Modernizing financial risk computation with Hitachi Consulting and GCP
Jeremy Tangney
Solutions Architect, Google Cloud
Andrew Harding
Solutions Architect, Insights & Analytics, Hitachi Consulting
Editor’s note: Hitachi Consulting is the digital solutions and professional services organization within Hitachi Ltd., and a strategic partner of Google Cloud. Hitachi Consulting has deep experience in the financial services industry, and they work with many large banks on moving to using digital solutions. Today we’ll hear how they used Google Cloud Platform (GCP) to build a proof-of-concept platform to move traditional financial risk computation tasks from on-premises to cloud, gaining flexibility, scalability and cost savings.
At Hitachi Consulting, we’ve found that GCP’s high-performance infrastructure and big data analysis tools are ideal for financial applications and data. We wanted to explore using GCP to help modernize the financial applications common to many of our banking customers. In this post, we’ll describe our experience building a proof-of-concept market risk computation solution.
Financial services companies need flexible infrastructure
Risk management is a core activity for financial services organizations. These organizations often have extensive hardware and software investments, typically in the form of high-performance computing (HPC) grids, to help with risk computations. Increasing regulation and the need for access to timely risk exposure calculations places great demands on this computing infrastructure. So financial services organizations have to increase the flexibility, scalability and cost-effectiveness of their risk infrastructure and applications to meet this growing demand.
We set out to build a proof-of-concept risk analytics platform that could tackle the downsides of traditional approaches to market risk exposure applications, such as:
- Managing large amounts of compute nodes within an on-premises grid architecture
- Dependency on expensive third-party orchestration software
- Lack of flexibility and scalability to meet growing demand
Modernizing risk applications with cloud-native tools
The cloud presents many opportunities for modernizing risk applications. A traditional lift-and-shift approach, where existing applications are moved to the cloud with minimum modification, can increase scalability and reduce costs. At the other end of the scale, applications can be fully redesigned to use streaming pipeline architectures to help meet demands for results in near real-time. However, we think there’s a place for a middle path that lets financial institutions take advantage of cloud-native services to get cost and flexibility benefits, while continuing to use the risk models they’re used to.
Our approach uses a few key technology components:
- Containers as lightweight alternatives to traditional virtual machines to perform typical Value at Risk (VaR) calculations using the open-source QuantLib libraries
- Google Kubernetes Engine (GKE) as a managed container platform and replacement for the on-premises compute grid
- Cloud Pub/Sub and Cloud Dataflow for orchestration of the risk calculation pipeline
- Cloud Datastore as intermediate storage for checkpointing
- BigQuery for data warehousing and analytics
Here’s a look at how these pieces come together for risk calculation:
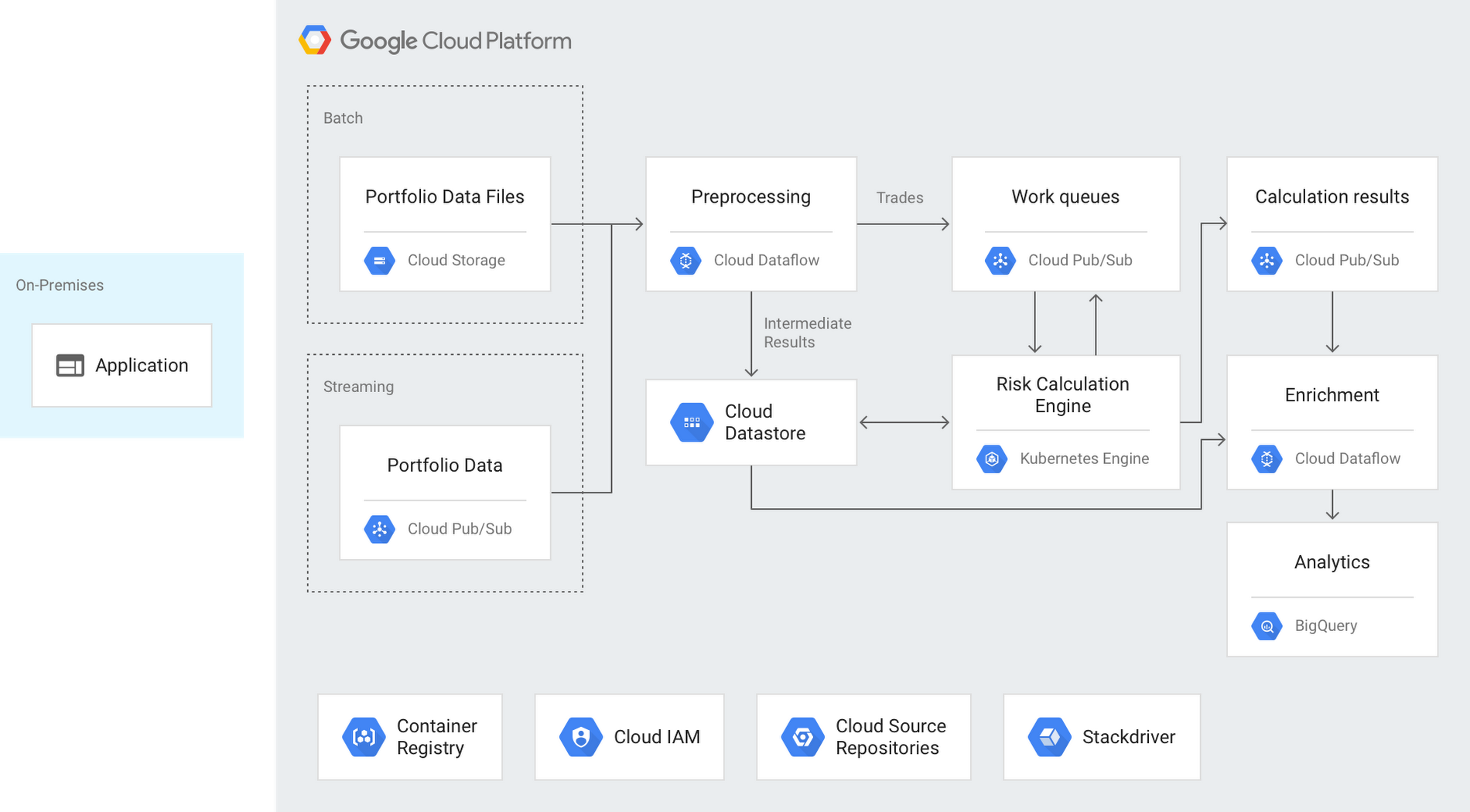
Ingestion
The first step is to ingest data into the pipeline. Here, the inputs take the form of aggregated portfolio and trade data. One key design goal was the ability to handle both batch and stream inputs. In the batch case, CSV files are uploaded to Google Cloud Storage, and the file upload triggers a message onto a Cloud Pub/Sub topic. For the streaming case, information is published directly onto a Cloud Pub/Sub topic. Cloud Pub/Sub is a fully managed service that provides scalable, reliable, at-least-once delivery of messages for event-driven architectures. Cloud Pub/Sub enables loose coupling of application components and supports both push and pull message delivery.
Preprocessing
Those Cloud Pub/Sub messages feed a Cloud Dataflow pipeline for trade data preprocessing. Cloud Dataflow is a fully managed, auto-scaling service for transforming and enriching data in both stream and batch modes, based on open-source Apache Beam. The portfolio inputs are cleansed and split into individual trade elements, at which point the required risk calculations are determined. The individual trade elements are published to downstream Cloud Pub/Sub topics to be consumed by the risk calculation engine.
Intermediate results from the preprocessing steps are persisted to Cloud Datastore, a fully managed, serverless NoSQL document database. This pattern of checkpointing intermediate results to Cloud Datastore is repeated throughout the architecture. We chose Cloud Datastore for its flexibility, as it brings the scalability and availability of a NoSQL database alongside capabilities such as ACID transactions, indexes and SQL-like queries.
Calculation
At the heart of the architecture sits the risk calculation engine, deployed on GKE. GKE is a managed, production-ready environment for deploying containerized applications. We knew we wanted to evaluate GKE, and Kubernetes more broadly, as a platform for risk computation for the following reasons:
- Existing risk models can often be containerized without significant refactoring
- Kubernetes is open source, minimizing vendor lock-in
- Kubernetes abstracts away the underlying compute infrastructure, promoting portability
- Kubernetes provides sophisticated orchestration capabilities, reducing dependency on expensive third-party tools
- GKE is a fully managed service, freeing operations teams to focus on managing applications rather than infrastructure
The risk engine is a set of Kubernetes services designed to handle data enrichment, perform the required calculations, and output results. Pods are independently auto-scaled via Stackdriver metrics on Cloud Pub/Sub queue depths, and the cluster itself is scaled based on the overall CPU load. As in the preprocessing step, intermediate results are persisted to Cloud Datastore and pods publish messages to Cloud Pub/Sub to move data through the pipeline. The pods can run inside a private cluster that is isolated from the internet but can still interact with other GCP services via private Google access.
Output
Final calculation results output by the risk engine are published to a Cloud Pub/Sub topic, which feeds a Cloud Dataflow pipeline. Cloud Dataflow enriches the results with the portfolio and market data used for the calculations, creating full-featured snapshots. These snapshots are persisted to BigQuery, GCP’s serverless, highly scalable enterprise data warehouse. BigQuery allows analysis of the risk exposures at scale, using SQL and industry-standard tooling, driving customer use cases like regulatory reporting.
Lessons learned building a proof-of-concept data platform
We learned some valuable lessons while building out this platform:
- Choosing managed and serverless options greatly improved team velocity
- Be aware of quotas and limits; during testing we encountered BigQuery streaming-insert limits. We worked around that using a blended streaming and micro-batch strategy with Cloud Dataflow.
- We had to do some testing and investigation to get optimum auto-scaling of the Kubernetes pods.
- The system scaled well under load without warm-up or additional configuration
What’s next for our risk solution
We built a modernized, cloud-native risk computation platform that offers several advantages over traditional grid-based architectures. The architecture is largely serverless, using managed services such as Cloud Dataflow, Cloud Pub/Sub and Cloud Datastore. The solution is open-source at its core, using Kubernetes and Apache Beam via GKE and Cloud Dataflow, respectively. BigQuery provides an easy way to store and analyze financial data at scale. The architecture has the ability to handle both batch and stream inputs, and scales up and down to match load.
Using GCP, we addressed some of the key challenges associated with traditional risk approaches, namely inflexibility, high management overhead and reliance on expensive third-party tools. As our VP of financial services, Suranjan Som, put it: “The GCP risk analytics solution provides a scalable, open and cost-efficient platform to meet increasing risk and regulatory requirements.” We’re now planning further work to test the solution at production scale.
Read more about financial services solutions on GCP, and learn about Hitachi Consulting’s financial services solutions.

