A Google Cloud block storage options cheat sheet
Priyanka Vergadia
Staff Developer Advocate, Google Cloud
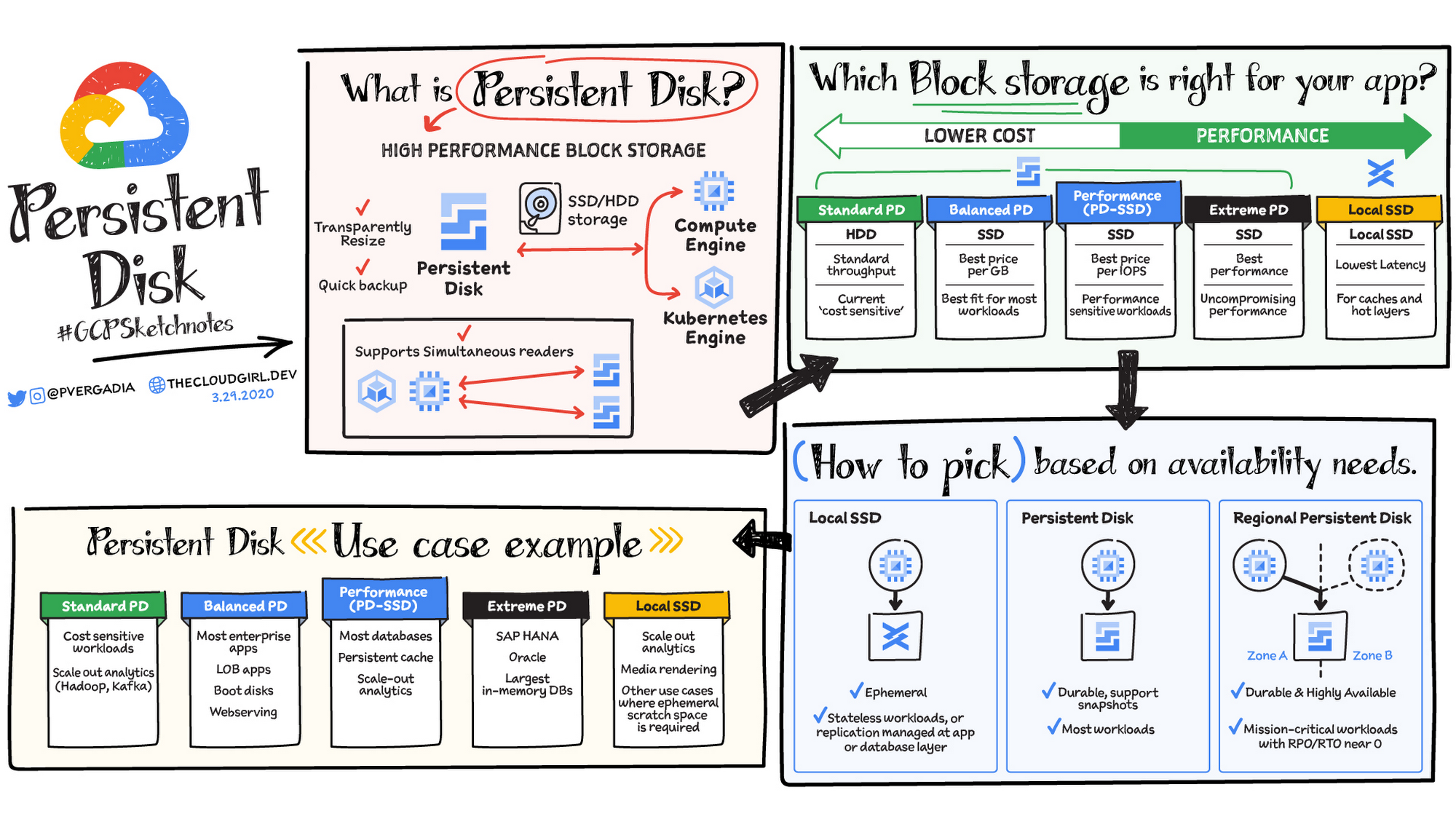
“Where do virtual machines store data so they can access it when they restart?”—We need storage that is persistent in nature. That’s where Persistent Disks come in.
Persistent Disk is a high performance block storage service that uses solid state drive (SSD) or hard disk drive (HDD) disks. These disks store data in blocks and are attached to compute. In Google Cloud it means they are attached to Compute Engine or Kubernetes Engine. You can attach multiple persistent disks to Compute Engine or GKE simultaneously and can configure quick, automatic, incremental backups or resize storage on the fly without disrupting your application.
Types of Block Storage
You can choose the best Persistent Disk option for you based on your cost and performance requirements.
Standard PD is HDD and provides standard throughput. Because it is the most cost effective option, it is best used for cost-sensitive applications and scale out analytics with Hadoop and Kafka.
Balanced PD is SSD and is the best price per GB option. This makes it a good fit for common workloads such as line of business apps, boot disks, and web serving.
Performance PD is SSD and provides the best price per IOPS (input/output operations per second). It is best suited for performance sensitive applications such as databases, caches, and scale out analytics.
Extreme PD is SSD optimized for applications with uncompromising performance requirements. These could include SAP HANA, Oracle, and the largest in-memory databases.
Local SSD is recommended if your apps need really low latency. It is best for hot caches that offer best performance for analytics, media rendering, and other use cases that might require scratch space.
How to pick block storage based on availability needs
You can also choose a Persistent Disk based on the availability needs of your app. Use Local SSD if you just need ephemeral storage for a stateless app that manages the replication at the application level or database layer. For most workloads you would be fine with Persistent Disk; it is durable and supports automated snapshots. But, if your app demands even higher availability and is mission critical then there is an option to use a regional persistent disk, which is replicated across zones for near zero Recovery Point Objective (RPO) and Recovery Time Objective (RTO) values.
Conclusion
Whatever your application use case maybe, if you are using a virtual machine or a Google Kubernetes Engine instance then you will be making a block storage choice. Use the pointers in this post to help you identify the option that works best for your use case. For a more in-depth look into Persistent Disk check out the documentation.

For more #GCPSketchnote, follow the GitHub repo. For similar cloud content follow me on Twitter @pvergadia and keep an eye out on thecloudgirl.dev.



