A map of storage options in Google Cloud

Priyanka Vergadia
Staff Developer Advocate, Google Cloud
? Prefer to listen? Check out this episode on the Google Cloud Reader podcast
Where should your application store data? Of course, the choice depends on the use case. This post covers the different storage options available within Google Cloud across three storage types: object storage, block storage, and file storage. It also covers the use cases that are best suited for each storage option.
Object storage—Cloud Storage
Cloud Storage is an object store for binary and object data, blobs, and unstructured data. You would typically use it for any app, any type of data that you need to store, for any duration. You can add data to it or retrieve data from it as often as you need. The objects stored have an ID, metadata, attributes, and the actual data. The metadata could include all sorts of things about security classification of the file, the applications that can access it, and similar information.
Object store use cases include applications that need data to be highly available and highly durable, such as streaming videos, serving images and documents, and websites. It is also used for storing large amounts of data for use cases such as genomics and data analytics. You can also use it for storing backups and archives for compliance with regulatory requirements. Or, use it to replace old physical tape records and move them over to cloud storage. It is also widely used for disaster recovery because it takes practically no time to switch to a backup bucket to recover from a disaster.
There are 4 storage classes that are based on budget, availability and access frequency.
1. Standard buckets for high-performance, frequent access and highest availability:
- Regional / dual-regional locations for data accessed frequently / high throughput needs
- Multi-region for serving content globally
2. Nearline for data access less than once a month access
3. Coldline for data accessed roughly less than once a quarter
4. Archive for data that you want to put away for years
It costs a bit more to use standard storage because it allows for automatic redundancy and frequent access options. Nearline, coldline and archive storage offer 99% availability and cost significantly less.
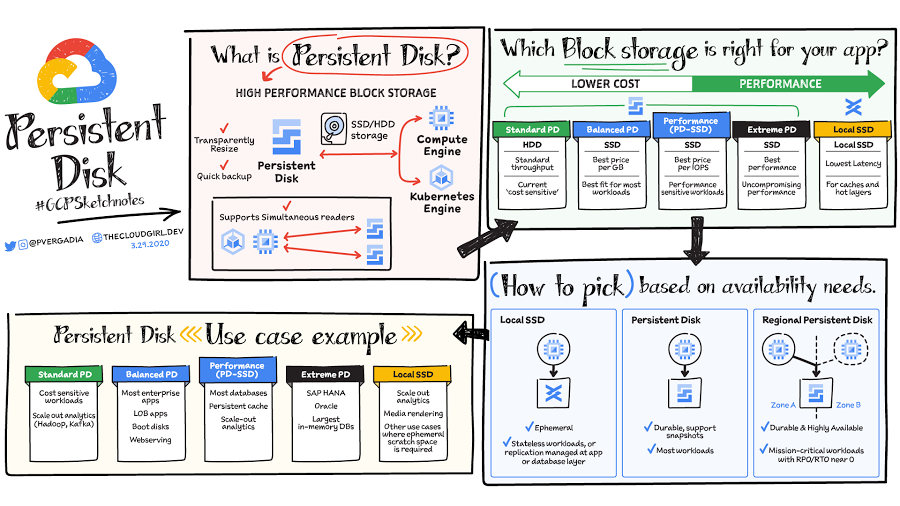
Block storage—Persistent Disk and Local SSD
Persistent Disk and Local SSD are block storage options. They are integrated with Compute Engine virtual machines and Kubernetes Engine. With block storage, files are split into evenly sized blocks of data, each with its own address but with no additional information (metadata) to provide more context for what that block of data is. Block storage can be directly accessed by the operating system as a mounted drive volume.
Persistent Disk is a block store for VMs that offers a range of latency and performance options. I have covered persistent disk in detail in this article. The use cases of Persistent Disk include disks for VMs and shared read-only data across multiple VMs. It is also used for rapid, durable backups of running VMs. Because of the high-performance options available, Persistent Disk is also a good storage option for databases.
Local SSD is also block storage but it is ephemeral in nature, and therefore typically used for stateless workloads that require the lowest available latencies. The use cases include flash optimized databases, host caching layers for analytics, or scratch disks for any application, as well as scale out analytics and media rendering.
File storage—Filestore
Now, Filestore! As fully managed Network Attached Storage (NAS), Filestore provides a cloud-based shared file system for unstructured data. It offers really low latency and provides concurrent access to tens of thousands of clients with scalable and predictable performance up to hundreds of thousands of IOPS, tens of GB/s of throughput, and hundreds of TBs. You can scale capacity up and down on-demand. Typical use cases of Filestore include high performance computing (HPC), media processing, electronics design automation (EDA), application migrations, web content management, life science data analytics, and more!
Conclusion
That was a quick overview of different storage options in Google Cloud. For a more in-depth look into each of these storage options check out this cloud storage options page or this video ?

For more #GCPSketchnote, follow the GitHub repo. For similar cloud content follow me on Twitter @pvergadia and keep an eye out on thecloudgirl.dev.