Cloud Composer 3 | Cloud Composer 2 | Cloud Composer 1
Questa pagina descrive come utilizzare DataflowTemplateOperator per avviare pipeline Dataflow da Cloud Composer.
La pipeline da testo di Cloud Storage a BigQuery
è una pipeline batch che ti consente di caricare i file di testo archiviati in
Cloud Storage, trasformarli utilizzando una funzione JavaScript definita dall'utente (UDF) fornita
e restituire i risultati in BigQuery.

Panoramica
Prima di avviare il flusso di lavoro, crea le seguenti entità:
Una tabella BigQuery vuota da un set di dati vuoto che conterrà le seguenti colonne di informazioni:
location,average_temperature,monthe, facoltativamente,inches_of_rain,is_currentelatest_measurement.Un file JSON che normalizzerà i dati del file
.txtnel formato corretto per lo schema della tabella BigQuery. L'oggetto JSON avrà un array diBigQuery Schema, dove ogni oggetto conterrà un nome di colonna, il tipo di input e se è un campo obbligatorio.Un file di input
.txtche conterrà i dati che verranno caricati in batch nella tabella BigQuery.Una funzione definita dall'utente scritta in JavaScript che trasformerà ogni riga del file
.txtnelle variabili pertinenti per la nostra tabella.Un file DAG di Airflow che indirizzerà alla posizione di questi file.
Successivamente, caricherai il file
.txt, il file UDF.jse il file dello schema.jsonin un bucket Cloud Storage. Caricherai anche il DAG nell'ambiente Cloud Composer.Dopo il caricamento del DAG, Airflow eseguirà un'attività. Questa attività avvierà una pipeline Dataflow che applicherà la funzione definita dall'utente al file
.txte lo formatterà in base allo schema JSON.Infine, i dati verranno caricati nella tabella BigQuery che hai creato in precedenza.
Prima di iniziare
- Questa guida richiede familiarità con JavaScript per scrivere la funzione definita dall'utente.
- Questa guida presuppone che tu disponga già di un ambiente Cloud Composer. Per crearne uno, vedi Crea ambiente. Puoi utilizzare qualsiasi versione di Cloud Composer con questa guida.
Enable the Cloud Composer, Dataflow, Cloud Storage, BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.Assicurati di disporre delle seguenti autorizzazioni:
- Ruoli Cloud Composer: crea un ambiente (se non ne hai uno), gestisci gli oggetti nel bucket dell'ambiente, esegui i DAG e accedi alla UI di Airflow.
- Ruoli Cloud Storage: crea un bucket e gestisci gli oggetti al suo interno.
- Ruoli BigQuery: crea un set di dati e una tabella, modifica i dati nella tabella, modifica lo schema e i metadati della tabella.
- Ruoli Dataflow: visualizza i job Dataflow.
Assicurati che il account di servizio del tuo ambiente disponga delle autorizzazioni per creare job Dataflow, accedere al bucket Cloud Storage e leggere e aggiornare i dati per la tabella in BigQuery.
Crea una tabella BigQuery vuota con una definizione dello schema
Crea una tabella BigQuery con una definizione dello schema. Utilizzerai questa definizione di schema più avanti in questa guida. Questa tabella BigQuery conterrà i risultati del caricamento batch.
Per creare una tabella vuota con una definizione dello schema:
Console
Nella console Google Cloud , vai alla pagina BigQuery:
Nel pannello di navigazione, espandi il progetto nella sezione Risorse.
Nel riquadro dei dettagli, fai clic su Crea set di dati.
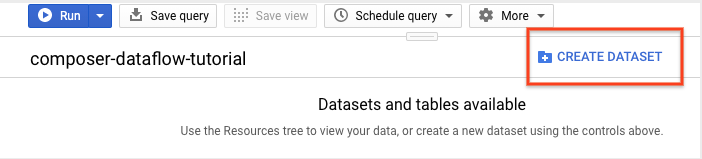
Nella pagina Crea set di dati, nella sezione ID set di dati, assegna un nome al set di dati
average_weather. Lascia invariati tutti gli altri campi.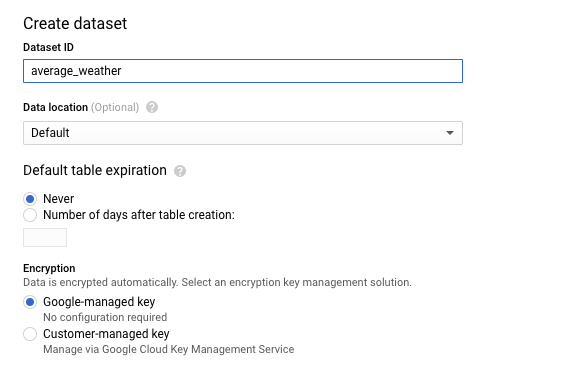
Fai clic su Crea set di dati.
Torna al pannello di navigazione, espandi il progetto nella sezione Risorse. Quindi, fai clic sul set di dati
average_weather.Nel riquadro dei dettagli, fai clic su Crea tabella.
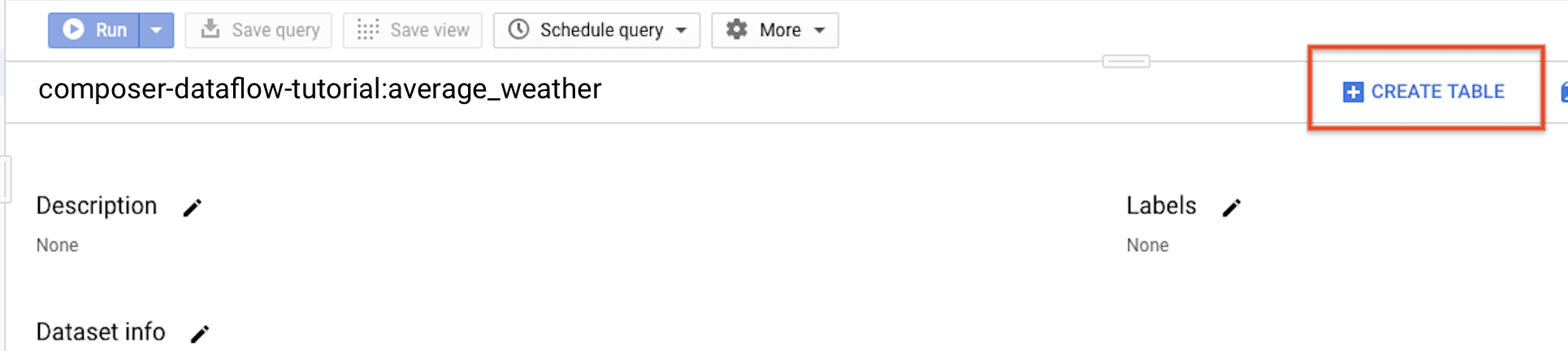
Nella sezione Origine della pagina Crea tabella, seleziona Tabella vuota.
Nella sezione Destinazione della pagina Crea tabella:
Per Nome set di dati, scegli il set di dati
average_weather.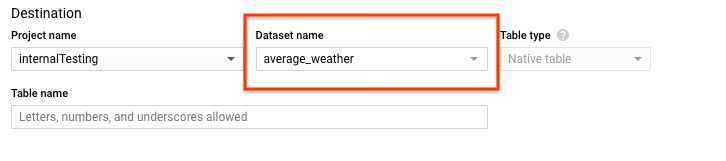
Nel campo Nome tabella, inserisci il nome
average_weather.Verifica che Tipo di tabella sia impostato su Tabella nativa.
Nella sezione Schema, inserisci la definizione dello schema. Puoi utilizzare uno dei seguenti approcci:
Inserisci manualmente le informazioni sullo schema attivando l'opzione Modifica come testo e inserendo lo schema della tabella come array JSON. Digita i seguenti campi:
[ { "name": "location", "type": "GEOGRAPHY", "mode": "REQUIRED" }, { "name": "average_temperature", "type": "INTEGER", "mode": "REQUIRED" }, { "name": "month", "type": "STRING", "mode": "REQUIRED" }, { "name": "inches_of_rain", "type": "NUMERIC" }, { "name": "is_current", "type": "BOOLEAN" }, { "name": "latest_measurement", "type": "DATE" } ]Utilizza Aggiungi campo per inserire manualmente lo schema:
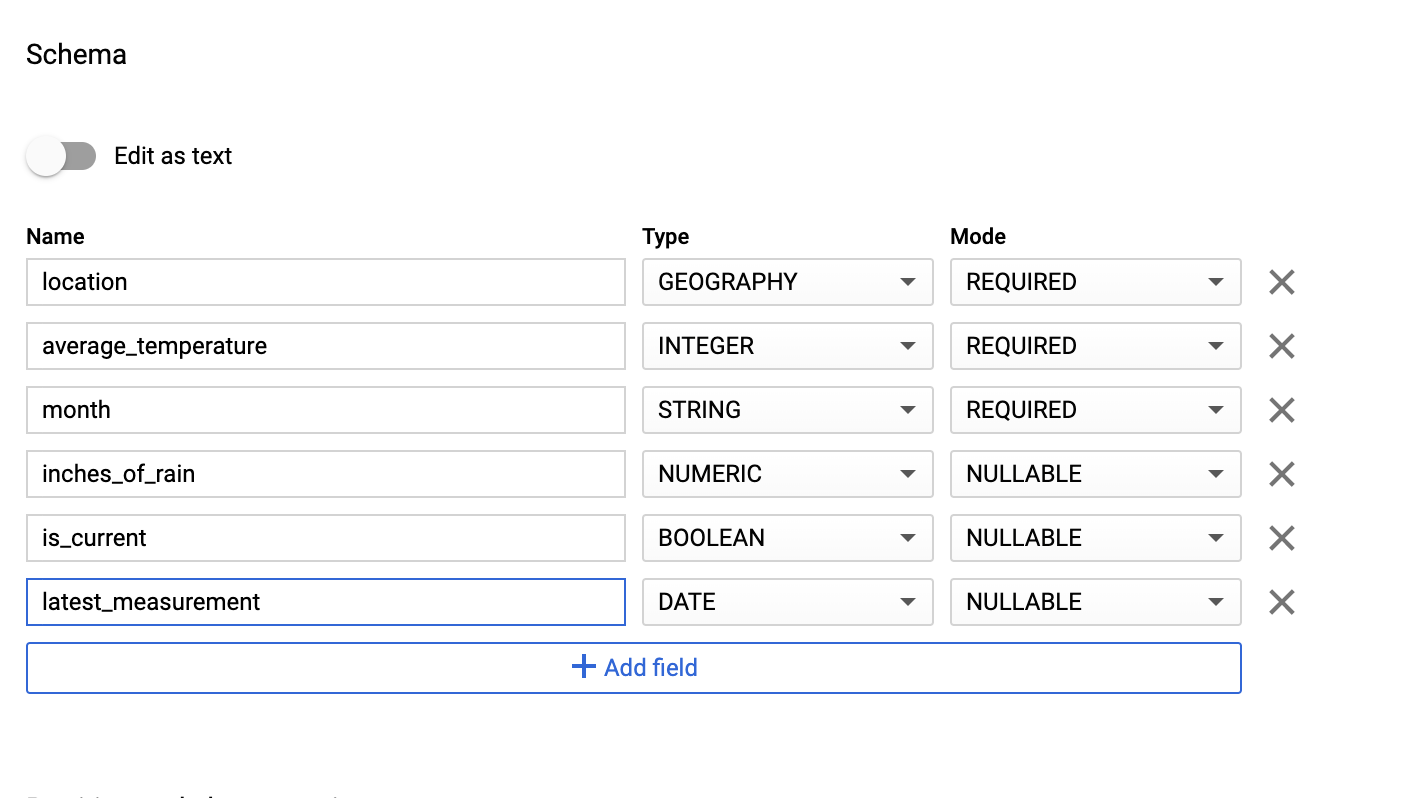
Per Impostazioni di partizionamento e clustering, lascia il valore predefinito
No partitioning.Nella sezione Opzioni avanzate, per Crittografia lascia il valore predefinito,
Google-owned and managed key.Fai clic su Crea tabella.
bq
Utilizza il comando bq mk per creare un set di dati vuoto e una tabella in questo
set di dati.
Esegui questo comando per creare un set di dati delle condizioni meteo medie globali:
bq --location=LOCATION mk \
--dataset PROJECT_ID:average_weather
Sostituisci quanto segue:
LOCATION: la regione in cui si trova l'ambiente.PROJECT_ID: l'ID progetto.
Esegui questo comando per creare una tabella vuota in questo set di dati con la definizione dello schema:
bq mk --table \
PROJECT_ID:average_weather.average_weather \
location:GEOGRAPHY,average_temperature:INTEGER,month:STRING,inches_of_rain:NUMERIC,is_current:BOOLEAN,latest_measurement:DATE
Dopo aver creato la tabella, puoi aggiornare la scadenza, la descrizione e le etichette della tabella. Puoi anche modificare la definizione dello schema.
Python
Salva questo codice come
dataflowtemplateoperator_create_dataset_and_table_helper.py
e aggiorna le variabili al suo interno in modo che riflettano il tuo progetto e la tua posizione, poi
esegui il codice con il seguente comando:
python dataflowtemplateoperator_create_dataset_and_table_helper.py
Python
Per eseguire l'autenticazione in Cloud Composer, configura le Credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
Crea un bucket Cloud Storage
Crea un bucket per contenere tutti i file necessari per il flusso di lavoro. Il DAG che creerai più avanti in questa guida farà riferimento ai file che carichi in questo bucket di archiviazione. Per creare un nuovo bucket di archiviazione:
Console
Apri Cloud Storage nella console Google Cloud .
Fai clic su Crea bucket per aprire il modulo di creazione del bucket.
Inserisci le informazioni sul bucket e fai clic su Continua per completare ogni passaggio:
Specifica un nome univoco a livello globale per il bucket. Questa guida utilizza
bucketNamecome esempio.Seleziona Regione per il tipo di località. Successivamente, seleziona una posizione in cui verranno archiviati i dati del bucket.
Seleziona Standard come classe di archiviazione predefinita per i tuoi dati.
Seleziona controllo dell'accesso Uniforme per accedere ai tuoi oggetti.
Fai clic su Fine.
gcloud
Utilizza il comando gcloud storage buckets create:
gcloud storage buckets create gs://bucketName/
Sostituisci quanto segue:
bucketName: il nome del bucket che hai creato in precedenza in questa guida.
Esempi di codice
C#
Per eseguire l'autenticazione in Cloud Composer, configura le Credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
Go
Per eseguire l'autenticazione in Cloud Composer, configura le Credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
Java
Per eseguire l'autenticazione in Cloud Composer, configura le Credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
Python
Per eseguire l'autenticazione in Cloud Composer, configura le Credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
Ruby
Per eseguire l'autenticazione in Cloud Composer, configura le Credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
Crea uno schema BigQuery in formato JSON per la tabella di output
Crea un file di schema BigQuery in formato JSON che corrisponda alla
tabella di output creata in precedenza. Tieni presente che i nomi, i tipi e le modalità dei campi
devono corrispondere a quelli definiti in precedenza nello schema
della tabella BigQuery. Questo file normalizzerà i dati del file .txt in un formato
compatibile con lo schema BigQuery. Assegna un nome a questo file
jsonSchema.json.
{
"BigQuery Schema": [
{
"name": "location",
"type": "GEOGRAPHY",
"mode": "REQUIRED"
},
{
"name": "average_temperature",
"type": "INTEGER",
"mode": "REQUIRED"
},
{
"name": "month",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "inches_of_rain",
"type": "NUMERIC"
},
{
"name": "is_current",
"type": "BOOLEAN"
},
{
"name": "latest_measurement",
"type": "DATE"
}]
}
Creare un file JavaScript per formattare i dati
In questo file definirai la tua UDF (User Defined Function) che fornisce
la logica per trasformare le righe di testo nel file di input. Tieni presente che questa
funzione considera ogni riga di testo del file di input come un argomento a sé stante, quindi
viene eseguita una volta per ogni riga del file di input. Assegna un nome a questo file
transformCSVtoJSON.js.
Crea il file di input
Questo file conterrà le informazioni che vuoi caricare nella tua
tabella BigQuery. Copia questo file localmente e assegnagli il nome inputFile.txt.
POINT(40.7128 74.006),45,'July',null,true,2020-02-16
POINT(41.8781 87.6298),23,'October',13,false,2015-02-13
POINT(48.8566 2.3522),80,'December',null,true,null
POINT(6.5244 3.3792),15,'March',14,true,null
Carica i file nel bucket
Carica i seguenti file nel bucket Cloud Storage che hai creato in precedenza:
- Schema BigQuery in formato JSON (
.json) - Funzione definita dall'utente JavaScript (
transformCSVtoJSON.js) Il file di input del testo che vuoi elaborare (
.txt)
Console
- Nella console Google Cloud , vai alla pagina Bucket in Cloud Storage.
Nell'elenco dei bucket, fai clic sul tuo bucket.
Nella scheda Oggetti del bucket, esegui una delle seguenti operazioni:
Trascina i file che ti interessano dal desktop o dal file manager nel riquadro principale della console Google Cloud .
Fai clic sul pulsante Carica file, seleziona i file da caricare nella finestra di dialogo visualizzata e fai clic su Apri.
gcloud
Esegui il comando gcloud storage cp:
gcloud storage cp OBJECT_LOCATION gs://bucketName
Sostituisci quanto segue:
bucketName: il nome del bucket che hai creato in precedenza in questa guida.OBJECT_LOCATION: il percorso locale dell'oggetto. Ad esempio,Desktop/transformCSVtoJSON.js.
Esempi di codice
Python
Per eseguire l'autenticazione in Cloud Composer, configura le Credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
Ruby
Per eseguire l'autenticazione in Cloud Composer, configura le Credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
Configura DataflowTemplateOperator
Prima di eseguire il DAG, imposta le seguenti variabili Airflow.
| Variabile Airflow | Valore |
|---|---|
project_id
|
L'ID progetto. Esempio: example-project. |
gce_zone
|
La zona Compute Engine in cui deve essere creato il cluster Dataflow. Esempio: us-central1-a. Per saperne di più sulle zone valide, consulta Regioni e zone. |
bucket_path
|
La posizione del bucket Cloud Storage che hai creato in precedenza. Esempio: gs://example-bucket |
Ora farai riferimento ai file che hai creato in precedenza per creare un DAG che avvii
il flusso di lavoro Dataflow. Copia questo DAG e salvalo localmente
come composer-dataflow-dag.py.
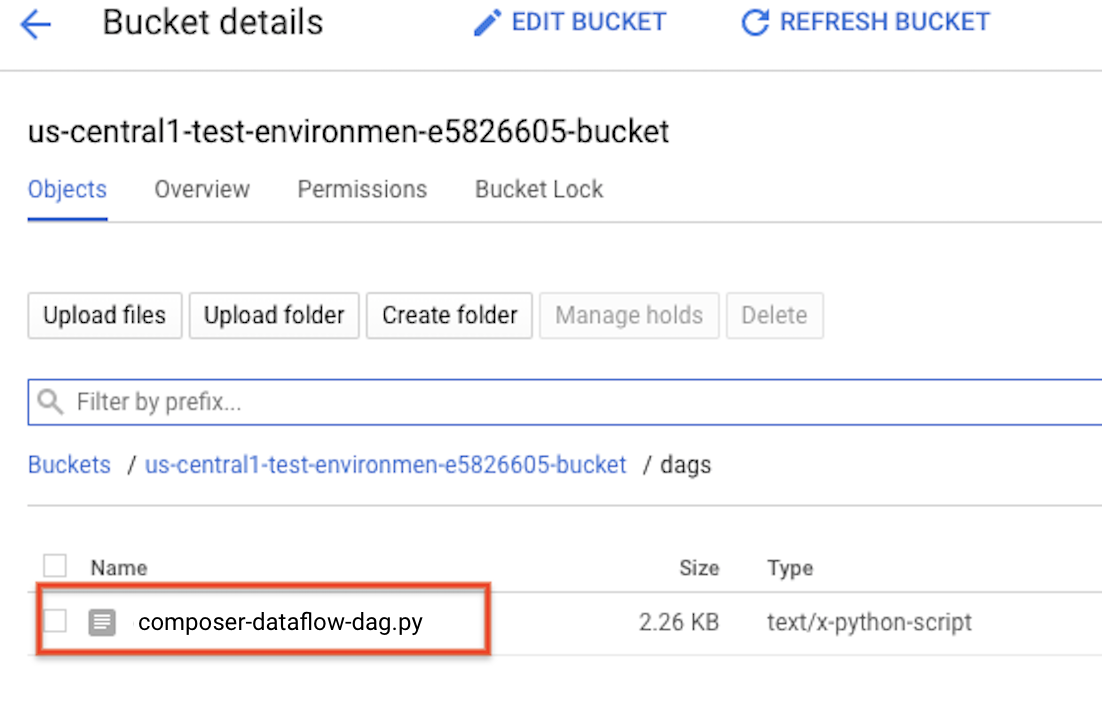
Carica il DAG in Cloud Storage
Carica il DAG nella cartella /dags del bucket dell'ambiente. Una volta completato il caricamento, puoi visualizzarlo
facendo clic sul link Cartella DAG nella pagina
Ambienti Cloud Composer.
Visualizzare lo stato dell'attività
- Vai all'interfaccia web di Airflow.
- Nella pagina DAG, fai clic sul nome del DAG (ad esempio
composerDataflowDAG). - Nella pagina Dettagli DAG, fai clic su Visualizzazione grafico.
Controlla lo stato:
Failed: La casella intorno all'attività è rossa. Puoi anche tenere il puntatore sopra l'attività e cercare Stato: non riuscito.Success: La casella intorno all'attività è verde. Puoi anche passare il puntatore sopra l'attività e verificare Stato: riuscito.
Dopo alcuni minuti, puoi controllare i risultati in Dataflow e BigQuery.
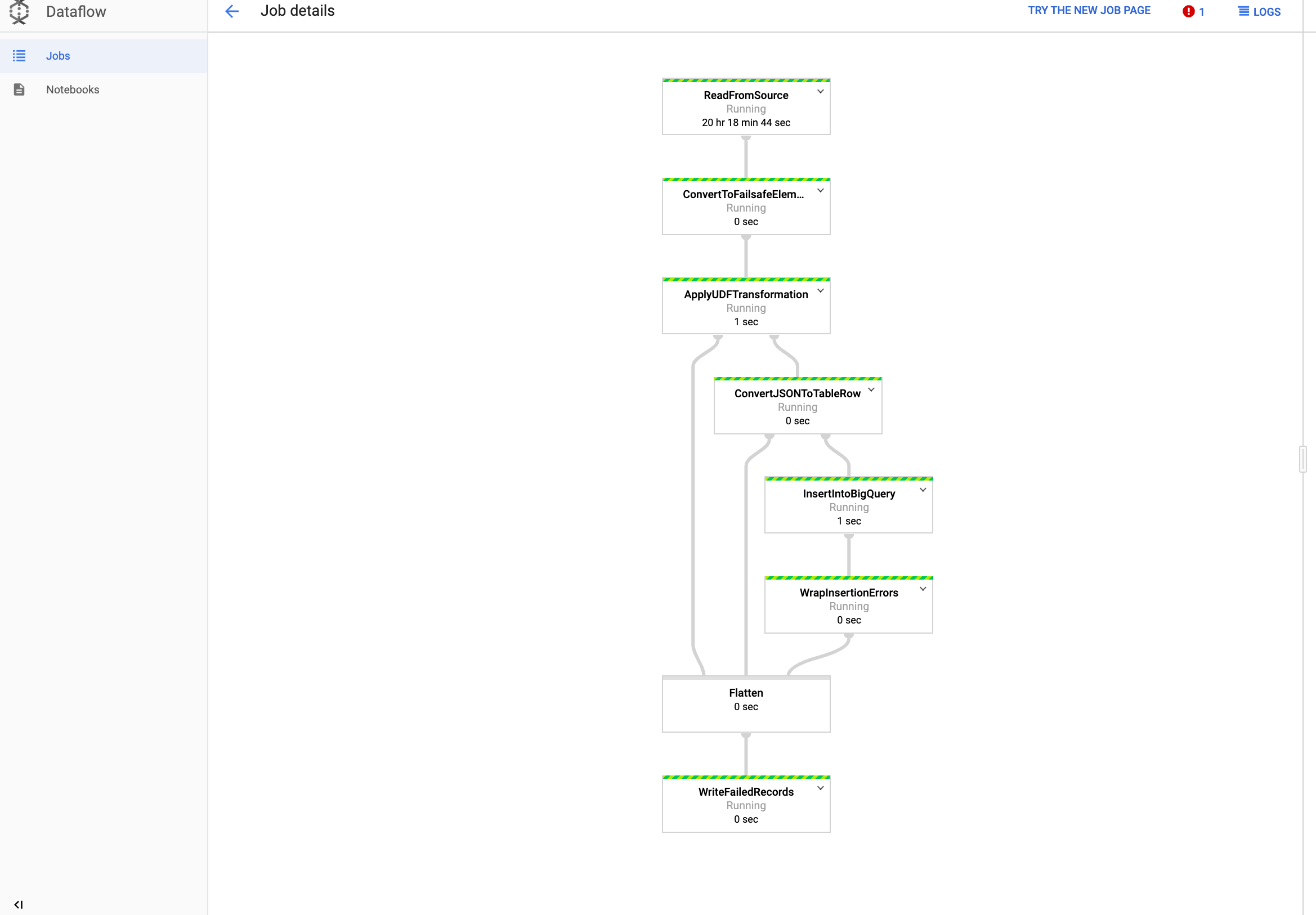
Visualizzare il job in Dataflow
Nella console Google Cloud , vai alla pagina Dataflow.
Il tuo job si chiama
dataflow_operator_transform_csv_to_bqcon un ID univoco allegato alla fine del nome con un trattino, ad esempio:
Fai clic sul nome per visualizzare i dettagli del job.
Visualizza i risultati in BigQuery
Nella console Google Cloud , vai alla pagina BigQuery.
Puoi inviare query utilizzando SQL standard. Utilizza la seguente query per visualizzare le righe aggiunte alla tabella:
SELECT * FROM projectId.average_weather.average_weather