Cloud Composer 3 | Cloud Composer 2 | Cloud Composer�
本教學課程說明如何使用 Cloud Composer 建立 Apache Airflow DAG (有向無環圖),在 Dataproc 叢集上執行 Apache Hadoop 字數統計工作。
目標
- 存取 Cloud Composer 環境並使用 Airflow UI。
- 建立及查看 Airflow 環境變數。
- 建立並執行包含下列工作的 DAG:
- 建立 Dataproc 叢集。
- 在叢集上執行 Apache Hadoop 字數計算工作。
- 將字數統計結果輸出至 Cloud Storage bucket。
- 刪除叢集。
費用
在本文件中,您會使用下列 Google Cloud的計費元件:
- Cloud Composer
- Dataproc
- Cloud Storage
如要根據預測用量估算費用,請使用 Pricing Calculator。
事前準備
請確認專案已啟用下列 API:
主控台
Enable the Dataproc, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.gcloud
Enable the Dataproc, Cloud Storage APIs:
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.gcloud services enable dataproc.googleapis.com
storage-component.googleapis.com 在專案中建立 Cloud Storage bucket,儲存類別和區域不限,用來儲存 Hadoop 字數統計工作的結果。
請記下您建立的值區路徑,例如
gs://example-bucket。您將為這個路徑定義 Airflow 變數,並在本教學課程稍後的範例 DAG 中使用該變數。建立 Cloud Composer 環境,並使用預設參數。等待環境建立完成。完成後,環境名稱左側會顯示綠色勾號。
請記下您建立環境的區域,例如
us-central。您將為這個地區定義 Airflow 變數,並在範例 DAG 中使用該變數,在同一個地區執行 Dataproc 叢集。
設定 Airflow 變數
設定 Airflow 變數,供範例 DAG 後續使用。舉例來說,您可以在 Airflow UI 中設定 Airflow 變數。
| Airflow 變數 | 值 |
|---|---|
gcp_project
|
您在本教學課程中使用的專案專案 ID,例如 example-project。 |
gcs_bucket
|
您為本教學課程建立的 URI Cloud Storage bucket,例如 gs://example-bucket |
gce_region
|
建立環境的地區,例如 us-central1。
這是要建立 Dataproc 叢集的區域。 |
查看範例工作流程
Airflow DAG 是您要排定及執行的有組織工作集合。DAG 定義於標準 Python 檔案中,hadoop_tutorial.py 中的程式碼是工作流程的程式碼。
運算子
為了自動化調度管理範例工作流程中的三項工作,DAG 會匯入下列三項 Airflow 運算子:
DataprocClusterCreateOperator:建立 Dataproc 叢集。DataProcHadoopOperator:提交 Hadoop 字數統計工作,並將結果寫入 Cloud Storage 值區。DataprocClusterDeleteOperator:刪除叢集,避免產生持續的 Compute Engine 費用。
依附元件
您可依據工作之間的關係和依附元件,安排要執行的工作。這個 DAG 中的工作會依序執行。
排程
DAG 名稱為 composer_hadoop_tutorial,且每天執行一次。由於傳遞至 default_dag_args 的 start_date 設為 yesterday,因此 Cloud Composer 會排定工作流程,在 DAG 上傳至環境的 bucket 後立即啟動。
將 DAG 上傳至環境的 bucket
Cloud Composer 會將 DAG 儲存在環境值區的 /dags 資料夾中。
如要上傳 DAG:
在本機電腦上儲存
hadoop_tutorial.py。前往 Google Cloud 控制台的「Environments」頁面。
在環境清單中,按一下環境的「DAGs folder」欄位中的「DAGs」連結。
按一下「上傳」檔案。
選取本機上的
hadoop_tutorial.py,然後按一下「開啟」。
Cloud Composer 會將 DAG 新增至 Airflow,並自動排定 DAG 的執行時間。DAG 會在 3 到 5 分鐘內產生變化。
探索 DAG 執行作業
查看工作狀態
將 DAG 檔案上傳到 Cloud Storage 中的 dags/ 資料夾後,Cloud Composer 會剖析檔案。成功完成後,工作流程名稱會顯示在 DAG 清單中,且工作流程會排入要立即執行的作業佇列。
如要查看工作狀態,請前往 Airflow 網頁介面,然後點選工具列中的「DAGs」。
如要開啟 DAG 詳細資料頁面,請按一下
composer_hadoop_tutorial。此頁面會透過圖形呈現工作流程工作和依附元件。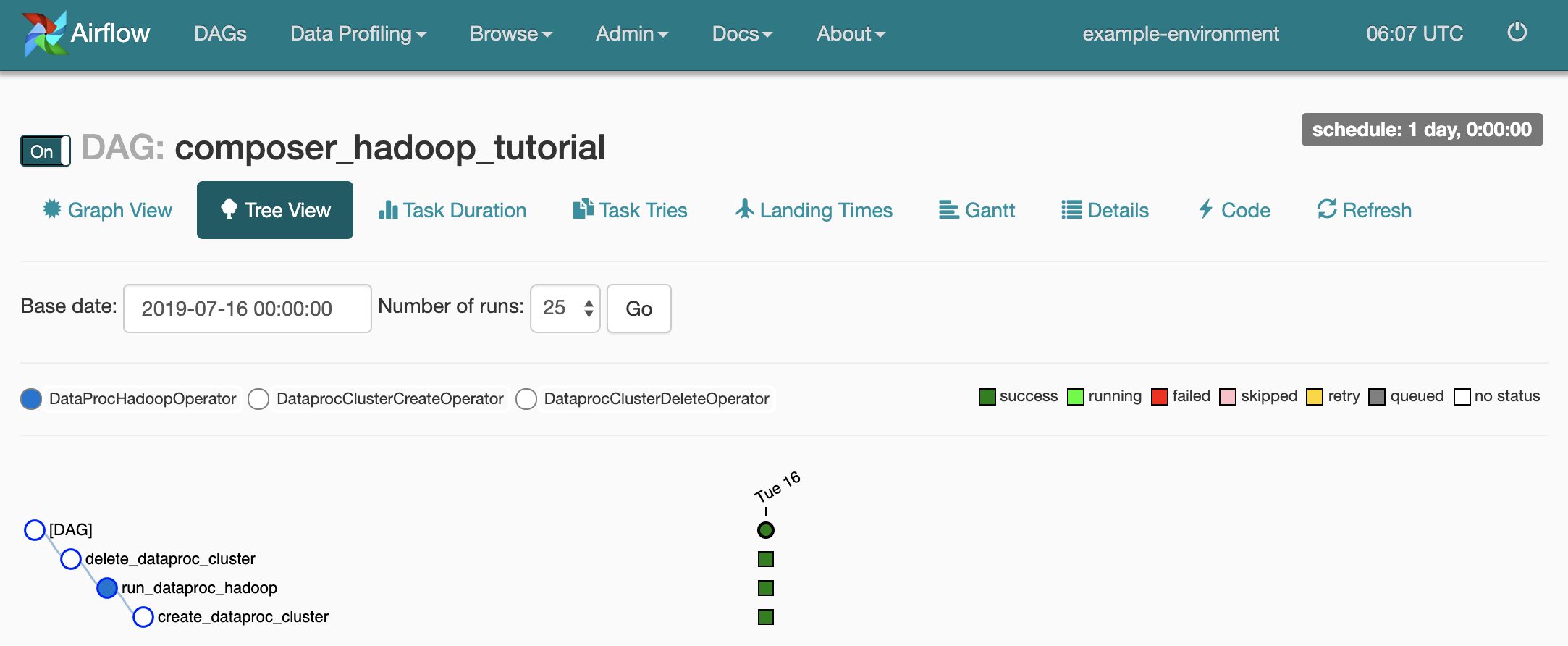
如要查看各項工作的狀態,請按一下「圖表檢視」,然後將滑鼠游標懸停在各項工作的圖表上。
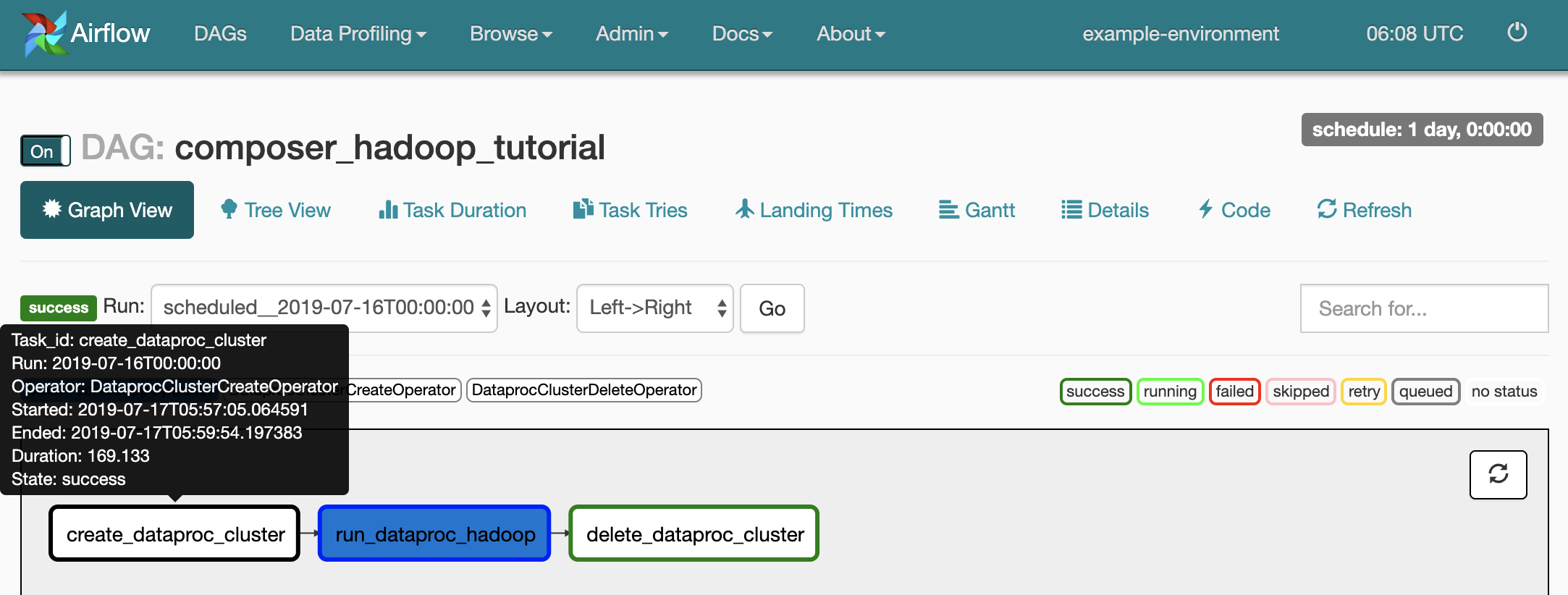
再次將工作流程加入佇列
如要再次從「圖表檢視畫面」執行工作流程:
- 在 Airflow 使用者介面的「圖表」檢視畫面中,按一下
create_dataproc_cluster圖示。 - 如要重設這三項工作,請按一下「清除」,然後按一下「確定」確認。
- 在「圖表」檢視畫面中再次點選
create_dataproc_cluster。 - 如要再次將工作流程排入佇列,請按一下「執行」。
查看工作結果
您也可以前往下列控制台頁面,查看工作流程的狀態和結果:composer_hadoop_tutorial Google Cloud
Dataproc 叢集:監控叢集建立和刪除作業。請注意,工作流程建立的叢集是暫時性的,只會在工作流程執行期間存在,並在最後一個工作流程工作完成後刪除。
Dataproc 工作:查看或監控 Apache Hadoop 字數統計工作。按一下「工作 ID」即可查看工作記錄輸出內容。
Cloud Storage 瀏覽器:查看您為本教學課程建立的 Cloud Storage bucket 中
wordcount資料夾內的字數統計結果。
清除所用資源
刪除本教學課程中使用的資源:
刪除 Cloud Composer 環境,包括手動刪除環境的值區。
刪除 Cloud Storage bucket,其中儲存了 Hadoop 字數統計工作的結果。