Spotify's journey to cloud: why Spotify migrated its event delivery system from Kafka to Google Cloud Pub/Sub
Tino Tereshko
Product Manager, Google BigQuery
You may have seen recent announcements that Spotify chose Google Cloud Platform to power its analytics and infrastructure. Spotify made this choice in no small part because of Google’s big data technologies including BigQuery, Dataflow, Dataproc and Pub/Sub. Spotify engineers could hardly contain their excitement, calling our tools “nearly magical,” “da bomb,” and even “THE BEST THING THAT HAS EVER HAPPENED TO ME” (yes, all caps).
Kind words aside, many folks wanted technical details. How? Why? What has been Spotify’s experience thus far, and what is their architecture? Spotify engineer Igor Maravic recently posted the first in a three-part series of blogs detailing Spotify’s pre-existing on-prem event delivery infrastructure, based on Kafka and Hadoop:
- How Spotify scaled to 700,000 events per second
- Kafka as a message delivery mechanism
- HDFS for storage and Crunch-MapReduce for ETL into AVRO
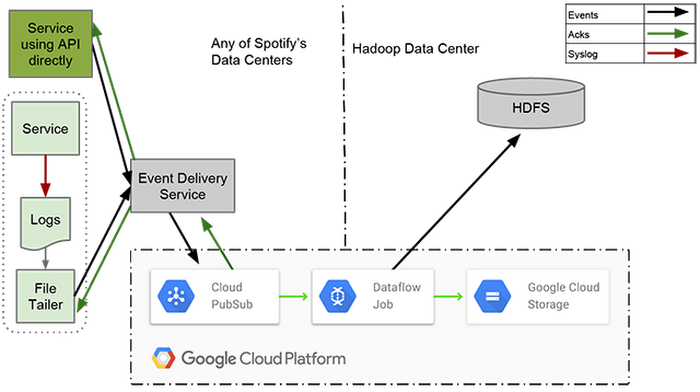
Today Igor released part two, diving into greater technical detail. It’s a fun read:
- Design requirements for the next generation of Spotify’s event delivery system, including automation, reliability, persistence and logical event type separation.
- Implementing event delivery at scale with Kafka 0.8.
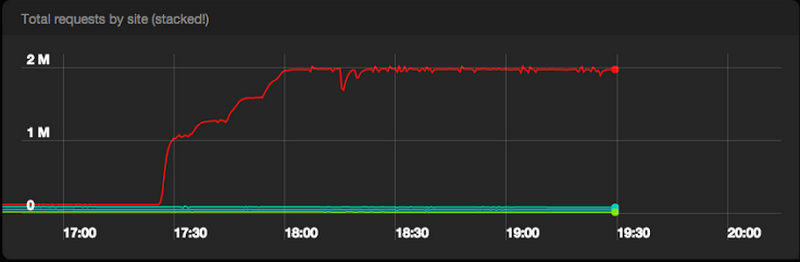
- Rationale behind choosing Google Pub/Sub over Kafka, including a Spotify-scale load test of 2,000,000 messages per second.
Stay tuned for Part 3, in which Igor discusses stream processing of events — why Spotify chose Google Cloud Dataflow, and their experiences with Dataflow’s unified batch and stream processing model.



