How to process weather satellite data in real-time in BigQuery
Lak Lakshmanan
Director, Analytics & AI Solutions
Since the 1960s, scientists have been forecasting the weather using satellite-captured imagery. Although access to these satellite feeds used to be reserved just for meteorologists, these days anyone can jump online to find current satellite footage for their area. But what if you wanted to take things a step further? Maybe you’re curious about the history of weather events, or want to create a real-time feed for where you live. This blog post will show you how to do that on Google Cloud Platform.
Thanks to the NOAA Big Data Project, data from the GOES-16 geostationary satellite is freely available on Google Cloud. The GOES-16 is part of NOAA’s operational weather observation network and provides a view of North and South America, as well as the Atlantic and Pacific oceans. This means you can view updated images of weather patterns, storms, wildfires, and other phenomena in these areas in near real-time. With this data we’ll create two pipelines: one that accesses historical files and another that performs ongoing data processing.
Plotting the path of Hurricane Maria
To demonstrate how to access historical files, I’ll show you how to plot Hurricane Maria’s path as it made landfall in Puerto Rico. The first step is to find the hurricane’s location at different points in time. Hurricane track data is present in BigQuery, and getting the location of tracks is as simple as running the following query:If you try it out in BigQuery’s console, you should see:
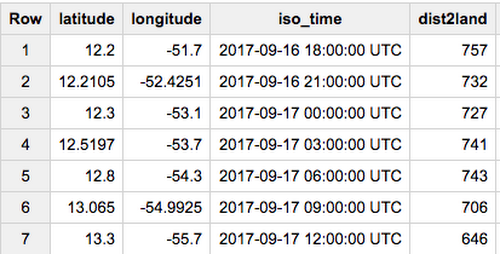
Given the location of the hurricane at a certain time, we can get the NetCDF file of raw data, as described in the following section. The full code is on GitHub; in particular, see the method goes_to_jpeg. Feel free to peruse the code for full context as you read this blog post.
Finding satellite images from a specific point in time time
Let’s say we want to plot the infrared channel (C14) Level 1b data. The infrared channel senses solar energy re-emitted from the earth’s surface and can be used to depict the location and intensity of thunderstorms. And unlike the visible channel, the infrared channel is also available both day and night.The first step is to take a timestamp from the hurricane track and find its corresponding satellite image. This could be done either by writing a SQL query that searches the metadata in BigQuery or by listing the contents of Google Cloud Storage. For example, to find the C14 files collected during the 18Z hour (18:00 UTC) on the 258th Julian day of 2017 (6:00 PM local time on Friday, September 15, 2017 in London, for example), we would run this command:
In the command above, gsutil is a command-line utility that comes with the Google Cloud SDK. It’s pre-installed on Cloud Shell1 and Google Compute Engine virtual machines. The bucket gcp-public-data-goes-16 contains all the GOES-16 files.
In this case, we’re interested in L1b data, full disk (RadF) and infrared channel (C14). When I did this, I got:
Although it’s possible to use the Python subprocess package to invoke the command-line utility, there’s a better way. The command-line client simply invokes a REST API and there is a Python package, google.cloud.storage, that does the same thing.
Here’s the equivalent code to list files that match specific patterns:
Plotting satellite imagery
Once we have the filenamegs://gcp-public-data-goes-16/ABI-L1b-RadF/2017/258/18/OR_ABI-L1b-RadF-M3C14_G16_s20172581800377_e20172581811144_c20172581811208.nc in the above example, the next step is to read it using the NetCDF API. However, because the NetCDF API doesn’t read directly off Google Cloud Storage, we’ll download to a local file and use the Python NetCDF API to read the file. On the command-line, downloading the file can be achieved using gsutil cp. Not surprisingly, there is a Pythonic equivalent blob.download_to_filename() to achieve the same thing in Python code.With the file now stored locally in a temporary directory, the following code scales the radiance data to lie in the range (0-1), crops it to the region of interest (recall that we are working with a “full disk” which is an entire hemisphere of the Earth), increases the contrast and plots it into a jpeg or png file:
Cropping the satellite image can be achieved using the pyresample Python package (see the code in GitHub for details). Here’s what an example result looks like:

The created images can be stored durably on Cloud Storage using blob.upload_from_filename(localfile), so that the Compute Engine instance can be deleted after the images are created.
While we could do the above processing in a loop, once for every timestep of the hurricane, it is quite time-consuming. This is because creating a single image (above) takes about 30 seconds, so creating a loop of 120 or so images for a single hurricane would take an hour, and several hours to create the images for all the hurricanes in a season. Is there a faster, more efficient way?
Serverless, parallel data processing
There are two issues with the approach above. First: we set up a Compute Engine instance, installed software on it, and then carried out the processing. Even though it’s possible to use a public cloud platform as simply rented bare-metal infrastructure, using Google Cloud in this manner loses much of the benefits of Google’s data processing infrastructure. We should be looking for ways to simply submit our data processing code and have it be executed in an autoscaled manner. Second: it is inefficient to create the JPEG images one at a time. Submitting the code to an autoscaling service also solves this second issue with our approach—instead of creating the JPEG images one at a time, we’re able to create them in parallel on a number of workers.The autoscaling data pipeline service on Google Cloud is called Cloud Dataflow, and the pipeline that you submit to it can be written using the apache_beam Python package2. The pipeline code to run the BigQuery query, and send along each row of the result is:
Running the Python program (you can do this from Cloud Shell) submits the code to the Dataflow service which handles installing the packages, running the code, managing job failure, and autoscaling for efficient execution (i.e., adding new workers when it gets bogged down and shutting down workers when there aren’t enough tasks). You can see the autoscaling in action as the job runs from the Dataflow section of the Google Cloud console:
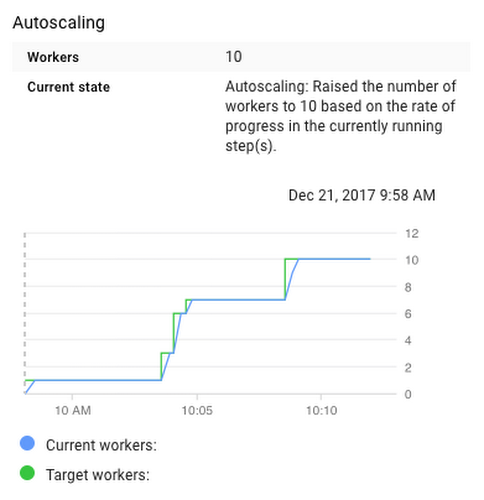
The resulting images are shown as a video loop here:

Because this is a distributed system, the service takes about five minutes to initialize, but only 10 minutes to process all of the images for Hurricane Maria. The larger and more complex the task, the more cost-effective a serverless data pipeline becomes.
For example, to create the images of every hurricane in the North Atlantic (basin = 'NA'), all we need to do is change the input query to:
The rest of the pipeline remains the same, but the distribution now scales to create nearly a thousand images:
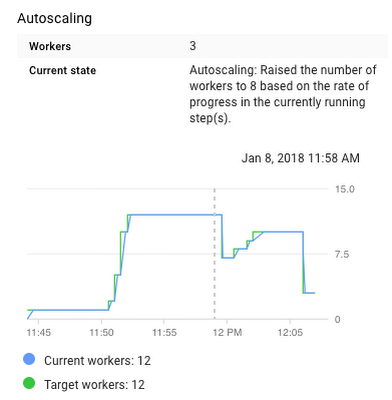
The Python source code to create and run these Dataflow pipelines is on GitHub—when I ran it, it took two hours and cost $0.87 to create images corresponding to all the North Atlantic hurricane tracks in 2017.
Creating images routinely
Suppose you wanted to subscribe to the GOES feed and create the satellite image over a certain area (perhaps Seattle, WA) every time a new infrared image is available. Instead of repeatedly querying the BigQuery table of GOES metadata to see if there are any new images, you can listen to a Cloud Pub/Sub topic and be notified about new events.One way to consume a notification is to write a Cloud Function that gets kicked off in response to a new event. However, one of the advantages of Apache Beam is that it works on both stream and batch—therefore, we can reuse much of the code we wrote above. Instead of querying the BigQuery table, we would listen to the Pub/Sub topic corresponding to the GOES bucket, filter on only the infrared images, and invoke the goes_to_jpeg function whenever an infrared full disk image is received (full code is on GitHub):
What’s received from Pub/Sub every time a new file shows up in Cloud Storage is a string in JSON format. Here’s how we can check whether it’s an infrared image:
Here’s an example of the infrared image over Seattle, WA produced in near-real-time:

I hope this gets you started using the public GOES imagery in Google Cloud. You might consider trying to find correlations between this satellite weather data and our other public datasets, or train machine learning models that use these datasets in conjunction. Happy coding!
Acknowledgments:
Thanks to Ken Knapp of NOAA for pointing us to the hurricane data, and to David Hoese and John Cintineo of the University of Wisconsin for helping me with reprojecting and resampling the satellite data.
1 If you are trying this out on Cloud Shell, use the option to boost the VM since the default microvm is not powerful enough. I suggest using a n1-standard-1 Compute Engine instance. In either case, run the install.sh script in GitHub to install the necessary Linux and Python packages. ↩
2 Besides Python, you can also submit Java code to Cloud Dataflow. An example of writing an Apache Beam Java pipeline to process satellite data is also in the GitHub repository. ↩



