplo, para la entidad
Crea actividades de conversión de archivos para convertir el formato de UTF-16 a UTF-8. De forma predeterminada, Salesforce exporta archivos CSV en UTF-16. En este paso, lo convertirás al formato UTF-8. Cree otra actividad de extracción de datos para cada entidad con el fin de convertir los archivos. Para este paso:
- Usa el mismo patrón de nombre de archivo que se usó en el paso anterior de la actividad de extracción de datos.
- En Tipo de extracción, selecciona
File Convert. - Selecciona
UTF8en el menú desplegable deConvert To.
Crea actividades de transferencia de archivos. Crea una actividad de transferencia de archivos para cada entidad. Estas actividades mueven los archivos CSV extraídos de Salesforce Safehouse a los segmentos de Cloud Storage. Para este paso:
- Usa el mismo patrón de nombre de archivo que en los pasos anteriores.
- Selecciona como destino un segmento de Cloud Storage que se haya configurado anteriormente en el proceso.
Programa la ejecución. Una vez que hayas completado todas las actividades, configura programaciones automatizadas para ejecutarlas.
Actualización y latencia de los datos
Por lo general, la actualización de los datos de las fuentes de datos de Cortex Framework está limitada por lo que permite la conexión ascendente, así como por la frecuencia de ejecución de tu DAG. Ajusta la frecuencia de ejecución de tu DAG para que se ajuste a la frecuencia de los elementos anteriores, las restricciones de recursos y las necesidades de tu empresa.
Con SFMC Automation Studio, el retraso de actualización de los datos depende del retraso de programación cuando se configura la exportación de datos.
Permisos de conexiones de Cloud Composer
Crea las siguientes conexiones en Cloud Composer. Para obtener más información, consulta la documentación sobre cómo gestionar conexiones de Airflow.
| Nombre de la conexión | Purpose |
sfmc_raw_dataflow
|
Para Archivos extraídos de SFMC > Conjunto de datos BigQueryRaw. |
sfmc_cdc_bq
|
En Conjunto de datos sin procesar > Transferencia de conjunto de datos de CDC. |
sfmc_reporting_bq
|
Para el conjunto de datos de CDC > Transferencia del conjunto de datos de informes. |
Permisos de la cuenta de servicio de Cloud Composer
La cuenta de servicio que se usa en Cloud Composer (tal como se configura en la conexión sfmc_raw_dataflow) necesita permisos relacionados con Dataflow.
Consulta las instrucciones en la documentación de Dataflow.
Configuración de ingestión
Controla las canalizaciones de datos Source to Raw y Raw to CDC a través de los ajustes
del archivo src/SFMC/config/ingestion_settings.yaml .
En esta sección se describen los parámetros de cada canalización de datos.
De las fuentes a las tablas sin procesar
Esta sección contiene entradas que controlan cómo se usan los archivos extraídos de Automation Studio. Cada entrada se corresponde con una entidad de SFMC. A partir de esta configuración, Cortex Framework crea DAGs de Airflow que ejecutan flujos de procesamiento de Dataflow para cargar datos de archivos exportados en tablas de BigQuery del conjunto de datos en bruto.
El directorio src/SFMC/config/table_schema contiene un archivo de esquema para cada entidad que se extrae de SFMC. En cada archivo se explica cómo leer los archivos CSV extraídos de Automaton Studio para cargarlos correctamente en el conjunto de datos sin procesar de BigQuery.
Cada archivo de esquema contiene tres columnas:
SourceField: nombre del campo del archivo CSV.TargetField: nombre de la columna de la tabla sin procesar de esta entidad.DataType: tipo de datos de cada campo de la tabla sin procesar.
Los siguientes parámetros controlan los ajustes de Source to Raw
de cada entrada:
| Parámetro | Descripción |
base_table
|
Nombre de la tabla sin procesar en la que se cargan los datos extraídos de una entidad de SFMC. |
load_frequency
|
La frecuencia con la que se ejecuta un DAG de esta entidad para cargar datos de los archivos extraídos. Para obtener más información sobre los posibles valores, consulta la documentación de Airflow. |
file_pattern
|
Patrón del archivo de esta tabla que se exporta de Automation Studio al segmento de Cloud Storage. Cambie este valor solo si ha elegido un nombre diferente a los sugeridos para los archivos extraídos. |
partition_details
|
Cómo se particiona la tabla sin procesar para mejorar el rendimiento. Para obtener más información, consulta Partición de tabla. |
cluster_details
|
Opcional: Si quieres que la tabla sin procesar se agrupe para mejorar el rendimiento. Para obtener más información, consulta Configuración del clúster. |
Tablas de datos sin procesar a tablas de CDC
En esta sección se describe qué entradas controlan cómo se mueven los datos de las tablas sin procesar a las tablas de CDC. Cada entrada se corresponde con una tabla sin procesar.
Los siguientes parámetros controlan los ajustes de Raw to CDC de cada entrada:
| Parámetro | Descripción |
base_table
|
Tabla del conjunto de datos de CDC en la que se almacenan los datos sin procesar después de la transformación de CDC. |
load_frequency
|
Con qué frecuencia se ejecuta un DAG para esta entidad para rellenar la tabla de CDC. Para obtener más información sobre los valores posibles, consulta la documentación de Airflow. |
raw_table
|
Tabla de origen del conjunto de datos sin procesar. |
row_identifiers
|
Columnas (separadas por comas) que forman un registro único para esta tabla. |
partition_details
|
Cómo se particiona la tabla de CDC para mejorar el rendimiento. Para obtener más información, consulta Partición de tabla. |
cluster_details
|
Opcional: si quieres que esta tabla se agrupe por motivos de rendimiento. Para obtener más información, consulta Configuración del clúster. |
Configuración de informes
Puede configurar y controlar cómo genera datos Cortex Framework para la capa de informes final de SFMC mediante el archivo de configuración de informes (src/SFMC/config/reporting_settings.yaml). Este archivo controla cómo se generan los objetos de BigQuery de la capa de informes (tablas, vistas,funciones o procedimientos almacenados).
Para obtener más información, consulte Personalizar el archivo de configuración de informes.
Siguientes pasos
- Para obtener más información sobre otras fuentes de datos y cargas de trabajo, consulta el artículo Fuentes de datos y cargas de trabajo.
- Para obtener más información sobre los pasos para la implementación en entornos de producción, consulta los requisitos previos para la implementación de Data Foundation de Cortex Framework.