Integración con Meta
En esta página se describen las configuraciones necesarias para importar datos de Meta (anuncios de Facebook e Instagram) como fuente de datos de la carga de trabajo de marketing de la base de datos de Cortex Framework.
Meta es una empresa tecnológica propietaria de varias plataformas online populares. Cortex Framework integra datos de anuncios de Instagram y Facebook para analizarlos, combinarlos con otras fuentes de datos y usar la IA para obtener estadísticas más detalladas y optimizar tu estrategia de marketing.
En el siguiente diagrama se describe cómo se puede acceder a los datos de marketing de Meta a través de la carga de trabajo de marketing de Cortex Framework Data Foundation:
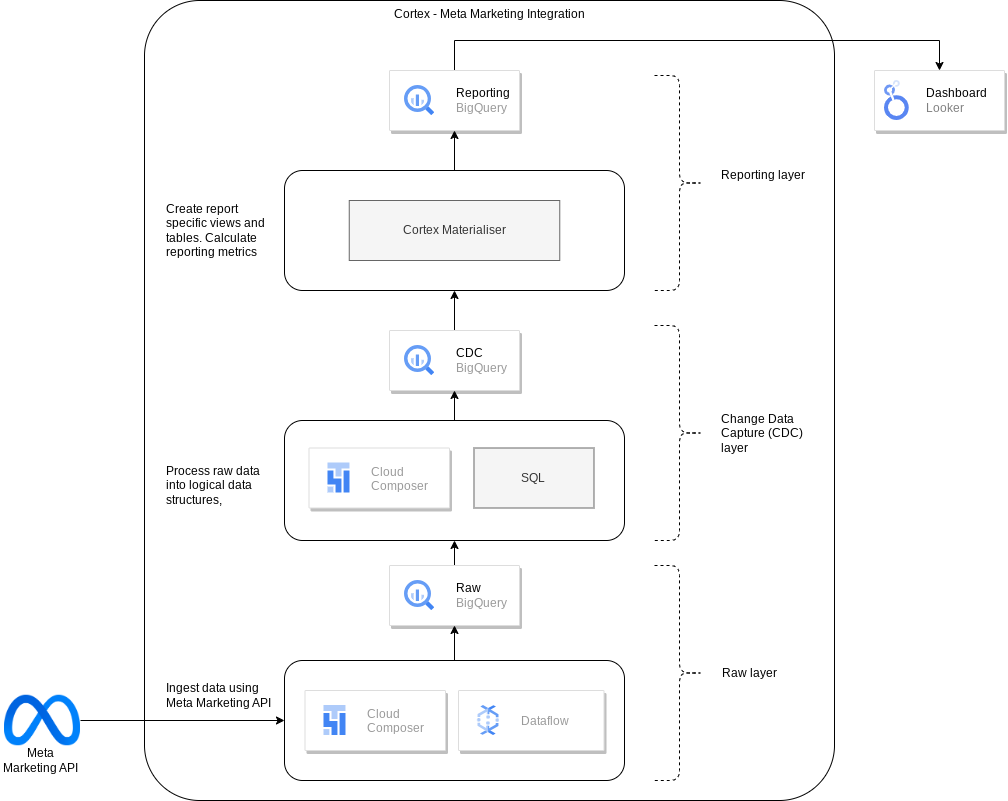
Archivo de configuración
El archivo config.json configura los ajustes necesarios para conectarse a fuentes de datos y transferir datos de varias cargas de trabajo. Este archivo contiene los siguientes parámetros de Meta:
"marketing": {
"deployMeta": true,
"Meta": {
"deployCDC": true,
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING_Meta"
}
}
}
En la siguiente tabla se describe el valor de cada parámetro de marketing:
| Parámetro | Significado | Valor predeterminado | Descripción |
marketing.deployMeta
|
Desplegar metadatos | true
|
Ejecuta la implementación de la fuente de datos de Meta. |
marketing.Meta.deployCDC
|
Implementar secuencias de comandos de CDC para Meta | true
|
Genera secuencias de comandos de procesamiento de CDC de Meta para ejecutarlas como DAGs en Cloud Composer. |
marketing.Meta.datasets.cdc
|
Conjunto de datos de CDC de Meta | Conjunto de datos de CDC para Meta. | |
marketing.Meta.datasets.raw
|
Conjunto de datos sin procesar de Meta | Conjunto de datos sin procesar de Meta. | |
marketing.Meta.datasets.reporting
|
Conjunto de datos de informes de Meta | "REPORTING_Meta"
|
Conjunto de datos de informes de Meta. |
Modelo de datos
En esta sección se describe el modelo de datos de Meta mediante el diagrama de relaciones entre entidades (DRE).
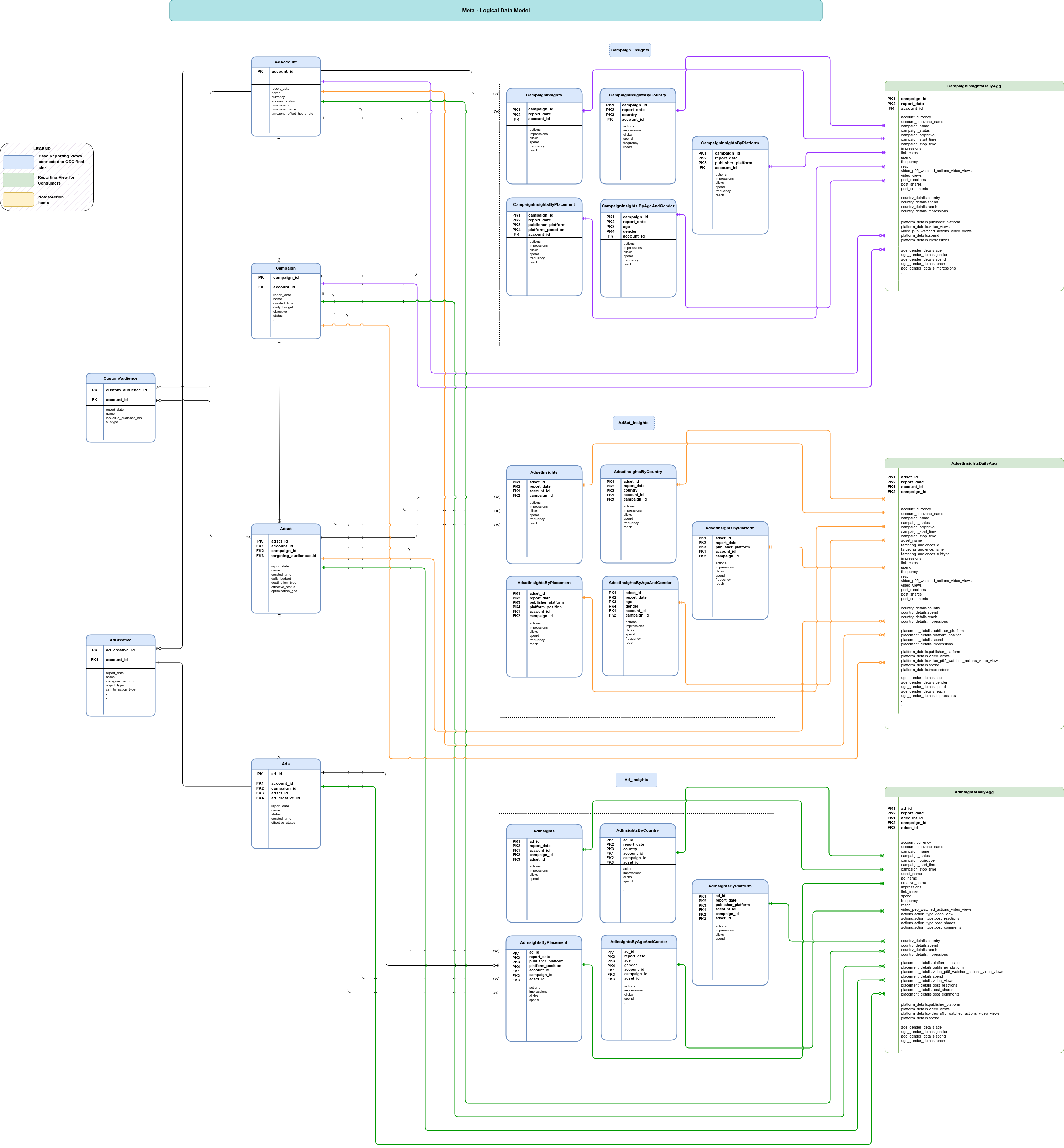
Vistas básicas
Son los objetos azules del diagrama ER y son vistas de las tablas de CDC con transformaciones mínimas para descomprimir estructuras de datos complejas. Consulta las secuencias de comandos en src/marketing/src/Meta/src/reporting/ddls.
Vistas de informes
Son los objetos verdes del diagrama ER y son vistas de informes que contienen métricas agregadas. Consulta las secuencias de comandos en src/marketing/src/Meta/src/reporting/ddls.
Conexión a la API
Las plantillas de ingestión de Cortex Framework para Meta usan la API Marketing de Meta para obtener atributos y métricas de informes. Las plantillas actuales usan la versión 21.0.
Meta impone un límite de frecuencia dinámico al consultar la API Marketing. Cuando se alcanza el límite de frecuencia, es posible que los DAGs de ingestión de Source to Raw no se completen correctamente. En estos casos, puedes ver los mensajes de error pertinentes en el registro y la siguiente ejecución de los DAGs cargará de forma retroactiva los datos que falten.
La API Marketing de Meta tiene dos niveles de acceso: básico y estándar. El nivel Estándar ofrece un límite mucho más alto y se recomienda si tiene previsto usar la ingestión de datos de origen a sin procesar de forma intensiva. Para obtener más información sobre estos límites y cómo conseguir un nivel de acceso superior, consulta la documentación de Meta.
Si tienes acceso al nivel Estándar, puedes reducir el valor del ajuste next_request_delay_sec en src/Meta/src/raw/pipelines/config.ini para que los tiempos de carga sean más rápidos.
Acceso a la API y token de acceso
Para transferir datos de Meta a Cortex Framework, debes seguir los pasos que se indican a continuación en Meta Business Manager y en la consola para desarrolladores.
- Identifica una aplicación que quieras usar. Puedes crear una aplicación
que esté conectada a la cuenta de empresa. Asegúrate de que tu aplicación sea de tipo
Business. - Configura los permisos de la aplicación. Debes tener asignado el rol de administrador en la aplicación para poder crear tokens con ella. Consulta la documentación sobre roles de aplicación. Asegúrate de asignar los recursos (cuentas) pertinentes a tu aplicación.
Crea un token de acceso. Los tokens de acceso son necesarios para acceder a la API Marketing de Meta y siempre están asociados a una aplicación y a un usuario. Puedes crear el token con un usuario del sistema o con tu propio inicio de sesión.
- Crea un usuario administrador del sistema.
- Genera un token. Anota los tokens en cuanto se generen, ya que no podrás recuperarlos una vez que salgas de la página.
- Concede los permisos
ads_readybusiness_managementa tu token para acceder a los objetos admitidos.
Sigue la documentación de Cloud Composer para habilitar Secret Manager en Cloud Composer. A continuación, crea un secreto llamado
cortex_meta_access_tokeny almacena el token que has generado en el paso anterior como contenido.
Actualización y latencia de los datos
Por lo general, la actualización de los datos de las fuentes de datos de Cortex Framework está limitada por lo que permite la conexión ascendente, así como por la frecuencia de ejecución de tu DAG. Ajusta la frecuencia de ejecución de tu DAG para que se ajuste a la frecuencia de los elementos anteriores, las restricciones de recursos y las necesidades de tu empresa.
Con la API Marketing de Meta, la mayoría de los datos (excepto las conversiones) están disponibles casi en tiempo real, aunque pueden ajustarse hasta 28 días después del evento.
Permisos de conexiones de Cloud Composer
Crea las siguientes conexiones en Cloud Composer. Para obtener más información, consulta la documentación sobre cómo gestionar conexiones de Airflow.
| Nombre de la conexión | Purpose |
meta_raw_dataflow
|
Para la API Meta Marketing > Conjunto de datos sin procesar de BigQuery |
meta_cdc_bq
|
Conjunto de datos sin procesar > Transferencia de conjunto de datos de CDC |
meta_reporting_bq
|
Conjunto de datos de CDC > Transferencia de conjuntos de datos de informes |
Permisos de la cuenta de servicio de Cloud Composer
Concede permisos de Dataflow a la cuenta de servicio utilizada en Cloud Composer (tal como se configura en la conexión meta_raw_dataflow).
Consulta las instrucciones en la documentación de Dataflow. La cuenta de servicio también requiere el permiso Secret Manager Secret Accessor. Consulta los detalles en la documentación sobre control de acceso.
Parámetros de solicitud
El directorio src/Meta/config/request_parameters contiene un archivo de especificación de solicitudes de API para cada entidad que se extrae de la API Marketing de Meta. Cada archivo de solicitud contiene una lista de campos que se deben obtener de la API Marketing de Meta. Cada campo se indica en una fila. Consulte más información en la referencia de la API Marketing de Meta.
Configuración de ingestión
Controla las canalizaciones de datos Source to Raw y Raw to CDC mediante los ajustes del archivo src/Meta/config/ingestion_settings.yaml.
En esta sección se describen los parámetros de cada canalización de datos.
De las fuentes a las tablas sin procesar
Esta sección contiene entradas que controlan qué entidades obtienen las APIs y cómo. Cada entrada se corresponde con una entidad de la API Marketing de Meta. Según esta configuración, Cortex Framework crea DAGs de Airflow que ejecutan flujos de procesamiento de Dataflow para obtener datos mediante las APIs de Meta Marketing.
El archivo src/Meta/src/raw/pipelines/config.ini controla algunos comportamientos del DAG de Cloud Composer y cómo se consumen las APIs de marketing de Meta.
Encuentra descripciones de cada parámetro en el archivo.
Los siguientes parámetros controlan los ajustes de Source to Raw
de cada entrada:
| Parámetro | Descripción |
base_table
|
Tabla del conjunto de datos sin procesar en la que se almacenan los datos obtenidos (por ejemplo, customer).
|
load_frequency
|
Con qué frecuencia se ejecuta un DAG para obtener datos de Meta. Para obtener más información sobre los valores posibles, consulta la documentación de Airflow. |
object_endpoint
|
Ruta del endpoint de la API (por ejemplo, campaigns para el endpoint /{account_id}/campaigns).
|
entity_type
|
Tipo de tabla (debe ser uno de los siguientes:
fact, dimension o addaccount).
|
object_id_column
|
Columnas (separadas por comas) que
forman un registro único para esta tabla. Solo es obligatorio cuando entity_type es fact.
|
breakdowns
|
Opcional: columnas de desglose (separadas por comas) para los endpoints de estadísticas. Solo se aplica cuando entity_type es fact.
|
action_breakdowns
|
Opcional: columnas de desglose de acciones
(separadas por comas) para los endpoints de estadísticas. Solo se aplica cuando entity_type es fact.
|
partition_details
|
Opcional: si quiere que esta tabla se particione por motivos de rendimiento. Para obtener más información, consulta Partición de tabla. |
cluster_details
|
Opcional: si quieres que esta tabla se agrupe por motivos de rendimiento. Para obtener más información, consulta Configuración del clúster. |
Tablas de datos sin procesar a tablas de CDC
En esta sección se describen las entradas que controlan cómo se mueven los datos de las tablas sin procesar a las tablas de CDC. Cada entrada se corresponde con una tabla sin procesar (que, a su vez, se corresponde con una entidad de la API Meta, como se ha mencionado).
Los siguientes parámetros controlan los ajustes de Raw to CDC de cada entrada:
| Parámetro | Descripción |
base_table
|
Tabla en la que se han replicado los datos sin procesar. Una tabla con el mismo nombre en el conjunto de datos de CDC almacena los datos sin procesar después de la transformación de CDC (por ejemplo, campaign_insights).
|
row_identifiers
|
Columnas (separadas por comas) que forman un registro único para esta tabla. |
load_frequency
|
Con qué frecuencia se ejecuta un DAG para esta entidad con el fin de rellenar la tabla de CDC. Para obtener más información sobre los posibles valores, consulta la documentación de Airflow. |
partition_details
|
Opcional: si quiere que esta tabla se particione por motivos de rendimiento. Para obtener más información, consulta Partición de tablas. |
cluster_details
|
Opcional: si quiere que esta tabla se agrupe por motivos de rendimiento. Para obtener más información, consulta Configuración del clúster. |
Esquema de tabla de CDC
En Meta, todos los campos se almacenan en formato de cadena en la capa sin procesar. En la capa de CDC, los tipos primitivos se convierten en tipos de datos empresariales relevantes y todos los tipos complejos se almacenan en formato JSON de BigQuery.
Para habilitar esta conversión, el directorio src/Meta/config/table_schema
contiene un archivo de esquema para cada entidad especificada en la sección raw_to_cdc_tables
, que explica cómo traducir correctamente cada tabla sin procesar de BigQuery en una tabla de CDC.
Cada archivo de esquema contiene tres columnas:
SourceField: nombre del campo de la tabla sin procesar de esta entidad.TargetField: nombre de la columna de la tabla de CDC de esta entidad.DataType: tipo de datos de cada campo de la tabla de CDC.
Configuración de informes
Puede configurar y controlar cómo genera Cortex los datos de la capa de informes final de Meta mediante el archivo de configuración de informes (src/Meta/config/reporting_settings.yaml). Este archivo controla cómo se generan los objetos de BigQuery de la capa de informes (tablas, vistas, funciones o procedimientos almacenados).
Para obtener más información, consulte Personalizar el archivo de configuración de informes.
Siguientes pasos
- Para obtener más información sobre otras fuentes de datos y cargas de trabajo, consulta el artículo Fuentes de datos y cargas de trabajo.
- Para obtener más información sobre los pasos para la implementación en entornos de producción, consulta los requisitos previos para la implementación de Data Foundation de Cortex Framework.