Campaign Manager 360 통합
이 페이지에서는 Cortex Framework Data Foundation의 마케팅 워크로드 데이터 소스로 Campaign Manager 360의 데이터를 가져오는 데 필요한 구성을 설명합니다.
Campaign Manager 360 (CM360)은 광고주 및 대행사를 위해 Google에서 제공하는 웹 기반 광고 관리 플랫폼입니다. 다양한 채널에서 모든 디지털 광고 캠페인을 관리하고 최적화하는 중앙 허브 역할을 합니다. Cortex Framework는 CM360 데이터를 분석하고, 다른 마케팅 채널의 데이터와 결합하며, AI를 사용하여 심층적인 통계를 얻고 전반적인 마케팅 전략을 최적화하는 도구와 플랫폼을 제공합니다.
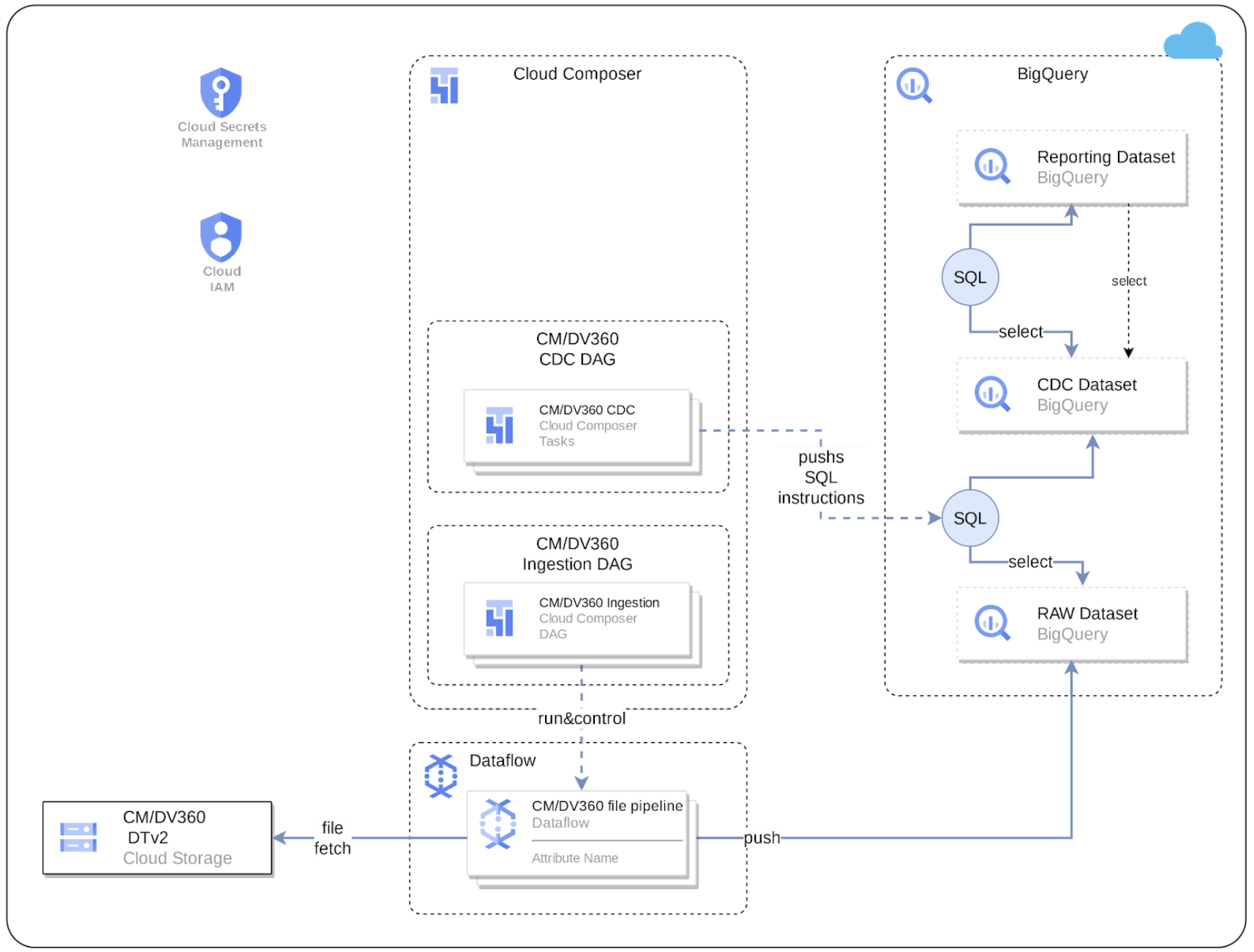
다음 다이어그램은 Cortex Framework Data Foundation의 마케팅 워크로드를 통해 CM360 데이터를 사용하는 방법을 설명합니다.
구성 파일
config.json 파일은 다양한 워크로드에서 데이터를 전송하기 위해 데이터 소스에 연결하는 데 필요한 설정을 구성합니다. 이 파일에는 CM360의 다음 매개변수가 포함되어 있습니다.
"marketing": {
"deployCM360": true,
}
"CM360": {
"deployCDC": true,
"dataTransferBucket": "",
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING_CM360"
}
}
다음 표에는 각 마케팅 매개변수의 값이 설명되어 있습니다.
| 매개변수 | 의미 | 기본값 | 설명 |
marketing.deployCM360
|
CM360 배포 | true
|
CM360 데이터 소스의 배포를 실행합니다. |
marketing.CM360.deployCDC
|
CM360용 CDC 스크립트 배포 | true
|
Cloud Composer에서 DAG로 실행할 CM360 CDC 처리 스크립트를 생성합니다. |
marketing.CM360.dataTransferBucket
|
Data Transfer Service 결과가 포함된 버킷 | - | DTv2 파일이 저장되는 버킷입니다. |
marketing.CM360.datasets.cdc
|
CM360용 CDC 데이터 세트 | CM360용 CDC 데이터 세트입니다. | |
marketing.CM360.datasets.raw
|
CM360의 원시 데이터 세트 | CM360의 원시 데이터 세트입니다. | |
marketing.CM360.datasets.reporting
|
CM360 보고 데이터 세트 | "REPORTING_CM360"
|
CM360 보고 데이터 세트입니다. |
데이터 모델
이 섹션에서는 항목 관계 다이어그램 (ERD)을 사용하여 CM360 데이터 모델을 설명합니다.
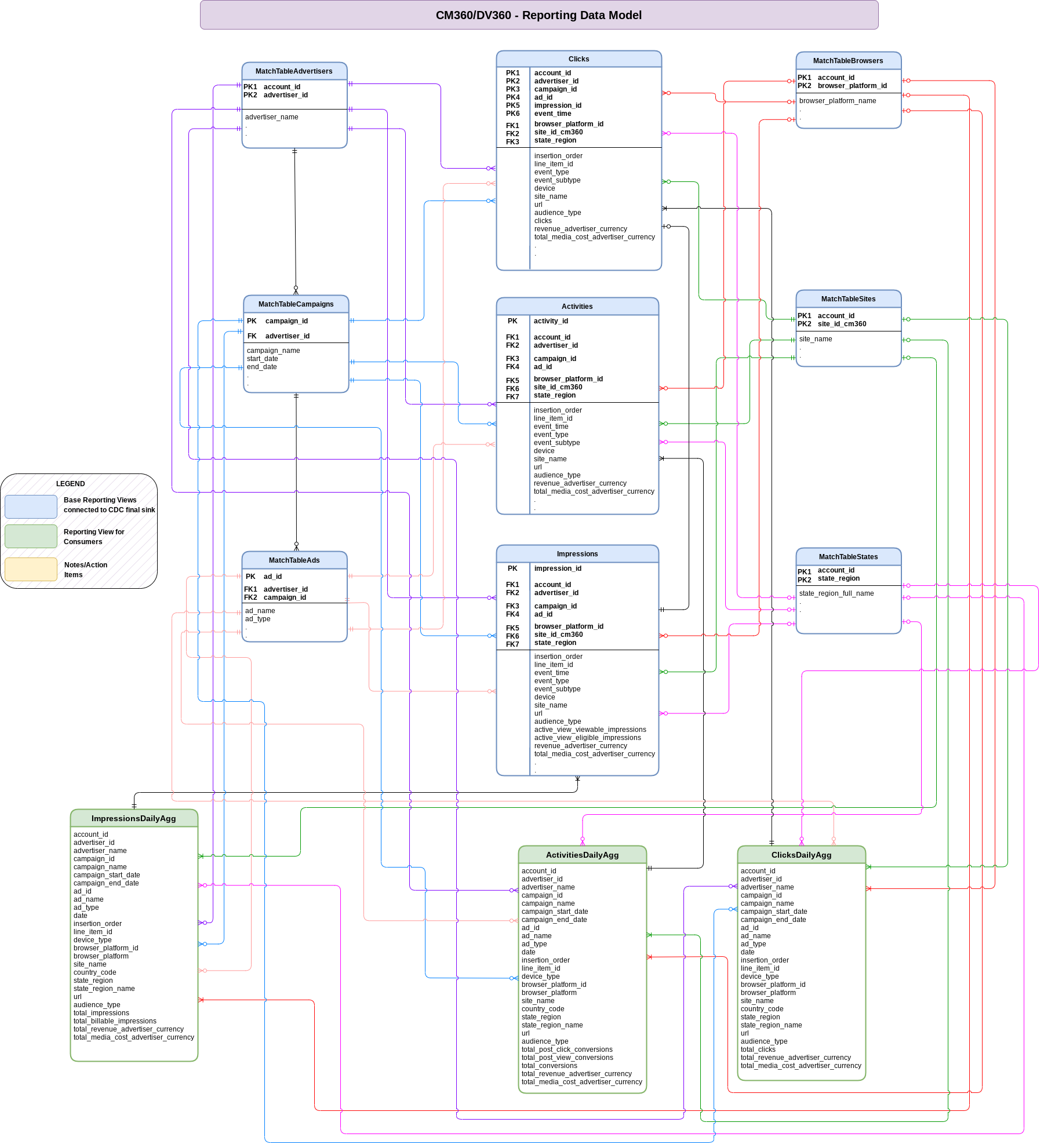
기본 조회수
ERD의 파란색 객체이며 일부 열 이름 별칭 외에 변환이 없는 CDC 테이블의 뷰입니다. src/marketing/src/CM360/src/reporting/ddls에서 스크립트를 확인하세요.
보고 보기
ERD의 녹색 객체이며 집계 측정항목이 포함된 보고 뷰입니다. src/marketing/src/CM360/src/reporting/ddls에서 스크립트를 확인하세요.
DTv2 파일 저장소
DTv2 (데이터 전송 버전 2) 파일은 CM360에서 캠페인 실적 데이터를 전송하는 데 사용하는 특정 형식입니다. Cortex Framework에서 CM360을 사용하려면 데이터 전송 V2.0 문서에 따라 데이터 전송 프로세스를 설정합니다.
CM360에서 DTv2 파일을 저장할 Cloud Storage 버킷을 만들거나 추가합니다. Cloud Composer에서 DAG를 실행하는 서비스 계정이 버킷 아래의 파일을 읽을 수 있는지 확인합니다. 자세한 내용은 스토리지 버킷 만들기를 참고하세요.
데이터 최신 상태 및 지연
일반적으로 Cortex Framework 데이터 소스의 데이터 최신성은 업스트림 연결에서 허용하는 사항과 DAG 실행 빈도에 따라 제한됩니다. 업스트림 빈도, 리소스 제약조건, 비즈니스 요구사항에 맞게 DAG 실행 빈도를 조정합니다.
CM360 데이터 전송 v2를 사용하면 노출수 및 클릭수 데이터가 하루에 24번 (시간당) 전송됩니다. 처리 시간은 파일마다 다를 수 있으므로 파일이 순서대로 표시되지 않을 수 있습니다. 활동 파일은 매일 전송됩니다.
Cloud Composer 연결
Cloud Composer에서 다음 연결을 만듭니다. 자세한 내용은 Airflow 연결 관리 문서를 참고하세요.
| 연결 이름 | 목적 |
cm360_raw_dataflow
|
CM360 DTv2 파일 > BigQuery 원시 데이터 세트 |
cm360_cdc_bq
|
원시 데이터 세트 > CDC 데이터 세트 전송 |
cm360_reporting_bq
|
CDC 데이터 세트 > 보고 데이터 세트 전송 |
Cloud Composer 서비스 계정 권한
Cloud Composer에서 사용되는 서비스 계정 (cm360_raw_dataflow 연결에 구성됨)에 Dataflow 권한을 부여합니다.
Dataflow 문서의 안내를 참고하세요.
처리 설정
src/CM360/config/ingestion_settings.yaml 파일의 설정을 통해 Source to Raw 및 Raw to CDC 데이터 파이프라인을 제어합니다. 이 섹션에서는 각 데이터 파이프라인의 매개변수를 설명합니다.
원시 테이블의 소스
이 섹션에서는 DTv2의 어떤 파일이 처리되는지 제어하는 항목의 작동 방식을 설명합니다. 각 항목은 하나의 항목과 연결된 파일에 해당합니다. 이 구성을 기반으로 Cortex Framework는 Dataflow 파이프라인을 실행하여 DTv2 파일의 데이터를 처리하는 Airflow DAG를 만듭니다.
다음 매개변수는 각 항목의 Source to Raw 설정을 제어합니다.
| 매개변수 | 설명 |
base_table
|
항목의 데이터가 저장되는 원시 데이터 세트의 테이블입니다 (예: '클릭수' 데이터). |
load_frequency
|
이 항목의 DAG가 CDC 테이블을 채우기 위해 실행되는 빈도입니다. 가능한 값에 관한 자세한 내용은 Airflow 문서를 참고하세요. |
file_pattern
|
항목에 해당하는 기반 파일 이름 패턴 |
schema_file
|
DTv2 필드를 대상 테이블의 열 이름 및 데이터 유형에 매핑하는 src/table_schema 디렉터리의 스키마 파일입니다.
|
partition_details
|
선택사항: 성능 고려사항으로 인해 이 테이블을 파티션화하려는 경우 자세한 내용은 테이블 파티션을 참고하세요. |
cluster_details
|
선택사항: 성능 고려사항으로 이 테이블을 클러스터링하려는 경우 자세한 내용은 클러스터 설정을 참고하세요. |
원시 테이블에서 CDC 테이블로
이 섹션에는 데이터가 원시 테이블에서 CDC 테이블로 이동되는 방식을 제어하는 항목이 있습니다. 각 항목은 원시 테이블에 해당하며 이는 위에 언급된 DTv2 항목에 해당합니다.
다음 매개변수는 각 항목의 Raw to CDC 설정을 제어합니다.
| 매개변수 | 설명 |
base_table
|
CDC 변환 후 원시 데이터가 저장되는 CDC 데이터 세트의 테이블입니다 (예: customer).
|
load_frequency
|
이 항목의 DAG가 CDC 테이블을 채우기 위해 실행되는 빈도입니다. 가능한 값에 관한 자세한 내용은 Airflow 문서를 참고하세요. |
row_identifiers
|
이 테이블의 고유한 레코드를 형성하는 열 목록 (쉼표로 구분됨)입니다. |
partition_details
|
선택사항: 성능 고려사항으로 인해 이 테이블을 파티션화하려는 경우 자세한 내용은 테이블 파티션을 참고하세요. |
cluster_details
|
선택사항: 성능 고려사항으로 이 테이블을 클러스터링하려는 경우 자세한 내용은 클러스터 설정을 참고하세요. |
보고서 설정
보고 설정 파일 (src/CM360/config/reporting_settings.yaml)을 사용하여 Cortex Framework가 CM360 최종 보고 영역의 데이터를 생성하는 방식을 구성하고 제어할 수 있습니다. 이 파일은 보고 영역 BigQuery 객체(테이블, 뷰, 함수 또는 저장 프로시저)가 생성되는 방식을 제어합니다.
자세한 내용은 보고서 설정 파일 맞춤설정을 참고하세요.
다음 단계
- 다른 데이터 소스 및 워크로드에 관한 자세한 내용은 데이터 소스 및 워크로드를 참고하세요.
- 프로덕션 환경에서 배포하는 단계에 관한 자세한 내용은 Cortex Framework Data Foundation 배포 기본 요건을 참고하세요.