Cloud Composer 3 | Cloud Composer 2 | Cloud Composer 1
Esta página descreve como usar o KubernetesPodOperator para implantar pods do Kubernetes do Cloud Composer no cluster do Google Kubernetes Engine que faz parte do seu ambiente do Cloud Composer.
O KubernetesPodOperator inicia pods do Kubernetes no cluster do ambiente. Em comparação, os operadores do Google Kubernetes Engine executam pods do Kubernetes em um cluster especificado, que pode ser um cluster separado não relacionado ao seu ambiente. Também é possível criar e excluir clusters usando os operadores do Google Kubernetes Engine.
O KubernetesPodOperator é uma boa opção se você precisar de:
- Dependências personalizadas do Python que não estão disponíveis no repositório PyPI público.
- Dependências binárias que não estão disponíveis na imagem do worker do Cloud Composer.
Antes de começar
- Recomendamos usar a versão mais recente do Cloud Composer. No mínimo, essa versão precisa ser compatível como parte da política de suspensão de uso e suporte.
- Certifique-se de que o ambiente tenha recursos suficientes. Lançar pods em um ambiente com poucos recursos pode causar erros no worker e no programador do Airflow.
Configurar os recursos do ambiente do Cloud Composer
Ao criar um ambiente do Cloud Composer, você especifica os parâmetros de desempenho dele, incluindo os parâmetros de desempenho para o cluster do ambiente. Iniciar pods do Kubernetes no cluster de ambiente pode causar competição por recursos do cluster, como CPU ou memória. Como o programador e os workers do Airflow estão no mesmo cluster do GKE, eles não funcionarão corretamente, se a competição resultar na falta de recursos.
Para evitar a privação de recursos, realize uma ou mais das seguintes ações:
- (Recomendado) Criar um pool de nós
- Aumentar o número de nós no ambiente
- Especifique o tipo de máquina apropriado
Crie um pool de nós.
A maneira recomendável de evitar a privação de recursos no ambiente do Cloud Composer é criar um novo pool de nós e configurar os pods do Kubernetes para que sejam executados usando somente os recursos desse pool.
Console
No console do Google Cloud, acesse a página Ambientes.
Clique no nome do seu ambiente.
Na página Detalhes do ambiente, acesse a guia Configuração do ambiente.
Na seção Recursos > Cluster do GKE, siga o link ver detalhes do cluster.
Crie um pool de nós conforme descrito em Como adicionar um pool de nós.
gcloud
Determine o nome do cluster de ambiente:
gcloud composer environments describe ENVIRONMENT_NAME \ --location LOCATION \ --format="value(config.gkeCluster)"Substitua:
ENVIRONMENT_NAMEpelo nome do ambienteLOCATIONpela região em que o ambiente está localizado;
A saída contém o nome do cluster do ambiente. Por exemplo, pode ser
europe-west3-example-enviro-af810e25-gke.Crie um pool de nós conforme descrito em Como adicionar um pool de nós.
Aumentar o número de nós no ambiente
O aumento do número de nós no ambiente do Cloud Composer aumenta a capacidade de computação disponível para as cargas de trabalho. Esse aumento não fornece outros recursos para tarefas que exigem mais CPU ou RAM do que o tipo de máquina especificado fornece.
Para aumentar a contagem de nós, atualize o ambiente.
Especifique o tipo de máquina apropriado
Durante a criação do ambiente do Cloud Composer, é possível especificar um tipo de máquina. Para garantir que hajam recursos disponíveis, especifique um tipo de máquina para o tipo de computação que ocorrer no ambiente do Cloud Composer.
Configuração mínima
Para criar um KubernetesPodOperator, somente os parâmetros name, image to use e
task_id do pod são necessários. O /home/airflow/composer_kube_config
contém credenciais para autenticação no GKE.
Airflow 2
Airflow 1
Configuração de afinidade de pods
Ao configurar o parâmetro affinity no KubernetesPodOperator, você
controla em quais nós os pods serão programados, como, por exemplo, nós apenas em um determinado
pool de nós. Neste exemplo, o operador é executado somente nos pools de nós chamados
pool-0 e pool-1. Os nós do ambiente do Cloud Composer 1 estão no
default-pool. Portanto, os pods não são executados nos nós do ambiente.
Airflow 2
Airflow 1
Como o exemplo está configurado, a tarefa falha. Se você analisar os registros, a tarefa
vai falhar porque os pools de nós pool-0 e pool-1 não existem.
Para garantir que os pools de nós em values existam, faça uma destas alterações de configuração:
Caso um pool de nós tenha sido criado anteriormente, substitua
pool-0epool-1pelos nomes dos pools de nós e faça o upload do DAG novamente.Crie um pool de nós chamado
pool-0oupool-1. É possível criar ambos, mas a tarefa precisa de apenas um para ser bem-sucedida.Substitua
pool-0epool-1pordefault-pool, que é o pool padrão usado pelo Airflow. Em seguida, faça o upload do DAG novamente.
Depois de fazer as alterações, aguarde alguns minutos para que o ambiente seja atualizado.
Em seguida, execute a tarefa ex-pod-affinity novamente e verifique se a tarefa ex-pod-affinity
foi bem-sucedida.
Configurações avançadas
Este exemplo mostra outros parâmetros que podem ser configurados no KubernetesPodOperator.
Para mais informações, consulte os recursos a seguir:
Para informações sobre como usar Secrets e ConfigMaps do Kubernetes, consulte Usar Secrets e ConfigMaps do Kubernetes.
Para informações sobre como usar modelos Jinja com o KubernetesPodOperator, consulte Usar modelos Jinja.
Para informações sobre os parâmetros do KubernetesPodOperator, consulte a referência do operador na documentação do Airflow.
Airflow 2
Airflow 1
Usar modelos Jinja
O Airflow é compatível com modelos Jinja em DAGs.
Você precisa declarar os parâmetros necessários do Airflow (task_id, name e
image) com o operador. Como mostra o exemplo a seguir,
é possível criar modelos de todos os outros parâmetros com o Jinja, incluindo cmds,
arguments, env_vars e config_file.
O parâmetro env_vars no exemplo é definido a partir de uma variável do Airflow chamada my_value. O DAG de exemplo
pega o valor da variável de modelo vars no Airflow. O Airflow tem mais variáveis que fornecem acesso a diferentes tipos de informações. Por exemplo,
é possível usar a variável de modelo conf para acessar valores de
opções de configuração do Airflow. Para mais informações e a lista de variáveis disponíveis no Airflow, consulte a referência de modelos na documentação do Airflow.
Sem alterar o DAG ou criar a variável env_vars, a
tarefa ex-kube-templates no exemplo falha porque a variável não
existe. Crie essa variável na interface do Airflow ou com a CLI do Google Cloud:
IU do Airflow
Acesse a IU do Airflow.
Na barra de ferramentas, selecione Administrador > Variáveis.
Na página Listar variáveis, clique em Adicionar um novo registro.
Na página Adicionar variável, digite as seguintes informações:
- Chave:
my_value - Val:
example_value
- Chave:
Clique em Salvar.
Se o ambiente usar o Airflow 1, execute o comando a seguir:
Acesse a IU do Airflow.
Na barra de ferramentas, selecione Administrador > Variáveis.
Na página Variáveis, clique na guia Criar.
Na página Variável, digite as seguintes informações:
- Chave:
my_value - Val:
example_value
- Chave:
Clique em Save.
gcloud
Digite este comando:
gcloud composer environments run ENVIRONMENT \
--location LOCATION \
variables set -- \
my_value example_value
Se o ambiente usar o Airflow 1, execute o comando a seguir:
gcloud composer environments run ENVIRONMENT \
--location LOCATION \
variables -- \
--set my_value example_value
Substitua:
ENVIRONMENTpelo nome do ambienteLOCATIONpela região em que o ambiente está localizado;
O exemplo a seguir demonstra como usar modelos Jinja com o KubernetesPodOperator:
Airflow 2
Airflow 1
Usar secrets e ConfigMaps do Kubernetes
Um secret do Kubernetes é um objeto que contém dados sensíveis. Um ConfigMap do Kubernetes é um objeto que contém dados não confidenciais em pares de chave-valor.
No Cloud Composer 2, é possível criar segredos e ConfigMaps usando a CLI, a API ou o Terraform do Google Cloud e acessá-los no KubernetesPodOperator.
Sobre os arquivos de configuração YAML
Ao criar um secret do Kubernetes ou um ConfigMap usando a CLI e a API do Google Cloud, você fornece um arquivo no formato YAML. Esse arquivo precisa seguir o mesmo formato usado pelos Secrets e ConfigMaps do Kubernetes. A documentação do Kubernetes oferece muitos exemplos de código de ConfigMaps e Secrets. Para começar, consulte a página Distribuição de credenciais com segurança usando secrets e ConfigMaps.
Como nos secrets do Kubernetes, use a representação base64 ao definir valores nos secrets.
Para codificar um valor, use o comando a seguir, que é uma das muitas maneiras de conseguir um valor codificado em base64:
echo "postgresql+psycopg2://root:example-password@127.0.0.1:3306/example-db" -n | base64
Saída:
cG9zdGdyZXNxbCtwc3ljb3BnMjovL3Jvb3Q6ZXhhbXBsZS1wYXNzd29yZEAxMjcuMC4wLjE6MzMwNi9leGFtcGxlLWRiIC1uCg==
Os dois exemplos de arquivo YAML a seguir são usados em exemplos mais adiante neste guia. Exemplo de arquivo de configuração YAML para um segredo do Kubernetes:
apiVersion: v1
kind: Secret
metadata:
name: airflow-secrets
data:
sql_alchemy_conn: cG9zdGdyZXNxbCtwc3ljb3BnMjovL3Jvb3Q6ZXhhbXBsZS1wYXNzd29yZEAxMjcuMC4wLjE6MzMwNi9leGFtcGxlLWRiIC1uCg==
Outro exemplo que demonstra como incluir arquivos. Como no exemplo anterior, primeiro codifique o conteúdo de um arquivo (cat ./key.json | base64) e depois forneça esse valor no arquivo YAML:
apiVersion: v1
kind: Secret
metadata:
name: service-account
data:
service-account.json: |
ewogICJ0eXBl...mdzZXJ2aWNlYWNjb3VudC5jb20iCn0K
Um exemplo de arquivo de configuração YAML para um ConfigMap. Não é necessário usar a representação base64 em ConfigMaps:
apiVersion: v1
kind: ConfigMap
metadata:
name: example-configmap
data:
example_key: example_value
Gerenciar secrets do Kubernetes
No Cloud Composer 2, você cria segredos usando a CLI do Google Cloud e kubectl:
Receber informações sobre o cluster do ambiente:
Execute este comando:
gcloud composer environments describe ENVIRONMENT \ --location LOCATION \ --format="value(config.gkeCluster)"Substitua:
ENVIRONMENTpelo nome do ambiente.LOCATIONé a região em que o ambiente do Cloud Composer está localizado.
A saída desse comando usa o seguinte formato:
projects/<your-project-id>/zones/<zone-of-composer-env>/clusters/<your-cluster-id>.Para receber o ID do cluster do GKE, copie a saída depois de
/clusters/(termina em-gke).Para ver a zona, copie a saída após
/zones/.
Conecte-se ao cluster do GKE com o seguinte comando:
gcloud container clusters get-credentials CLUSTER_ID \ --project PROJECT \ --zone ZONESubstitua:
CLUSTER_ID: o ID do cluster do ambiente.PROJECT_ID: o ID do projeto.ZONEpela zona em que o cluster do ambiente está localizado.
Crie secrets do Kubernetes:
Os comandos a seguir demonstram duas abordagens diferentes para criar secrets do Kubernetes. A abordagem
--from-literalusa pares de chave-valor. A abordagem--from-fileusa o conteúdo do arquivo.Para criar um secret do Kubernetes fornecendo pares de chave-valor, execute o comando abaixo. Este exemplo cria um secret chamado
airflow-secretsque tem um camposql_alchemy_conncom o valortest_value.kubectl create secret generic airflow-secrets \ --from-literal sql_alchemy_conn=test_valuePara criar um secret do Kubernetes fornecendo o conteúdo do arquivo, execute o seguinte comando. Este exemplo cria um Secret chamado
service-accountque tem o camposervice-account.jsoncom o valor extraído do conteúdo de um arquivo./key.jsonlocal.kubectl create secret generic service-account \ --from-file service-account.json=./key.json
Usar os secrets do Kubernetes nos seus DAGs
Este exemplo mostra duas maneiras de usar os Secrets do Kubernetes: como uma variável de ambiente e como um volume montado pelo pod.
O primeiro secret, airflow-secrets, é definido
como uma variável de ambiente do Kubernetes chamada SQL_CONN (em vez de uma
variável de ambiente do Airflow ou do Cloud Composer).
O segundo secret, service-account, instala service-account.json, um arquivo
com um token de conta de serviço, em /var/secrets/google.
Confira como são os objetos Secret:
Airflow 2
Airflow 1
O nome do primeiro secret do Kubernetes é definido na variável secret_env.
Esse secret é chamado de airflow-secrets. O parâmetro deploy_type especifica
que ele precisa ser exposto como uma variável de ambiente. O nome da variável de ambiente
é SQL_CONN, conforme especificado no parâmetro deploy_target. Por fim, o
valor da variável de ambiente SQL_CONN é definido como o valor da
chave sql_alchemy_conn.
O nome do segundo secret do Kubernetes é definido na variável secret_volume. Esse secret é chamado de service-account. Ele é exposto como um
volume, conforme especificado no parâmetro deploy_type. O caminho do arquivo a ser
ativado, deploy_target, é /var/secrets/google. Por fim, o key do
secret armazenado no deploy_target é service-account.json.
Veja como é a configuração do operador:
Airflow 2
Airflow 1
Informações sobre o Kubernetes Provider do CNCF
O KubernetesPodOperator é implementado no
provedor apache-airflow-providers-cncf-kubernetes.
Para ver as notas de lançamento detalhadas do provedor do Kubernetes do CNCF, acesse o site do provedor do Kubernetes do CNCF (em inglês).
Versão 6.0.0
Na versão 6.0.0 do pacote do provedor Kubernetes do CNCF,
a conexão kubernetes_default é usada por padrão no KubernetesPodOperator.
Se você especificou uma conexão personalizada na versão 5.0.0, essa conexão personalizada
ainda é usada pelo operador. Para voltar a usar a conexão kubernetes_default, ajuste seus DAGs de acordo com isso.
Versão 5.0.0
Esta versão apresenta algumas mudanças incompatíveis com versões anteriores
em comparação com a versão 4.4.0. As mais importantes estão relacionadas à
conexão kubernetes_default, que não é usada na versão 5.0.0.
- A conexão
kubernetes_defaultprecisa ser modificada. O caminho de configuração do Kubernetes precisa ser definido como/home/airflow/composer_kube_config(conforme mostrado na figura a seguir). Como alternativa,config_fileprecisa ser adicionado à configuração do KubernetesPodOperator, conforme mostrado no exemplo de código abaixo.
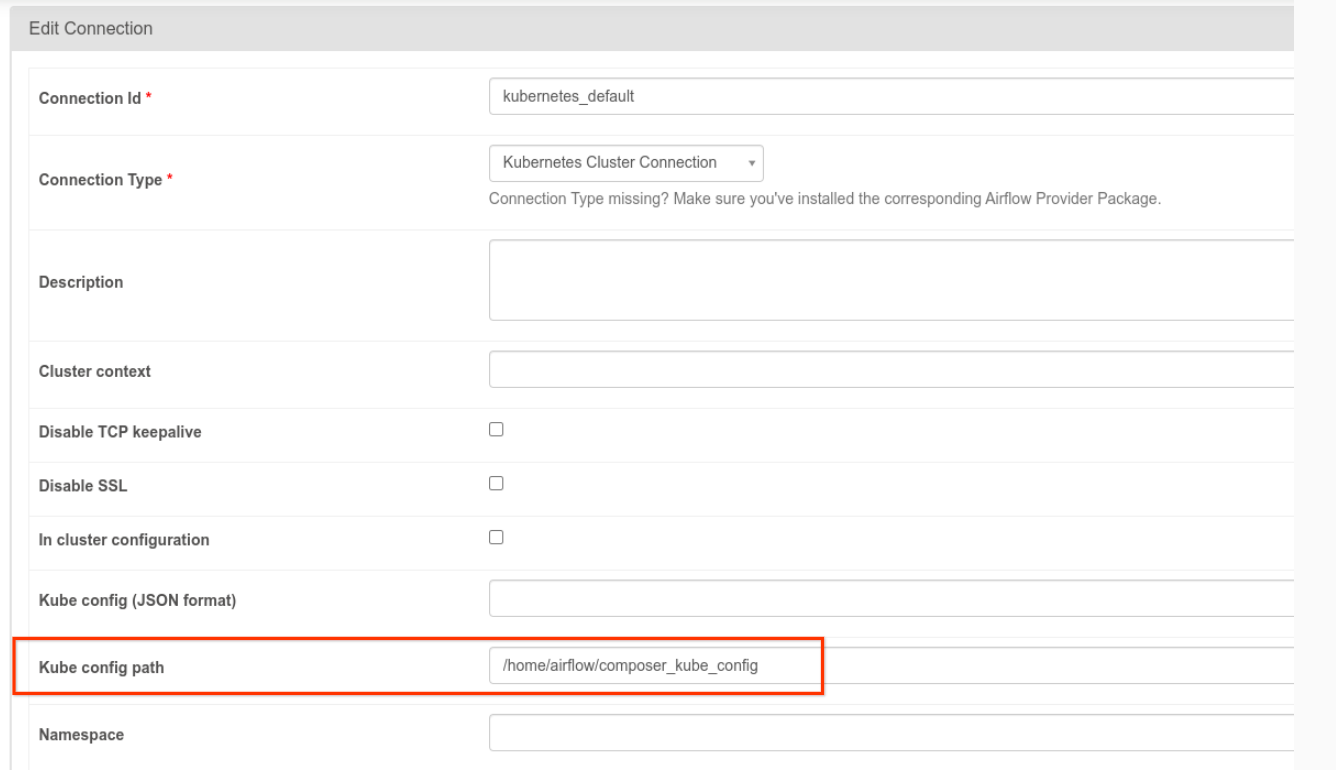
- Modifique o código de uma tarefa usando o KubernetesPodOperator da seguinte maneira:
KubernetesPodOperator(
# config_file parameter - can be skipped if connection contains this setting
config_file="/home/airflow/composer_kube_config",
# definition of connection to be used by the operator
kubernetes_conn_id='kubernetes_default',
...
)
Para mais informações sobre a versão 5.0.0, consulte as Notas da versão do provedor do Kubernetes do CNCF.
Solução de problemas
Esta seção oferece conselhos para resolver problemas comuns do KubernetesPodOperator:
Ver registros
Ao resolver problemas, verifique os registros na seguinte ordem:
Registros de tarefas do Airflow:
No console do Google Cloud, acesse a página Ambientes.
Na lista de ambientes, clique no nome do seu ambiente. A página Detalhes do ambiente é aberta.
Acesse a guia DAGs.
Clique no nome do DAG e, em seguida, na execução do DAG para conferir os detalhes e os registros.
Registros do programador do Airflow:
Acesse a página Detalhes do ambiente.
Acesse a guia Registros.
Inspecione os registros do agendador do Airflow.
Registros do pod no console do Google Cloud, em cargas de trabalho do GKE. Esses registros incluem o arquivo YAML de definição, os eventos e os detalhes do pod.
Códigos de retorno diferentes de zero
Ao usar o KubernetesPodOperator (e o GKEStartPodOperator), o código de retorno do ponto de entrada do contêiner determina se a tarefa é considerada bem-sucedida ou não. Os códigos de retorno diferentes de zero indicam a falha.
Um padrão comum é executar um script de shell como o ponto de entrada do contêiner para agrupar várias operações dentro do contêiner.
Se você estiver escrevendo esse script, recomendamos que inclua o comando set -e na parte de cima para que comandos com falha encerrem o script e propaguem a falha para a instância de tarefa do Airflow.
Tempos limite do pod
O tempo limite padrão para o KubernetesPodOperator é de 120 segundos, o que
pode resultar em tempos limite antes do download de imagens maiores. É possível
aumentar o tempo limite alterando o parâmetro startup_timeout_seconds ao
criar o KubernetesPodOperator.
Quando um pod expira, o registro específico da tarefa fica disponível na IU do Airflow. Exemplo:
Executing <Task(KubernetesPodOperator): ex-all-configs> on 2018-07-23 19:06:58.133811
Running: ['bash', '-c', u'airflow run kubernetes-pod-example ex-all-configs 2018-07-23T19:06:58.133811 --job_id 726 --raw -sd DAGS_FOLDER/kubernetes_pod_operator_sample.py']
Event: pod-name-9a8e9d06 had an event of type Pending
...
...
Event: pod-name-9a8e9d06 had an event of type Pending
Traceback (most recent call last):
File "/usr/local/bin/airflow", line 27, in <module>
args.func(args)
File "/usr/local/lib/python2.7/site-packages/airflow/bin/cli.py", line 392, in run
pool=args.pool,
File "/usr/local/lib/python2.7/site-packages/airflow/utils/db.py", line 50, in wrapper
result = func(*args, **kwargs)
File "/usr/local/lib/python2.7/site-packages/airflow/models.py", line 1492, in _run_raw_task
result = task_copy.execute(context=context)
File "/usr/local/lib/python2.7/site-packages/airflow/contrib/operators/kubernetes_pod_operator.py", line 123, in execute
raise AirflowException('Pod Launching failed: {error}'.format(error=ex))
airflow.exceptions.AirflowException: Pod Launching failed: Pod took too long to start
Os tempos limite do pod também podem ocorrer quando a conta de serviço do Cloud Composer não tiver as permissões necessárias do IAM para executar a tarefa em questão. Para verificar isso, analise os erros no nível do pod usando os painéis do GKE para analisar os registros de uma carga de trabalho específica ou use o Cloud Logging.
Falha ao estabelecer uma nova conexão
O upgrade automático é ativado por padrão nos clusters do GKE. Se um pool de nós estiver em um cluster que está fazendo um upgrade, você poderá receber este erro:
<Task(KubernetesPodOperator): gke-upgrade> Failed to establish a new
connection: [Errno 111] Connection refused
Para verificar se o upgrade do cluster está sendo feito, no console do Google Cloud, acesse a página de clusters do Kubernetes e procure o ícone de carregamento ao lado do nome do cluster do ambiente.