How partners are unlocking scalable audio transcription with Gemini
Schneider Larbi
Principal Partner Engineer
Dr. Charlotte Gistelinck
Sr. Partner Engineer
Try Gemini 3.1 Pro
Our most intelligent model available yet for complex tasks on Gemini Enterprise and Vertex AI
Try nowFrom transcribing customer calls and meetings, to analyzing research interviews and creating accessible content, audio transcription plays a vital role in extracting insights from spoken data. Our partners are collaborating with clients across industries to implement transcription solutions that enhance efficiency, accessibility, and data-driven decision-making.
Traditional audio transcription methods, such as manual transcription or basic speech-to-text tools can be time-consuming, error-prone, and expensive. In this blog post, we show how Gemini offers a cutting-edge solution for scalable audio transcription by automating the process and delivering results with high accuracy at a fast pace – all in a cost-effective way.
The challenges of scaling audio transcription
As organizations scale their transcription needs, they might encounter challenges such as increasing costs, latency in handling large volumes of audio, and maintaining accuracy across diverse audio conditions. In particular, legacy solutions struggle with:
-
Handling complex audio with multiple speakers, accents, or background noise.
-
Maintaining accuracy in industry-specific terminology across healthcare, legal, and customer service domains.
-
Adapting to multilingual needs, especially in global business environments.
-
Optimizing processing time and cost, ensuring fast turnaround without excessive resource consumption.
A scalable solution must address these challenges efficiently, without compromising speed, accuracy, or customization — this is where Gemini excels.
How our partners put Gemini to work
Google Cloud Partners leverage audio transcription to help clients across various industries improve efficiency, compliance, and accessibility. Here are some examples:
-
Media and entertainment: Transcribe interviews, podcasts, and webinars for content creation, and generate subtitles to enhance accessibility and engagement.
-
Customer service: Transcribe customer calls in real time for quality assurance, sentiment analysis, and experience optimization. (Also see Conversational Insights within Customer Engagement Suite with Google AI).
-
Legal and Compliance: Transcribe legal proceedings, contracts, and compliance-related communications to improve accuracy, streamline case management, and ensure regulatory adherence.
-
Healthcare: Convert medical dictations and clinical notes into structured records for better documentation, electronic health record (EHR) integration, and regulatory compliance.
-
Business and corporate: Transcribe meetings, interviews, and presentations to improve collaboration, knowledge sharing, and record-keeping.
Gemini redefines the possibilities of scalable audio transcription, offering a potent combination of advanced AI and seamless integration with Google Cloud. Here’s what sets it apart:
-
Efficient processing of large datasets: Gemini can handle large volumes of audio data with ease, making it ideal for organizations with high-throughput transcription needs.
-
Exceptional accuracy and contextual understanding: Backed by decades of Google research and development in speech recognition and natural language understanding, Gemini delivers highly accurate transcriptions that capture the nuances of conversations. This minimizes the need for manual review and correction, especially in cases with multiple speakers, accents, or challenging audio conditions
-
Speaker diarization: Gemini can accurately identify and differentiate between speakers in an audio file, making it easier to follow conversations and attribute dialogue correctly
-
Multilingual support: Gemini supports transcription in multiple languages and dialects, expanding its utility for global businesses and diverse content
-
Customizable formatting: Gemini offers flexible formatting options, allowing users to tailor transcripts to their specific needs, including timestamps, speaker labels, and punctuation.
Introducing a differentiated solution
The Google Cloud Partner Engineering team worked together with System Integrators (SIs) to build a differentiated solution that allows customers to implement audio transcription at scale using Google’s Gemini on Google Cloud.
Gemini’s advanced multi-modal and reasoning capabilities have unlocked new possibilities for audio transcription. This solution allows audio files to be sent directly to Gemini for transcription. The reference architecture below illustrates how this solution is built;
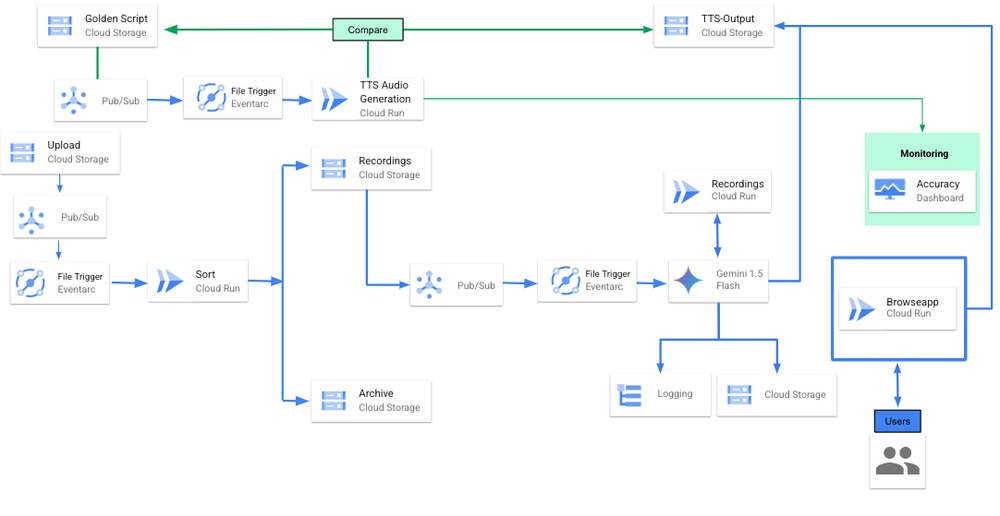
gen AI powered audio transcription reference architecture
This architecture demonstrates a robust and scalable approach to audio transcription using Gemini. It can be modified for any audio transcription use case. Here's how it works:
1. File upload and sorting: The Upload Cloud Storage bucket is used to store source audio files like .wav, .mp3, .mp4, files etc. When these files are uploaded, Eventarc triggers the Sort Cloud Run function. This trigger event is passed using Cloud Pub/Sub.
The Sort Cloud Run function manages incoming files by sorting and filtering them based on their file types (e.g., .wav, .mp3). Depending on the file type, the files are then stored in either the Recordings Cloud Storage bucket or the Archive Cloud Storage bucket.
2. Transcription: When audio files are placed in the Recordings Cloud Storage bucket, Eventarc uses Cloud Pub/Sub to trigger the Recording Cloud Run function. This Recording function then sends the audio files to the Gemini 1.5 Flash LLM model for audio transcription.
3. Gemini's multi-faceted processing: Gemini performs three key tasks:
a. Analysis and formatting: It analyzes the audio file, extracting pertinent data and structuring it into JSON format based on the audio file schema.
b. Transcription and summarization: Gemini transcribes the audio content into text and generates a concise summary.
c. Output and evaluation: The summarized text is sent to a “TTS Output” Cloud Storage bucket, triggering the TTS Audio Generation function. This function executes a script from the “Golden Script” Cloud Storage bucket to generate sample audio, which is then used to evaluate the transcription quality against established metrics like Word Error Rate (WER), Character Error Rate (CER), Match Rate, etc.
This approach provides key benefits: dynamic scaling through a serverless, event-driven architecture (Cloud Run, Eventarc), simplified management via fully managed services (Cloud Storage), cost-effectiveness by consuming resources only when needed, and enhanced capabilities like advanced summarization and speaker diarization powered by Gemini.
Design considerations
When designing audio transcription applications and services on Google Cloud with Gemini, several factors are crucial for optimal performance and scalability:
1. Efficient audio file handling: Avoid loading large audio files directly into memory for serverless transcription on Google Cloud. Instead, use Google Cloud Storage URI to efficiently access and process audio without memory limitations.
2. Serverless function timeouts: To prevent premature termination when processing large audio files in Cloud run, increase the function timeout up to 60 minutes. Also set the Pub/Sub subscription acknowledgement deadline to 300 seconds for Eventarc.
3. Model selection and context window: For gen AI audio transcription, audio file size and duration dictate the model selection. Larger files and longer audio require models with large context windows like Gemini 1.5 Flash (1M tokens) and Gemini 1.5 Pro (2M tokens), overcoming prior LLM input limitations on the market today. The Gemini 1.5's extended context window and near-perfect retrieval capabilities open up many new possibilities;
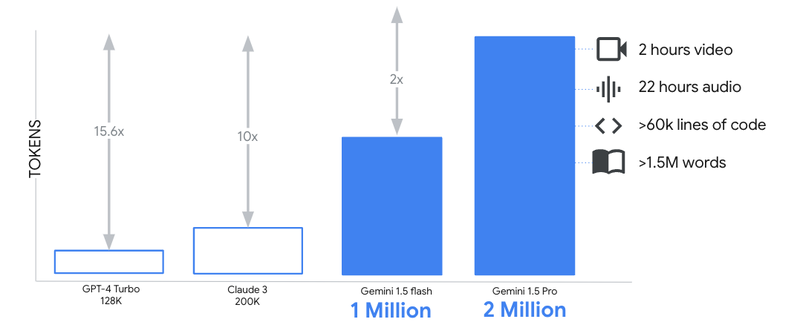
Context lengths of leading foundation models
This shows that for audio transcription use cases, Gemini 1.5 Pro and Flash offer scalable audio transcription, processing up to 22 and 11 hours of audio respectively based on customer needs.
4. Optimizing speaker diarization: To leverage Gemini's built-in speaker diarization capabilities effectively:
a. Use the latest Gemini SDK : Ensure your code utilizes the most up-to-date SDK for optimal diarization performance.
b. Design effective prompts: Craft prompts that clearly instruct Gemini on diarization and formatting requirements. The diagram below shows a code example of a diarization prompt
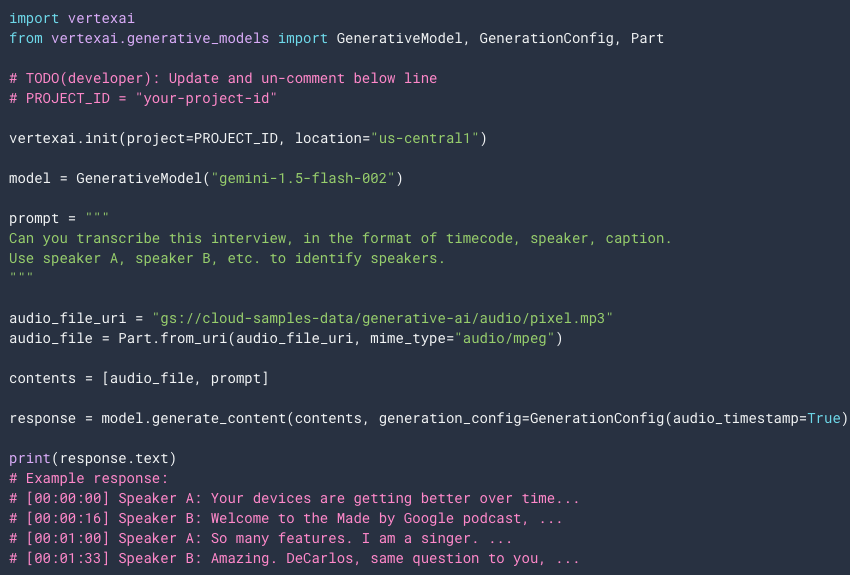
Sample transcription & diarization prompt
This sample code prompts Gemini to transcribe an audio file from Cloud Storage URI and displays the transcription.
5. Advanced diarization techniques: For complex scenarios with multiple speakers, accents, or overlapping speech, design prompts efficiently to improve Gemini’s diarization accuracy. Consider separating diarization and transcription into separate functions, the snippet below shows an example of this;
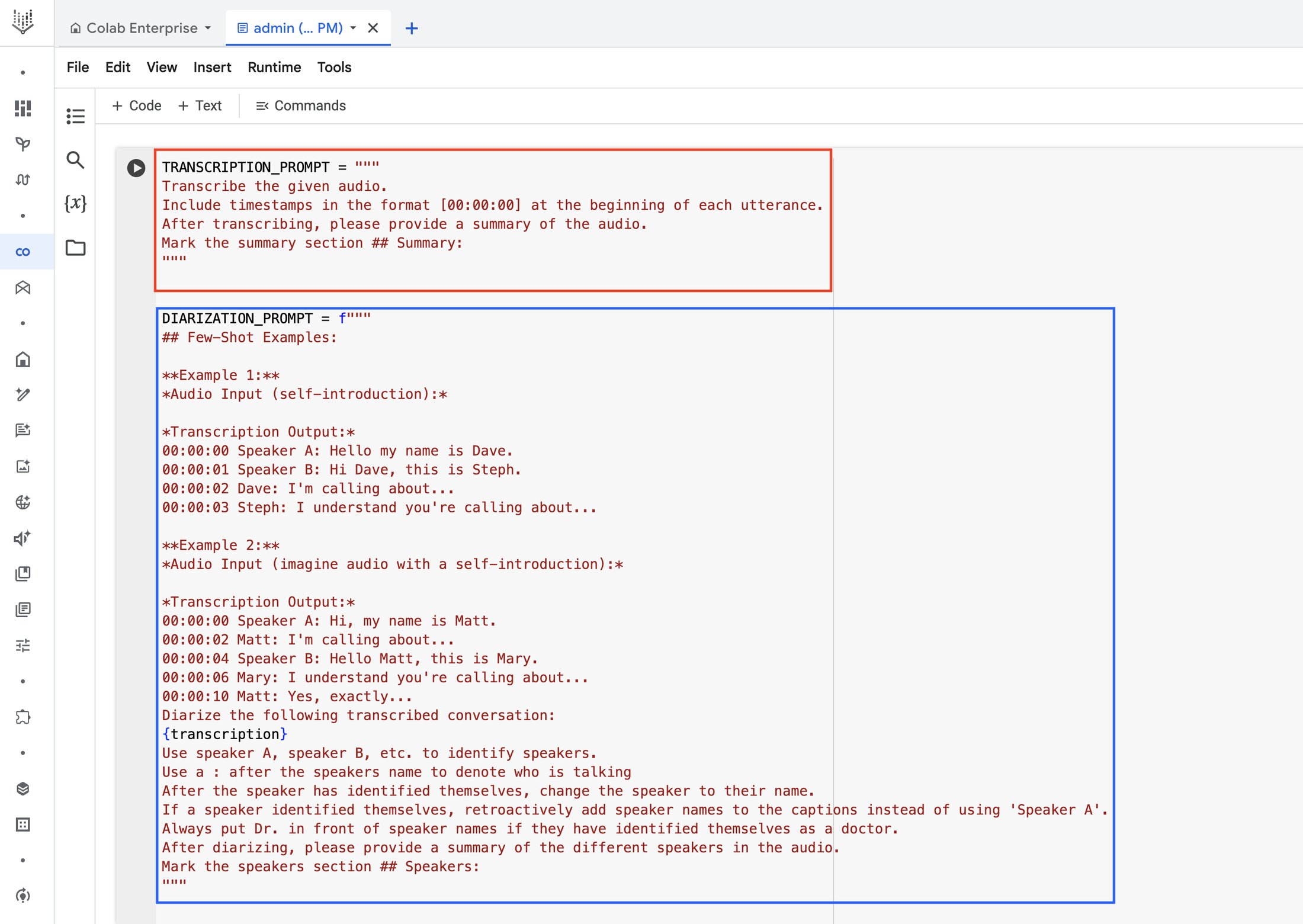
Separate transcription & diarization function
From the screenshot above, the function highlighted in the red box is the prompt that instructs Gemini to transcribe. It also shows how we want the transcription to be formatted. This operation allows Gemini to focus first on transcribing the audio into text and summarizing it.
The transcription function is actually a straightforward function and zero shot prompt. For the diarization function, we recommend you design your prompt with a few short examples. The code block highlighted in blue shows the diarization function with some examples to help the model to diarize effectively and efficiently when there are multiple speakers.
6. Evaluating transcription quality: when building gen AI powered audio transcription systems on Google Cloud we recommend implementing a mechanism to evaluate the transcribed responses to further ensure better accuracy. Consider using tools like our Model Evaluation Service to assess and improve transcription quality.
Get started
Ready to unlock the power of scalable audio transcription with Gemini? Explore Gemini's API documentation and discover how easy it is to integrate its advanced capabilities into your solutions. By implementing the best practices and design considerations discussed in this post, you can deliver exceptional transcription experiences to clients and drive innovation across various industries.
If you are an approved partner and require assistance, contact your Google Partner Engineer for deployment support.


