How WePay uses stream analytics for real-time fraud detection using GCP and Apache Kafka
Wei Li
Lead Engineer, WePay
When payments platform WePay was founded in 2008, MySQL was our only backend storage. It served its purpose well when data volume and traffic throughput were relatively low, but by 2016, our business was growing rapidly and they were growing along with it. Consequently, we started to see performance degradation to the point where we could no longer run concurrent queries without a negative impact on latency.
Along the way, we offloaded our analytic queries to replicated MySQL slaves to alleviate the problem. This approach worked for a while, but eventually we outgrew this dedicated instance, which began to impact our ability to do fraud detection — for which query response time is critical.
Clearly, we needed a new stream analytics pipeline for fraud detection that would give us answers to queries in near-real time without affecting our main transactional business system. In this post, I’ll explain how we built and deployed such a pipeline to production using Apache Kafka and Google Cloud Platform (GCP) services like Google Cloud Dataflow and Cloud Bigtable.
WePay’s fraud-detection use case
First, let me explain WePay’s fraud-detection use case for stream analytics. Imagine we have a merchant, Super, that's using WePay as its payment provider. Super receives a payment of $50 from a person, Bar, who is using the credit card, Amazing.We gather some attributes from these events across different dimensions. For example:
- Merchant Super receives a $50 payment.
- Amazing credit card makes a payment of $50.
- Person Bar pays $50 to Super.
We can also set up rules to help detect fraud based on these metrics. Using credit-card payments as an example, if the velocity of Amazing credit-card payments in the past minute was $10,000 comprising multiple small payments on the scale of $50, that would be a red flag for possible fraud. Needless to say, the closer the system can get to these metrics while events are happening in real time, the more effective the detection process will be.
Requirements and high-level architecture
WePay had three basic requirements for this new system:- Real-time (or near-real time) response without affecting the transactional database
- Resilience/fast recovery from failure
- Flexibility to support ad hoc queries without the need for code changes
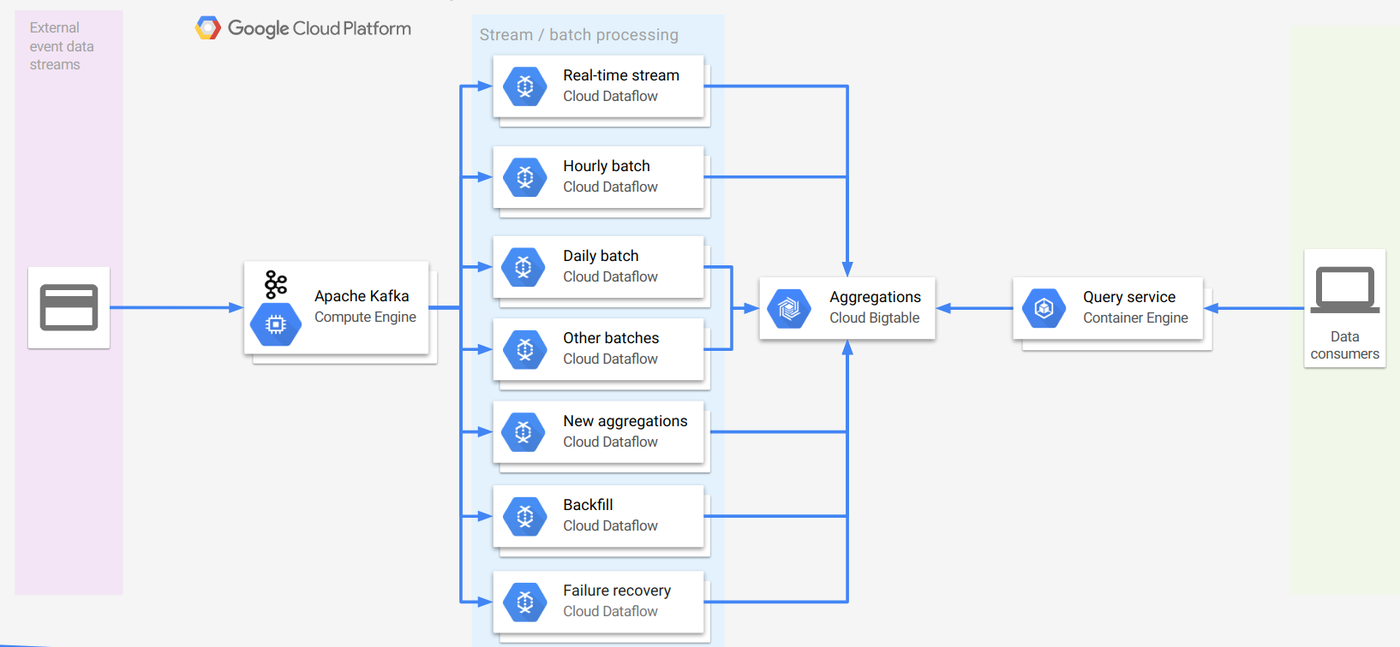
With these considerations in mind, we designed a high-level logical system comprising four layers: streaming event sources, a unified stream/batch aggregation engine, a persistent store for partial aggregates and a custom query interface to answer queries against arbitrary time ranges that doesn’t require changes to the pipeline (more on that later).

The last requirement is crucial for the fraud-detection system to be effective given that the fraud pattern is constantly changing. We designed a generic metric system to help answer ad hoc queries without requiring changes to the pipeline. I’ll explain more about how we design the metrics system later. But first, I’ll describe these layers in more detail, as well as which services we used for implementation.
Streaming event source (Apache Kafka)
Our data sources need to serve both streaming and batch pipelines. For the data ingestion layer, we chose Apache Kafka for its very low latency and mature ecosystem and because it was already widely adopted inside WePay.For time-sensitive aggregation, we instrumented various checkpoints inside our application code to emit Apache Avro messages as Kafka events in real time. Inside each message there's a mandatory time field to record the time the event occurred. The idea is that the downstream aggregation engine will process events based on the specified custom event time so that we can always get deterministic behavior.
Aggregation engine (Cloud Dataflow)
We had some particular requirements for the streaming/batch aggregation engine, including:- Ability to process events based on custom event time
- Unified streaming/batch processing
- Strong exactly-once semantics for event handling, which is critical for fraud detection (because over-counting can lead to false positives)
- Elastic resource allocation to handling bursty event patterns
Unified Unbounded/Bounded KafkaIO
As noted above, one key advantage of using Cloud Dataflow is the unified interface between streaming and batch modes. Kafka can serve as an inherently unbounded source for Cloud Dataflow (along with Cloud Pub/Sub) and a community-contributed Cloud Dataflow KafkaIO is available for stream data processing. In order for WePay to use Kafka as a bounded source for batch processing, we developed a version of BoundedKafkaIO that can filter out events falling within a time range by comparing the custom event time field in each Kafka message.
Persistent store for partial aggregates (Cloud Bigtable)
One of our technical considerations was to quickly recover from failure conditions. Hence, to avoid maintaining lots of state information in-memory and frequently checkpointing them, we want to persist partial aggregates to some form of on-disk storage as soon as they're generated. Our persistence pattern is to write once and read multiple times, with the output from pipelines always monotonically increasing on the time dimension (and there's not much write contention there). To meet those requirements, we needed a horizontally scalable storage system with super-low read latency and high write throughput.Our solution was to write to Cloud Bigtable directly from Cloud Dataflow using the BigtableIO sink. Per the docs, we use a tall table because time-series data is involved. To support different time granularities (minute, hour, day and week), we set up separate column families.
Row keys consist of two parts: the dimensions for the metric and the timestamp boundary. For example:
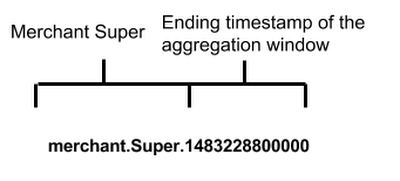
A sample layout based on our example is shown below.
| Minute | Hour | Day | Week | |||||
| Row Key | Total | Avg | Total | Avg | Total | Avg | Total | Avg |
| merchant.Super.1483228800000 | 3000 | 20 | 180K | 20 | 4.3M | 20 | 30M | 20 |
| merchant.Super.1480550400000 | 2000 | 20 | 120K | 20 | 2.8M | 20 | 20M | 20 |
| merchant.Super.1475280000000 | 1000 | 20 | 60K | 20 | 1.4M | 20 | 10M | 20 |
Bigtable layout for total and average payment volume for our example merchant, Super
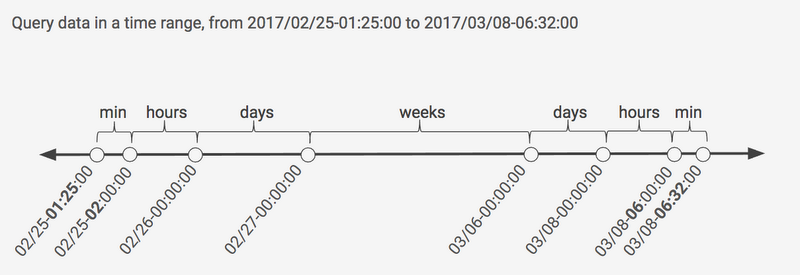
A typical query against the system provides two parameters: the dimension for a specific metric and the range of time of the interests. With the partial aggregated results for different granular windows already persisted to different column families in Cloud Bigtable, we can get the final aggregation by stitching results from different granular windows in the order of large to small. By doing so, we get better performance by reducing the data load.
For example, let’s say a WePay analyst needs to know total sales for the past 30 days of total transaction amounts ending at midnight of 2017/01/02 08:32:00. When minute, hour, day and week partial aggregations are available, the custom query API calculates the result by stitching windows from seven pairs, with the majority coming from the largest granular weekly window.
Ad hoc queries (custom query engine)
One constant theme for fraud patterns is that there's no fixed pattern, so we need the system to answer ad hoc queries from our custom query engine without the need for code changes.To solve this problem, we abstracted a generic metric definition as shown below.
The schema contains three fields: eventTime, dimension, and metric value {type, value}. Using this schema, we can convert a payment event to a few generic metrics (example shown below) to answer different questions.
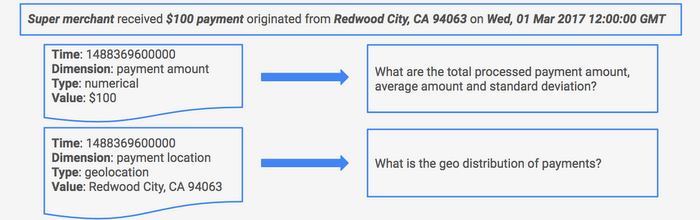
Using generic metrics as input, our pipeline can simply follow the instructions based on the type field from each generic message and generate different statistics. For example, we generate min, max, average, sum, variance, etc., for numeric values and we generate a distribution count for categorical values. Moreover, the type system is extensible and we can add different custom types.
Simple example DAG
With this approach, we can make the same DAG generate different aggregations by changing the underlying metric definitions. In other words, to generate partial aggregates that support new types of queries, we can push the business logic to the external layer without changing any code and deploying new pipelines.Summary
After a few months of teamwork, we deployed the system to our production environment in the second half of 2016. (See diagram below.) Since then, the system has been running in shadow mode, processing production data smoothly and in accordance with our requirements:- Both stream and batch pipelines live off Kafka message systems, and are decoupled from the main transactional system.
- The streaming Cloud Dataflow pipeline provides lower latency compared to our old system relying on MySQL replication.
- Persistently storing partial aggregates in Cloud Bigtable contributes to low latency when querying time-series data.
- Event-time stamping and unified streaming and batch processing proved to be a huge win. We can just replay for scenarios such as large-grained window aggregation, backfill and failure recover, etc.
- Generic metric definition coupled with simple DAG makes it very easy to augment the aggregation system without code changes.
Next steps
As mentioned earlier, one constant theme of fraud is that the pattern is always evolving. The system we implemented is very flexible for answering ad-hoc queries thanks to a generic metric system. However, to fully leverage that system, we need to be able to generate different metrics easily. One thing we're looking to provide in that area is a framework that accommodates custom logic for converting different events into generic metrics. That custom logic could be for creating new aggregations on which we can build fraud-detection rules, for extracting new features for machine-learning modules, and so on.Also, we want to build better monitoring tools that offer a holistic view of the pipeline. This way, we can easily monitor the overall system and help pinpoint where the performance bottleneck is.
Last but not least, we plan to track new Apache Beam SDK releases so we can get access to the latest community contributions as they become available.



