How to handle mutating JSON schemas in a streaming pipeline, with Square Enix
Reza Rokni
Dataflow Product Manager
Back in May, Paul Barnes (Google Customer Engineer) and I headed over to Square Enix’s offices to meet up with Chris Windsor, Square Enix’s Data Engineering Lead, for a streaming architecture jam session.
Square Enix’s system, explained Chris, consisted of a static Cloudera Hadoop cluster utilizing Spark for batch processing. Although, to date, it had performed admirably, Chris knew a change would soon be needed. The amount of data that required processing and storing had naturally increased over time, and although he knew the simple solution would be to increase the size of the cluster, he also knew it would not be sustainable in terms of scalability and efficiency. So Chris invited us to join him in coming up with a solution—which conveniently also gave us the chance to exchange steely gazes with statues and giant prints of some of our favorite in-game characters.
Because Square Enix is such a significant player in the gaming industry, we thought we’d approach this task as a game level walkthrough. The game, of course, would be building an end-to-end streaming pipeline. Our main character would be our valiant programmer, Chris. And along the way there’d be twists and turns, as well as a few epic boss fights that would require skill, cunning, and a little bit of patience to overcome.
Building a new end-to-end streaming pipeline, would be no simple task. As Chris pointed out to us, the nature of the lifecycle of Square Enix’s games meant that the amount of data they’d get at any given time could vary drastically. They’d need a system that could scale automatically, determined by throughput. And it would need to accept JSON data of any shape, and automatically update the schema in the database without any manual intervention.
Furthermore, Chris told us that the system would need to be able to programmatically determine which tables to stream into, in real time, and with time partitioning. It would need to make data available in as close to real time as possible, and allow Square Enix to add in data enrichment at any stage of the pipeline, if necessary. And, finally, it needed to let them ignore duplicated data.
Readying our hero to battle mutating JSON schemas
This walkthrough will guide you through one level of the streaming analytics pipeline game, specifically the level where you’ll enter into an epic duel against a mutating JSON schema. At the end of our walkthrough, your character will be equipped with an end-to-end low-latency streaming pipeline that can:- Consume 10,000s of events per second with neither warm-up nor “prep time.”
- Branch and shape the data based on the event type for processing into multiple tables
- Enable the analytics team to run up-to-date queries.
- Allow more stream-based analytics to be folded into the pipeline down the road
Equipping our character
In order to equip our character with the best tools for this task, we picked the same equipment that’s used in our mobile gaming analysis walkthrough solution: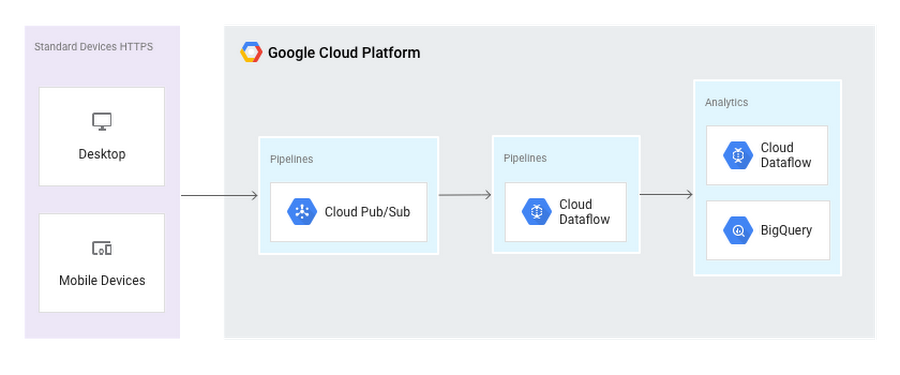
Equipped with those tools, Chris was able to navigate the levels and with ease. "Using the various SDKs for each of these tools,” said Chris, “it was fairly simple to create a basic pipeline that cleaned, validated and enriched JSON objects where required, then streamed them into BigQuery."
But as in any great game, there was a final boss we needed to confront. Because Square Enix’s system is used by multiple studios at any given time, schema changes can happen at a moment’s notice, requiring time-consuming batch processes to be kicked off manually to pick up any new changes. “The next step,” explained Chris, “was to create a custom DoFn that could calculate the schemas in the JSON object and the schema from BigQuery, and then merge them when there are any additive mutations, in real time. This also needed to support complex JSON structures too. This proved to be quite a battle."
Introducing the Streaming Mutating JSON Boss!
Challenges:- This Square Enix team provides stream-processing as a general service for other departments and game developers, which means that catching changes in the JSON cannot be driven into a continuous integration (CI/CD) process. It can, and will, mutate just when you think you’ve won the fight.
- The system had to be dynamic and manpower-efficient, so the team could not place a manual step in the process, which would require the use of a dead letter pattern. (See our blog on Dataflow patterns for more info.) This precluded the ability to push unknown JSON schemas into a dead letter bucket until the updates can be fixed by one of the team applying a schema change.
- This final JSON boss has an Achilles’ heel: all JSON mutations are additive. Given a schema: {id:string,lvl:number,action:string} there could be a mutation to {id:string,lvl:number,action:string, points:integer} but not to {id:string,action:string} so A ⊆ B. BigQuery allows for schema changes that are additive within the same table, and the schema change allows for updates to happen without having to take BigQuery “offline”.
Defeating the “final” boss:
In the first attempt at this boss, Chris used version 1.9 of the Dataflow SDK to create a pipeline that almost won the day. He used a GroupByKey function on the JSON type and then a manual check on the JSON schema against the known good BigQuery schema. If there was a difference, the schema would mutate and the updates would be pushed through. However, this design could not make use of the inbuilt efficiencies that BigQueryIO provided, and also burdened us with technical debt.Chris then tried various other tactics to beat the boss. In his words ... "The first attempt at fixing this inefficiency was to remove the costly JSON schema detection ‘DoFn’ which every metric goes through, and move it to a ‘failed inserts’ section of the pipeline, which is only run when there are errors on inserting into BigQuery,” said Chris. “DoFn’s are a lovely piece of magic that take an input type and produce an output type. The pipeline then creates PCollections based on the outputs of these DoFn’s. This makes it incredibly easy to create a ‘module’ and place it in at any point of the pipeline, or, in this case, remove it and place it back in further down. However, whilst this did increase our throughput, Dataflow was still not scaling as much as I had hoped.”
This final boss proved to be the most challenging one yet, but the Dataflow team had been busy forging a new piece of equipment for the player: a SDK upgrade to version 2.1.0! Chris leveled up using the Dataflow runner using the Beam SDK version 2.1.0 and had another go at defeating the level.
In the previous version of BigQueryIO, the sink would terminate with a PDone, making it tricky to deal with non-transient errors, like new schema differences. The new version, however, provides fine grain features for dealing with these types of issues.
- InsertRetryPolicy, which is passed to the method which gives access to defining how different types of errors should be dealt with: BigQueryIO.write().withFailedInsertRetryPolicy(InsertRetryPolicy policy).
- The return type of the BigQueryIO sink is now a WriteResult rather than a PDone, which is a PCollection containing any failed errors.
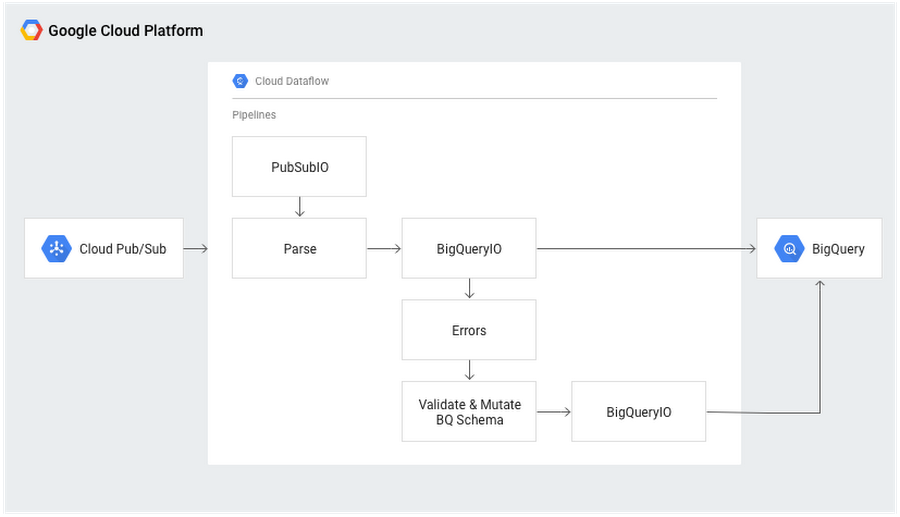
The streaming mutating JSON schema is a threat no more! Our conquering hero is now able to move onto the next level.




