Étape 1 : Établir les charges de travail
Cette page vous guide dans la première étape de la configuration de votre base de données, qui est au cœur de Cortex Framework. Basée sur le stockage BigQuery, la base de données organise les données entrantes provenant de diverses sources. Ces données organisées simplifient l'analyse et leur application dans le développement de l'IA.
Configurer l'intégration de données
Commencez par définir des paramètres clés qui serviront de modèle pour organiser et utiliser efficacement vos données dans Cortex Framework. N'oubliez pas que ces paramètres peuvent varier en fonction de la charge de travail spécifique, du flux de données choisi et du mécanisme d'intégration. Le schéma suivant présente l'intégration des données dans la fondation de données Cortex Framework :

Définissez les paramètres suivants avant le déploiement pour une utilisation efficace des données dans Cortex Framework.
Projets
- Projet source : projet dans lequel se trouvent vos données brutes. Vous avez besoin d'au moins un projet Google Cloud pour stocker les données et exécuter le processus de déploiement.
- Projet cible (facultatif) : projet dans lequel Cortex Framework Data Foundation stocke ses modèles de données traités. Il peut s'agir du même projet que le projet source ou d'un autre, selon vos besoins.
Si vous souhaitez disposer d'ensembles distincts de projets et d'ensembles de données pour chaque charge de travail (par exemple, un ensemble de projets sources et cibles pour SAP et un autre ensemble de projets cibles et sources pour Salesforce), exécutez des déploiements distincts pour chaque charge de travail. Pour en savoir plus, consultez la section Utiliser différents projets pour séparer les accès dans la section des étapes facultatives.
Modèle de données
- Déployer des modèles : choisissez si vous devez déployer des modèles pour toutes les charges de travail ou uniquement pour un ensemble de modèles (par exemple, SAP, Salesforce et Meta). Pour en savoir plus, consultez les sources de données et les charges de travail disponibles.
Ensembles de données BigQuery
- Ensemble de données source (brutes) : ensemble de données BigQuery dans lequel les données sources sont répliquées ou dans lequel les données de test sont créées. Nous vous recommandons d'utiliser des ensembles de données distincts, un pour chaque source de données. Par exemple, un ensemble de données brutes pour SAP et un autre pour Google Ads. Cet ensemble de données appartient au projet source.
- Ensemble de données CDC : ensemble de données BigQuery dans lequel les données traitées par CDC sont stockées (derniers enregistrements disponibles). Certaines charges de travail permettent le mappage des noms de champs. Nous vous recommandons d'avoir un ensemble de données CDC distinct pour chaque source. Par exemple, un ensemble de données CDC pour SAP et un autre pour Salesforce. Cet ensemble de données appartient au projet source.
- Ensemble de données de reporting cible : ensemble de données BigQuery dans lequel les modèles de données prédéfinis de Data Foundation sont déployés. Nous vous recommandons de disposer d'un ensemble de données de reporting distinct pour chaque source. Par exemple, un ensemble de données de reporting pour SAP et un autre pour Salesforce. Cet ensemble de données est créé automatiquement lors du déploiement s'il n'existe pas. Cet ensemble de données appartient au projet "Target".
- Prétraitement de l'ensemble de données K9 : ensemble de données BigQuery dans lequel des composants DAG réutilisables et inter-charges de travail, tels que les dimensions
time, peuvent être déployés. Les charges de travail dépendent de cet ensemble de données, sauf si elles sont modifiées. Cet ensemble de données est créé automatiquement lors du déploiement s'il n'existe pas. Cet ensemble de données appartient au projet source. - Ensemble de données K9 post-traitement : ensemble de données BigQuery dans lequel des rapports inter-charges de travail et des DAG de sources externes supplémentaires (par exemple, l'ingestion Google Trends) peuvent être déployés. Cet ensemble de données est créé automatiquement lors du déploiement s'il n'existe pas. Cet ensemble de données appartient au projet "Target".
Facultatif : Générer des exemples de données
Cortex Framework peut générer des exemples de données et de tableaux pour vous si vous n'avez pas accès à vos propres données, ni à des outils de réplication pour configurer les données, ou même si vous souhaitez simplement voir comment fonctionne Cortex Framework. Toutefois, vous devez toujours créer et identifier les ensembles de données CDC et brutes à l'avance.
Créez des ensembles de données BigQuery pour les données brutes et la CDC par source de données, en suivant les instructions ci-dessous.
Console
Ouvrez la page BigQuery dans la console Google Cloud .
Dans le panneau Explorer, sélectionnez le projet dans lequel vous souhaitez créer l'ensemble de données.
Développez l'option Actions, puis cliquez sur Créer un ensemble de données :
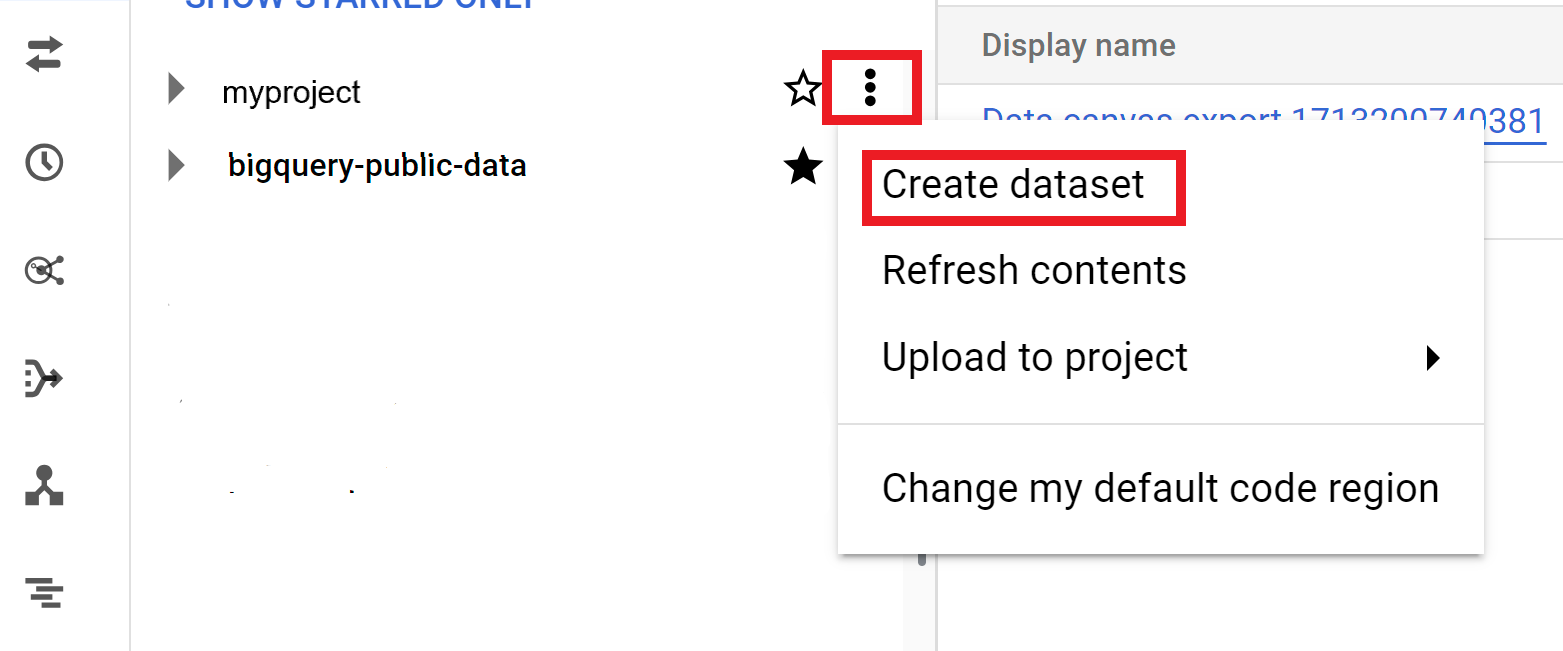
Sur la page Créer un ensemble de données, procédez comme suit :
- Pour ID de l'ensemble de données, indiquez le nom d'un ensemble de données unique.
Dans Type d'emplacement, sélectionnez un emplacement géographique pour l'ensemble de données. Une fois l'ensemble de données créé, l'emplacement ne peut plus être modifié.
Facultatif. Pour en savoir plus sur la personnalisation de votre ensemble de données, consultez Créer des ensembles de données : console.
Cliquez sur Créer un ensemble de données.
BigQuery
Créez un ensemble de données pour les données brutes en copiant la commande suivante :
bq --location= LOCATION mk -d SOURCE_PROJECT: DATASET_RAWRemplacez les éléments suivants :
LOCATIONavec l'emplacement de l'ensemble de données.SOURCE_PROJECTpar l'ID de votre projet source.DATASET_RAWpar le nom de votre ensemble de données pour les données brutes. Exemple :CORTEX_SFDC_RAW
Créez un ensemble de données pour les données du CDC en copiant la commande suivante :
bq --location=LOCATION mk -d SOURCE_PROJECT: DATASET_CDCRemplacez les éléments suivants :
LOCATIONavec l'emplacement de l'ensemble de données.SOURCE_PROJECTpar l'ID de votre projet source.DATASET_CDCpar le nom de votre ensemble de données pour les données CDC. Exemple :CORTEX_SFDC_CDC
Confirmez que les ensembles de données ont été créés avec la commande suivante :
bq lsFacultatif. Pour en savoir plus sur la création d'ensembles de données, consultez Créer des ensembles de données.
Étapes suivantes
Une fois cette étape terminée, passez aux étapes de déploiement suivantes :
- Établissez les charges de travail (cette page).
- Clonez le dépôt.
- Déterminez le mécanisme d'intégration.
- Configurer les composants
- Configurez le déploiement.
- Exécutez le déploiement.