Integration with Meta
This page describes the required configurations to bring data from Meta (Facebook and Instagram Ads) as a data source of the marketing workload of Cortex Framework Data Foundation.
Meta is a tech company that owns several popular online platforms. Cortex Framework integrates data Ads from Instagram and Facebook to analyze it, combine it with other data sources, and use AI to gain deeper insights and optimize your marketing strategy.
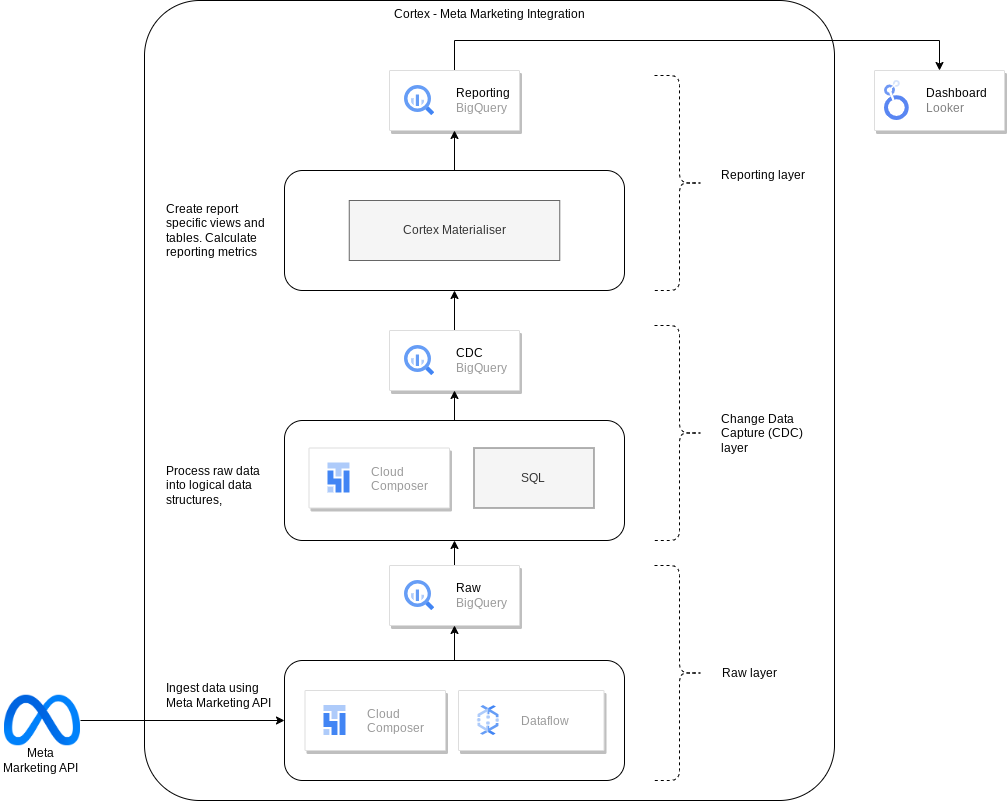
The following diagram describes how Meta marketing data is available through the marketing workload of Cortex Framework Data Foundation:
Configuration file
The config.json file configures the settings required to connect to data sources for transferring
data from various workloads. This file contains the following parameters for Meta:
"marketing": {
"deployMeta": true,
"Meta": {
"deployCDC": true,
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING_Meta"
}
}
}
The following table describes the value for each marketing parameter:
| Parameter | Meaning | Default Value | Description |
marketing.deployMeta
|
Deploy Meta | true
|
Execute the deployment for Meta's data source. |
marketing.Meta.deployCDC
|
Deploy CDC scripts for Meta | true
|
Generate Meta CDC processing scripts to run as DAGs in Cloud Composer. |
marketing.Meta.datasets.cdc
|
CDC dataset for Meta | CDC dataset for Meta. | |
marketing.Meta.datasets.raw
|
Raw dataset for Meta | Raw dataset for Meta. | |
marketing.Meta.datasets.reporting
|
Reporting dataset for Meta | "REPORTING_Meta"
|
Reporting dataset for Meta. |
Data Model
This section describes the Data Model of Meta using the Entity Relationship Diagram (ERD).

Base views
These are the blue objects in the ERD and are views on CDC tables with
minimal transformations to unpack complex data structures. See scripts in
src/marketing/src/Meta/src/reporting/ddls.
Reporting views
These are the green objects in the ERD and are reporting views that contain
aggregate metrics. See scripts in
src/marketing/src/Meta/src/reporting/ddls.
API connection
The ingestion templates in Cortex Framework for Meta use the Meta Marketing API to retrieve reporting attributes and metrics. The current templates use version v21.0.
Meta imposes a dynamic rate limit when querying the Marketing API. When the rate limit is reached, Source to Raw ingestion DAGs might not complete successfully. In such cases, you can see relevant error messages in the log, and the next execution of the DAGs would retroactively load any missing data.
Meta Marketing API has two tiers of access, Basic and Standard. Standard tier offers a much higher limit, and is recommended if you plan to use the Source to Raw ingestion extensively. For more details on these limits and how to attain a higher access tier, see Meta's documentation.
If you have Standard tier access, you can lower the value of
next_request_delay_sec setting in src/Meta/src/raw/pipelines/config.ini
for faster loading times.
API access and access token
The following steps are required in Meta Business Manager and Developer Console to successfully bring data from Meta into the Cortex Framework.
- Identify an App to use. You can create a new App
that is connected to the Business account. Make sure your app is
Businesstype. - Set up App permissions. You must be assigned to the app as an Administrator before you can create tokens with it. See App roles documentation. Make sure you assign relevant assets (accounts) to your app.
Create an access token. Access tokens are required to access Meta Marketing API, and they are always associated with an app and a user. You can either create the token with a system user, or with your own login.
- Create an Admin System User.
- Generate a token. Make sure to note down your token as soon as they are generated, as they are not be retrievable again once you leave the page.
- Grant the
ads_readandbusiness_managementpermissions to your token, to access the supported objects.
Follow Cloud Composer documentation to enable Secret Manager in Cloud Composer. Then, create a secret named
cortex_meta_access_token, and store the token you've generated in the previous step as content.
Data Freshness and Delay
As a general rule, data freshness for Cortex Framework data sources is limited by what upstream connection allows for, as well as the frequency of your DAG execution. Adjust your DAG execution frequency to align with upstream frequency, resource constraints, and your business needs.
With Meta Marketing API, most data (excluding conversions) is available near real time, although they may be adjusted up to 28 days after event.
Cloud Composer connections permissions
Create the following connections in Cloud Composer. See more details in the Manage Airflow connections documentation.
| Connection Name | Purpose |
meta_raw_dataflow
|
For Meta Marketing API > BigQuery Raw Dataset |
meta_cdc_bq
|
For Raw dataset > CDC dataset transfer |
meta_reporting_bq
|
For CDC dataset > Reporting dataset transfer |
Cloud Composer service account permissions
Grant Dataflow permissions to the service account used in
Cloud Composer (as configured in the meta_raw_dataflow connection).
See instructions in Dataflow documentation. The service account also requires
Secret Manager Secret Accessor permission. See details
in the access control documentation.
Request parameters
Directory src/Meta/config/request_parameters contains an API request specification file for each entity that is extracted from Meta Marketing API. Each request file contains a list of fields to fetch from Meta Marketing API, one field per row. See more information in Meta Marketing API Reference.
Ingestion settings
Control Source to Raw and Raw to CDC data pipelines through the
settings in the file src/Meta/config/ingestion_settings.yaml.
This section describes the parameters of each data pipeline.
Source to raw tables
This section has entries that control which entities are fetched by APIs and how. Each entry corresponds with one Meta Marketing API entity. Based on this configuration, Cortex Framework creates Airflow DAGs that run Dataflow pipelines to fetch data using Meta Marketing APIs.
File src/Meta/src/raw/pipelines/config.ini controls some behavior
of the Cloud Composer DAG, and how Meta Marketing APIs are consumed.
Find descriptions for each parameter in the file.
The following parameters control the settings for Source to Raw
for each entry:
| Parameter | Description |
base_table
|
Table in Raw dataset where the fetched
data is stored (for example, customer).
|
load_frequency
|
How frequently a DAG for this runs to fetch data from Meta. For more information about possible values, see Airflow documentation. |
object_endpoint
|
API endpoint path (for example,
campaigns for /{account_id}/campaigns endpoint).
|
entity_type
|
Type of table (should be one of
fact, dimension or addaccount).
|
object_id_column
|
Columns (separated by comma) that
form a unique record for this table. Only required
when entity_type is fact.
|
breakdowns
|
Optional: Breakdown columns
(separated by comma) for insights endpoints. Only applicable
when entity_type is fact.
|
action_breakdowns
|
Optional: Action breakdown columns
(separated by comma) for insights endpoints. Only applicable
when entity_type is fact.
|
partition_details
|
Optional: If you want this table to be partitioned for performance considerations. For more information, see Table Partition. |
cluster_details
|
Optional: If you want this table to be clustered for performance considerations. For more information, see Cluster Settings. |
Raw to CDC tables
This section describes the entries that control how data is moved from Raw tables to CDC tables. Each entry corresponds with a raw table (which in turn corresponds with Meta API entity as mentioned).
The following parameters control the settings for Raw to CDC for each entry:
| Parameter | Description |
base_table
|
Table on which raw data has been
replicated. A table with the same name in CDC dataset stores
the raw data after CDC transformation (for example, campaign_insights).
|
row_identifiers
|
Columns (separated by comma) that form a unique record for this table. |
load_frequency
|
How frequently a DAG for this entity runs to populate the CDC table. For more information about possible values, see Airflow documentation. |
partition_details
|
Optional: If you want this table to be partitioned for performance considerations. For more information, see Table Partition. |
cluster_details
|
Optional: If you want this table to be clustered for performance considerations. For more information, see Cluster Settings. |
CDC table schema
For Meta, all fields are stored in string format in the raw layer. In the CDC layer, primitive types are converted to relevant business data types, and all complex types are stored in BigQuery JSON format.
To enable this conversion, directory src/Meta/config/table_schema
contains one schema file for each entity specified in raw_to_cdc_tables
section that explains how to properly translate each BigQueryraw table into CDC table.
Each schema file contains three columns:
SourceField: Field name of the raw table for this entity.TargetField: Column name in the cdc table for this entity.DataType: Data type of each cdc table field.
Reporting settings
You can configure and control how Cortex generates data for the Meta final
reporting layer using the reporting settings file
(src/Meta/config/reporting_settings.yaml). This file controls
how reporting layer BigQuery objects (tables, views, functions
or stored procedures ) are generated.
For more information, see Customizing reporting settings file.
What's next?
- For more information about other data sources and workloads, see Data sources and workloads.
- For more information about the steps for deployment in production environments, see Cortex Framework Data Foundation deployment prerequisites.