Cloud Composer 3 | Cloud Composer 2 | Cloud Composer 1
Cette page explique comment utiliser l'opérateur DataflowTemplateOperator pour lancer des pipelines Dataflow à partir de Cloud Composer.
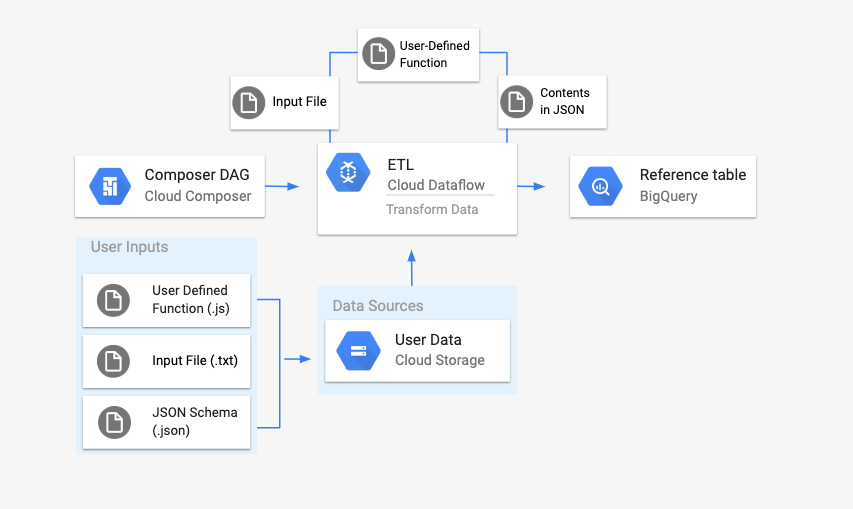
Le pipeline Texte Cloud Storage vers BigQuery est un pipeline par lot qui vous permet d'importer des fichiers texte stockés dans Cloud Storage, de les transformer à l'aide d'une fonction JavaScript définie par l'utilisateur (UDF) et de générer les résultats dans BigQuery.
Présentation
Avant de lancer le workflow, vous devez créer les entités suivantes:
Une table BigQuery vide à partir d'un ensemble de données vide qui contient les colonnes d'informations suivantes :
location,average_temperature,monthet, éventuellement,inches_of_rain,is_currentetlatest_measurement.Un fichier JSON qui normalise les données du fichier
.txtau format approprié pour le schéma de la table BigQuery. L'objet JSON comporte un tableau deBigQuery Schema, où chaque objet contient un nom de colonne, un type d'entrée et l'indication de champ obligatoire ou pas.Fichier
.txtd'entrée contenant les données qui seront importées par lot dans la table BigQuery.Une fonction définie par l'utilisateur écrite en JavaScript qui transforme chaque ligne du fichier
.txten variables pertinentes pour notre table.Un fichier DAG Airflow qui pointe vers l'emplacement de ces fichiers.
Vous allez ensuite importer le fichier
.txt, le fichier de fonction définie par l'utilisateur.jset le fichier de schéma.jsondans un bucket Cloud Storage. Vous importerez également le DAG dans votre environnement Cloud Composer.Une fois le DAG importé, Airflow exécute une tâche à partir de celui-ci. Cette tâche lance un pipeline Dataflow qui applique la fonction définie par l'utilisateur au fichier
.txtet la met en forme en fonction du schéma JSON.Enfin, les données sont importées dans la table BigQuery que vous avez créée précédemment.
Avant de commencer
- Ce guide nécessite une bonne connaissance de JavaScript pour écrire la fonction définie par l'utilisateur.
- Ce guide suppose que vous disposez déjà d'un environnement Cloud Composer. Consultez Créer un environnement pour en créer un. Vous pouvez utiliser n'importe quelle version de Cloud Composer avec ce guide.
-
Enable the Cloud Composer, Dataflow, Cloud Storage, BigQuery APIs.
Créer une table BigQuery vide avec une définition de schéma
Créez une table BigQuery avec une définition de schéma. Vous utiliserez cette définition de schéma plus loin dans ce guide. Cette table BigQuery contiendra les résultats de l'importation groupée.
Pour créer une table vide avec une définition de schéma :
Console
Dans la console Google Cloud, accédez à la page BigQuery:
Dans le panneau de navigation, dans la section Ressources, développez votre projet.
Dans le panneau des détails, cliquez sur Create dataset (Créer un ensemble de données).
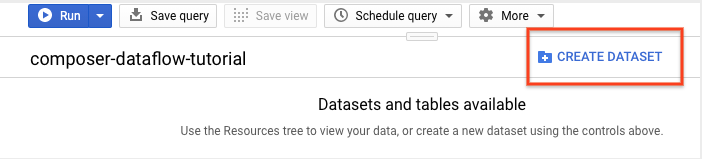
Sur la page "Create dataset" (Créer un ensemble de données), dans la section Dataset ID (ID de l'ensemble de données), nommez l'ensemble de données
average_weather. Conservez les paramètres par défaut pour tous les autres champs.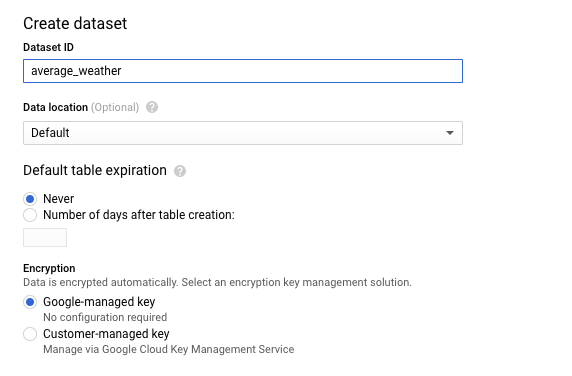
Cliquez sur Créer un ensemble de données.
Revenez au panneau de navigation, puis, dans la section Ressources, développez votre projet. Cliquez ensuite sur l'ensemble de données
average_weather.Dans le panneau de détails, cliquez sur Create table (Créer une table).
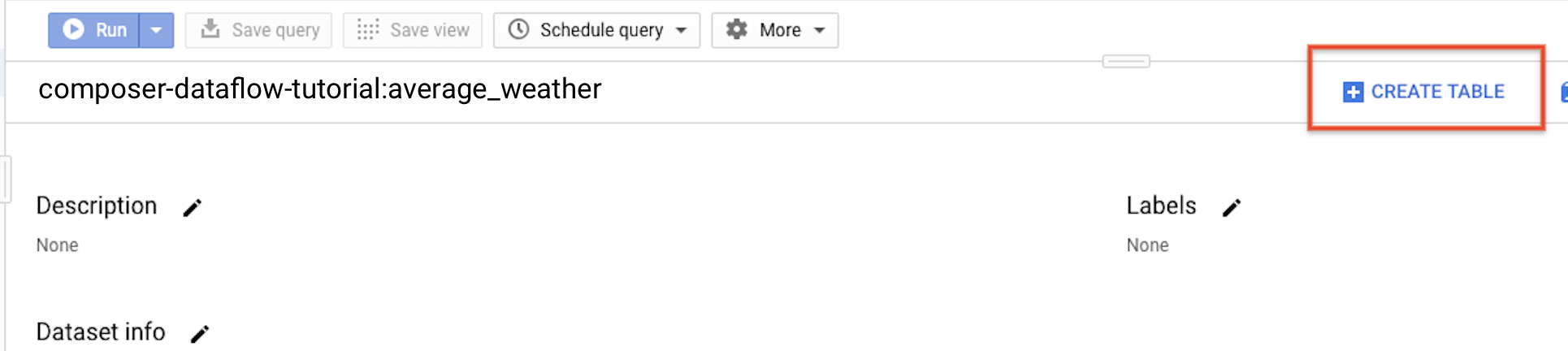
Dans la section Source de la page Créer une table, sélectionnez Table vide.
Dans la section Destination de la page Créer une table :
Dans le champ Dataset name (Nom de l'ensemble de données), sélectionnez l'ensemble de données
average_weather.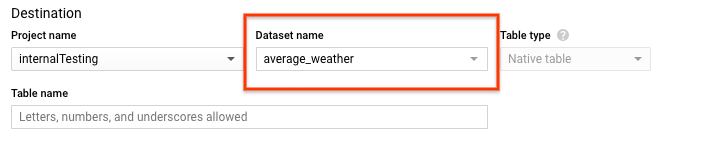
Dans le champ Table name (Nom de la table), saisissez le nom
average_weather.Vérifiez que Type de table est défini sur Table native.
Dans la section Schema (Schéma), saisissez la définition du schéma. Vous pouvez utiliser l'une des approches suivantes:
Saisissez manuellement les informations de schéma en activant Modifier sous forme de texte et en saisissant le schéma de la table sous forme de tableau JSON. Saisissez les champs suivants:
[ { "name": "location", "type": "GEOGRAPHY", "mode": "REQUIRED" }, { "name": "average_temperature", "type": "INTEGER", "mode": "REQUIRED" }, { "name": "month", "type": "STRING", "mode": "REQUIRED" }, { "name": "inches_of_rain", "type": "NUMERIC" }, { "name": "is_current", "type": "BOOLEAN" }, { "name": "latest_measurement", "type": "DATE" } ]Utilisez l'option Ajouter un champ pour saisir manuellement le schéma:
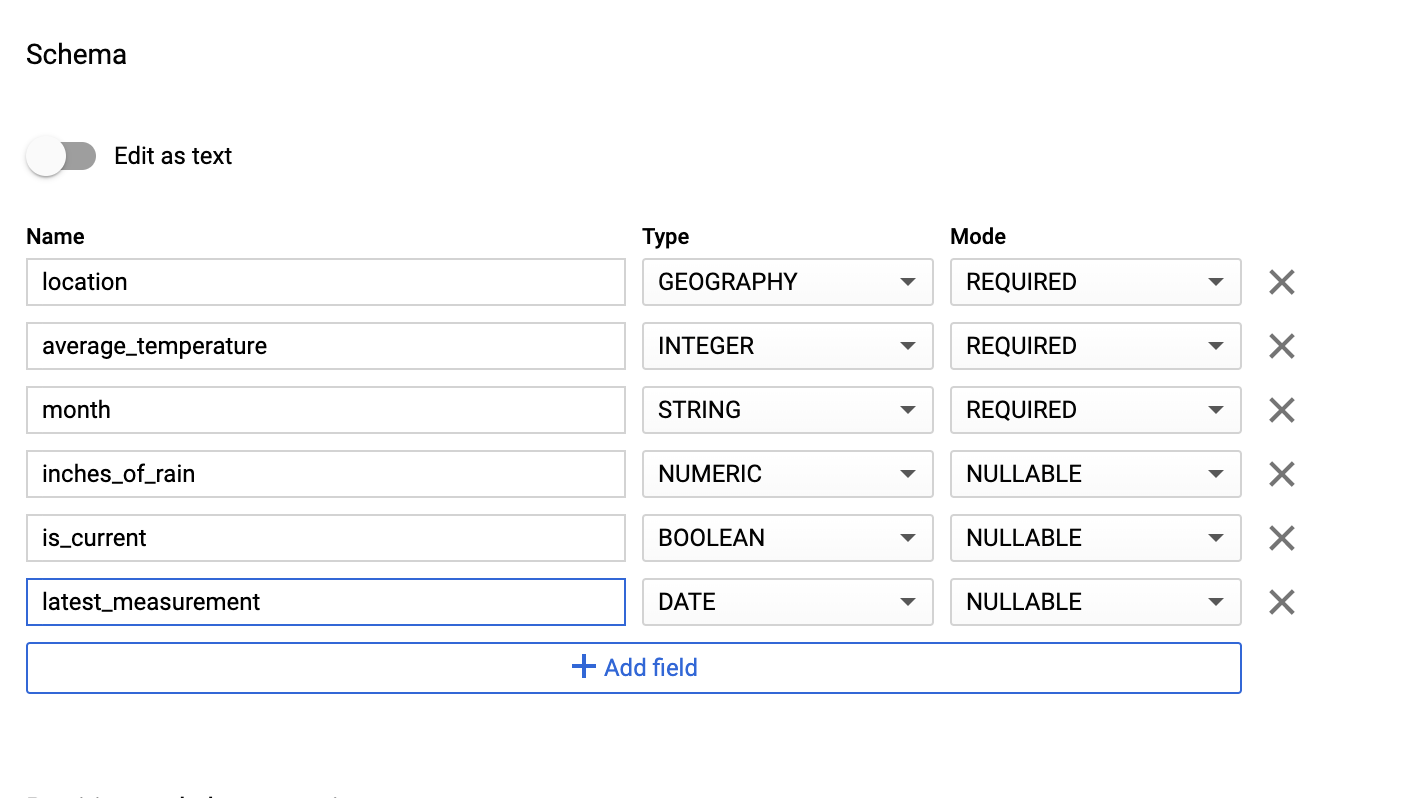
Sous Paramètres de partitionnement et de clustering, conservez la valeur par défaut,
No partitioning.Dans la section Options avancées, pour Chiffrement, conservez la valeur par défaut,
Google-owned and managed key.Cliquez sur Créer une table.
bq
Utilisez la commande bq mk pour créer un ensemble de données vide et une table dans cet ensemble de données.
Exécutez la commande suivante pour créer un ensemble de données des valeurs météo moyennes mondiales:
bq --location=LOCATION mk \
--dataset PROJECT_ID:average_weather
Remplacez les éléments suivants :
LOCATION: région où se trouve l'environnement.PROJECT_ID: ID du projet.
Exécutez la commande suivante pour créer une table vide dans cet ensemble de données avec la définition de schéma:
bq mk --table \
PROJECT_ID:average_weather.average_weather \
location:GEOGRAPHY,average_temperature:INTEGER,month:STRING,inches_of_rain:NUMERIC,is_current:BOOLEAN,latest_measurement:DATE
Une fois la table créée, vous pouvez mettre à jour son délai d'expiration, sa description et ses libellés. Vous pouvez également modifier la définition du schéma.
Python
Enregistrez ce code sous dataflowtemplateoperator_create_dataset_and_table_helper.py et mettez à jour les variables pour correspondre à votre projet et à votre emplacement, puis exécutez le fichier à l'aide de la commande suivante:
python dataflowtemplateoperator_create_dataset_and_table_helper.py
Python
Pour vous authentifier auprès de Cloud Composer, configurez les identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Créer un bucket Cloud Storage
Créez un bucket pour stocker tous les fichiers nécessaires au workflow. Le DAG que vous créerez plus loin dans ce guide référencera les fichiers que vous importerez dans ce bucket de stockage. Pour créer un bucket de stockage, procédez comme suit :
Console
Ouvrez Cloud Storage dans la console Google Cloud.
Cliquez sur Créer un bucket pour ouvrir le formulaire de création de bucket.
Saisissez les informations concernant votre bucket et cliquez sur Continuer à chaque étape :
Spécifiez un nom encore jamais utilisé pour votre bucket. Ce guide utilise
bucketNamecomme exemple.Sélectionnez Régional comme type d'emplacement. Ensuite, sélectionnez l'emplacement où les données du bucket seront stockées.
Sélectionnez Standard comme classe de stockage par défaut pour vos données.
Sélectionnez Uniforme pour le contrôle d'accès à vos objets.
Cliquez sur OK.
gcloud
Exécutez la commande gcloud storage buckets create :
gcloud storage buckets create gs://bucketName/
Remplacez les éléments suivants :
bucketName: nom du bucket que vous avez créé précédemment dans ce guide.
Exemples de code
C#
Pour vous authentifier auprès de Cloud Composer, configurez les identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Go
Pour vous authentifier auprès de Cloud Composer, configurez les identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Java
Pour vous authentifier auprès de Cloud Composer, configurez les identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Python
Pour vous authentifier auprès de Cloud Composer, configurez les identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Ruby
Pour vous authentifier auprès de Cloud Composer, configurez les identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Créer un schéma BigQuery au format JSON pour votre table de sortie
Créez un fichier de schéma BigQuery au format JSON correspondant à la table de sortie que vous avez créée précédemment. Notez que les noms, types et modes des champs doivent correspondre à ceux définis précédemment dans le schéma de votre table BigQuery. Ce fichier normalisera les données de votre fichier .txt dans un format compatible avec votre schéma BigQuery. Nommez ce fichier jsonSchema.json.
{
"BigQuery Schema": [
{
"name": "location",
"type": "GEOGRAPHY",
"mode": "REQUIRED"
},
{
"name": "average_temperature",
"type": "INTEGER",
"mode": "REQUIRED"
},
{
"name": "month",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "inches_of_rain",
"type": "NUMERIC"
},
{
"name": "is_current",
"type": "BOOLEAN"
},
{
"name": "latest_measurement",
"type": "DATE"
}]
}
Créer un fichier JavaScript pour mettre en forme vos données
Dans ce fichier, vous définirez votre fonction définie par l'utilisateur qui fournit la logique permettant de transformer les lignes de texte de votre fichier d'entrée. Notez que cette fonction prend chaque ligne de texte de votre fichier d'entrée comme son propre argument. Par conséquent, elle s'exécute une fois pour chaque ligne de votre fichier d'entrée. Nommez ce fichier transformCSVtoJSON.js.
Créer votre fichier d'entrée
Ce fichier contiendra les informations que vous souhaitez importer dans votre table BigQuery. Copiez ce fichier localement et nommez-le inputFile.txt.
POINT(40.7128 74.006),45,'July',null,true,2020-02-16
POINT(41.8781 87.6298),23,'October',13,false,2015-02-13
POINT(48.8566 2.3522),80,'December',null,true,null
POINT(6.5244 3.3792),15,'March',14,true,null
Importer vos fichiers dans votre bucket
Importez les fichiers suivants dans le bucket Cloud Storage que vous avez créé précédemment:
- Schéma BigQuery au format JSON (
.json) - Fonction définie par l'utilisateur JavaScript (
transformCSVtoJSON.js) Fichier d'entrée du texte à traiter (
.txt)
Console
- Dans la console Google Cloud, accédez à la page Buckets Cloud Storage.
Dans la liste des buckets, cliquez sur le vôtre.
Dans l'onglet Objets du bucket, effectuez l'une des opérations suivantes:
Effectuez un glisser-déposer des fichiers souhaités depuis votre bureau ou votre gestionnaire de fichiers vers le volet principal de la console Google Cloud.
Cliquez sur le bouton Importer des fichiers, sélectionnez les fichiers que vous souhaitez importer dans la boîte de dialogue qui s'affiche, puis cliquez sur Ouvrir.
gcloud
Exécutez la commande gcloud storage cp :
gcloud storage cp OBJECT_LOCATION gs://bucketName
Remplacez les éléments suivants :
bucketName: nom du bucket que vous avez créé précédemment dans ce guide.OBJECT_LOCATION: chemin d'accès local à votre objet. Exemple :Desktop/transformCSVtoJSON.js.
Exemples de code
Python
Pour vous authentifier auprès de Cloud Composer, configurez les identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Ruby
Pour vous authentifier auprès de Cloud Composer, configurez les identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Configurer DataflowTemplateOperator
Avant d'exécuter le DAG, définissez les variables Airflow suivantes.
| Variable Airflow | Valeur |
|---|---|
project_id
|
ID du projet |
gce_zone
|
Zone Compute Engine dans laquelle le cluster Dataflow doit être créé |
bucket_path
|
Emplacement du bucket Cloud Storage que vous avez créé précédemment |
Vous allez maintenant référencer les fichiers que vous avez créés précédemment pour créer un DAG qui lance le workflow Dataflow. Copiez ce DAG et enregistrez-le localement sous le nom composer-dataflow-dag.py.
Airflow 2
Airflow 1
Importer le DAG dans Cloud Storage
Importez votre DAG dans le dossier /dags du bucket de votre environnement. Une fois l'importation terminée, vous pouvez le voir en cliquant sur le lien Dossier DAGS sur la page Environnements Cloud Composer.
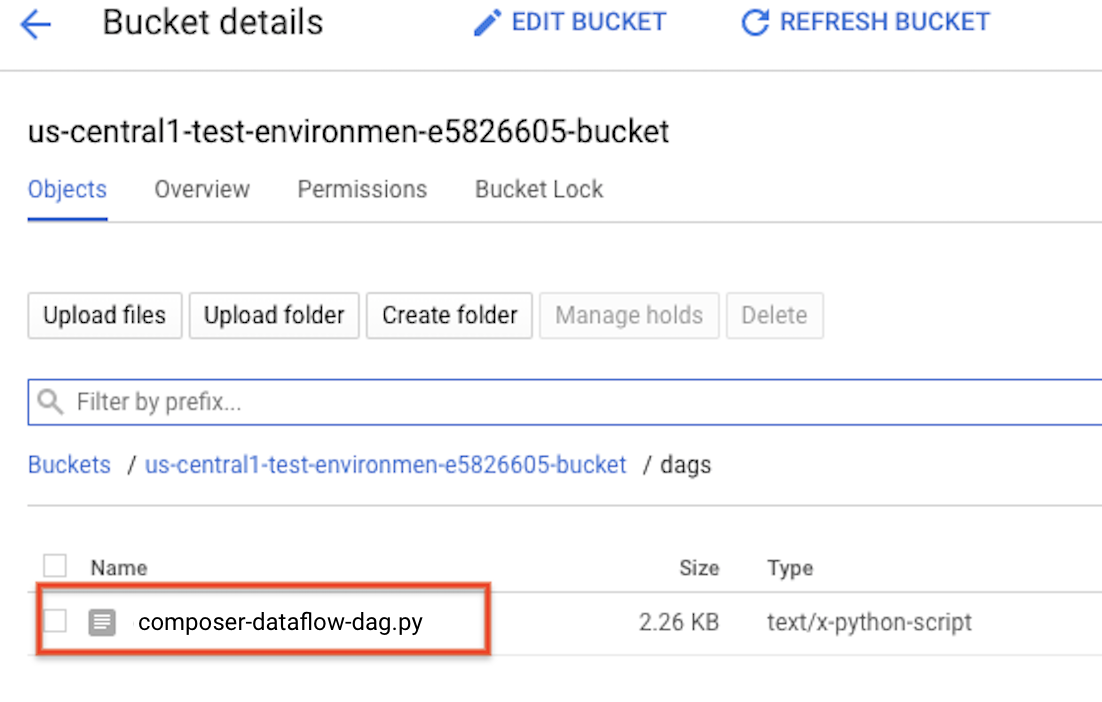
Afficher l'état de la tâche
- Accédez à l'interface Web d'Airflow.
- Sur la page des DAG, cliquez sur le nom du DAG (par exemple,
composerDataflowDAG). - Sur la page "Détails des DAG", cliquez sur Graph View (Vue graphique).
Vérifiez l'état :
Failed: la tâche apparaît dans un encadré rouge. Vous pouvez également placer le pointeur sur la tâche pour voir s'afficher la mention (État: Échec).Success: la tâche apparaît dans un encadré vert. Vous pouvez également placer le pointeur sur la tâche pour voir s'afficher la mention (État: Réussite).
Après quelques minutes, vous pouvez consulter les résultats dans Dataflow et BigQuery.
Afficher votre tâche dans Dataflow
Dans la console Google Cloud, accédez à la page Dataflow.
Votre tâche est nommée
dataflow_operator_transform_csv_to_bqavec un ID unique rattaché à la fin du nom par un tiret, comme ceci:
Cliquez sur le nom pour afficher les détails de la tâche.
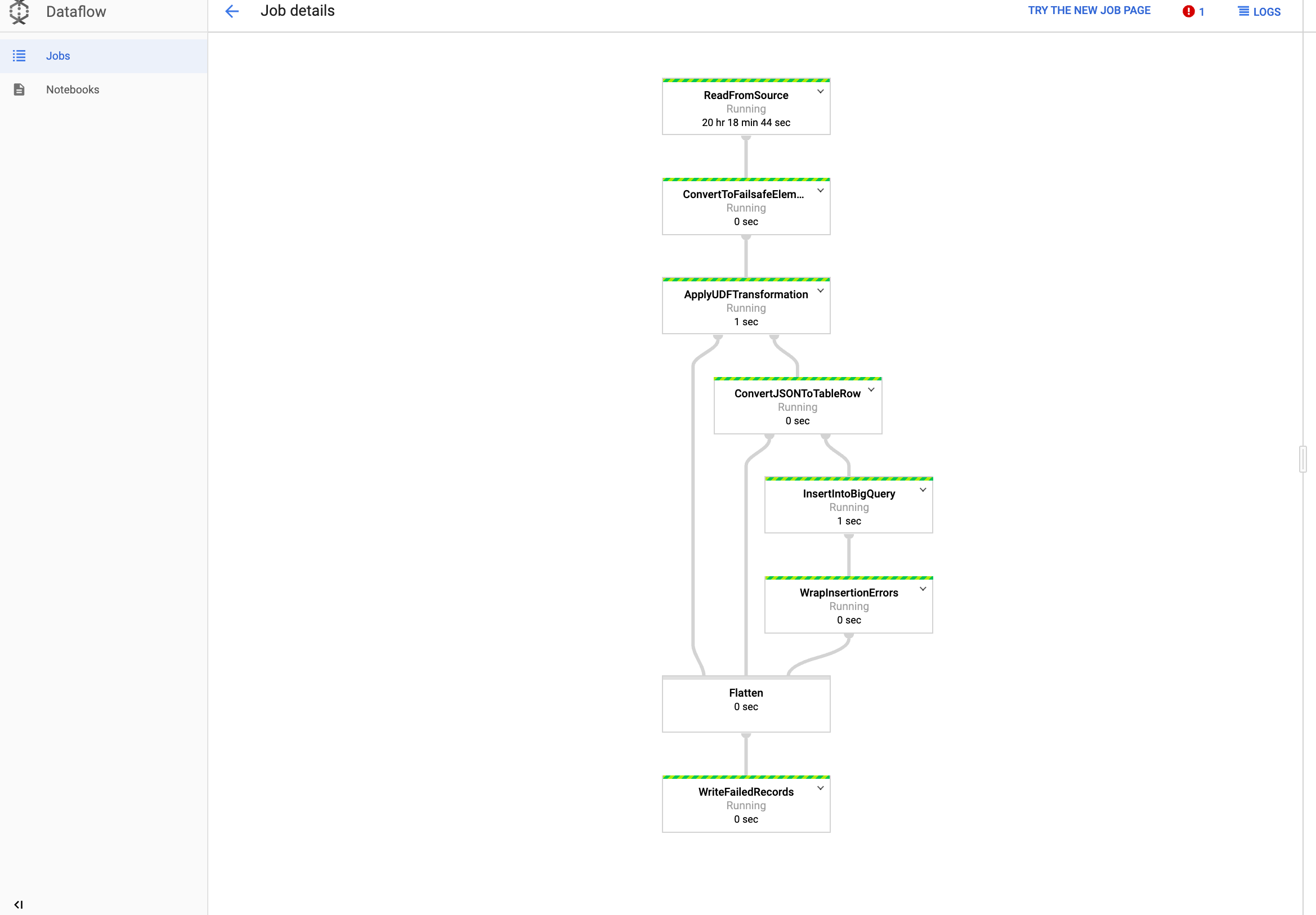
Afficher vos résultats dans BigQuery
Dans la console Google Cloud, accédez à la page BigQuery.
Vous pouvez envoyer des requêtes à l'aide du langage SQL standard. Exécutez la requête suivante pour afficher les lignes qui ont été ajoutées à votre table :
SELECT * FROM projectId.average_weather.average_weather