Guide to common Cloud Dataflow use-case patterns, Part 2
Reza Rokni
Dataflow Product Manager
John LaBarge
Solution Architect
Editor’s note: This is part two of a series on common Dataflow use-case patterns. You can find part one here.
This open-ended series (see first installment) documents the most common patterns we’ve seen across production Cloud Dataflow deployments. In Part 2, we’re bringing you another batch — including solutions and pseudocode for implementation in your own environment.
Let’s dive in!
Pattern: GroupBy using multiple data properties
Description:Data elements need to be grouped by multiple properties.
Example:
IoT data arrives with location and device-type properties. You need to group these elements based on both these properties.
Solution:
- Create a composite key made up of both properties.
- Use the composite key as input to the
KV.of()factory method to create a KV object that consists of the composite key(K)and pertaining data element from which the composite key was derived (V). - Use a
GroupByKeytransform to get your desired groupings (e.g., a resultingPCollection>>).
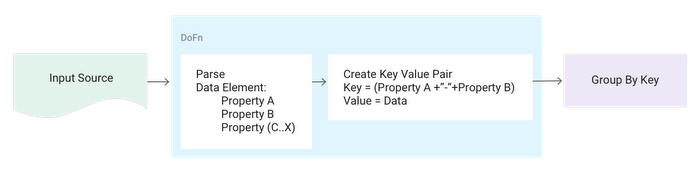
Pseudocode:
Note: building a string using concatenation of "-" works but is not the best approach for production systems. Instead, we generally recommend creating a new class to represent the composite key and likely using @DefaultCoder. See "Annotating a Custom Data Type with a Default Coder" in the docs for Cloud Dataflow SDKs 1.x; for 2.x, see this.
Pattern: Joining two PCollections on a common key
Description:Joining of two datasets based on a common key.
Example:
You want to join clickstream data and CRM data in batch mode via the user ID field.
Solution:
- For each dataset in the join, create a key-value pair using the utility KV class (see above).
- Create tags so that you can access the various collections from the result of the join.
- Apply the
CoGroupByKeyto match the keys for the join operation. - To do a left outer join, include in the result set any unmatched items from the left collection where the grouped value is null for the right collection. Likewise, to do a right outer join, include in the result set any unmatched items on the right where the value for the left collection is null. Finally, to do an inner join, include in the result set only those items where there are elements for both the left and right collections.
SideInputs for any activity where one of the join tables is actually small — around 100MB in stream mode or under a 1GB in batch mode. This will perform much better than the join operation described here. This join is shuffle heavy and is best used when both collections being joined are larger than those guidelines. SideInputs are not precisely equivalent, however, as they're only read when data shows up on the main input. In contrast, a CoGroupByKey triggers if data shows up on either side. Think of SideInputs as an inner-loop join — with nested loops, the inner loop only runs if the outer loop runs first.Pseudocode:
Note: Consider using the new service-side Dataflow Shuffle (in public beta at the time of this writing) as an optimization technique for your CoGroupByKey.
Pattern: Streaming mode large lookup tables
Description:A large (in GBs) lookup table must be accurate, and changes often or does not fit in memory.
Example:
You have point of sale information from a retailer and need to associate the name of the product item with the data record which contains the productID. There are hundreds of thousands of items stored in an external database that can change constantly. Also, all elements must be processed using the correct value.
Solution:
Use the "Calling external services for data enrichment" pattern but rather than calling a micro service, call a read-optimized NoSQL database (such as Cloud Datastore or Cloud Bigtable) directly.
- For each value to be looked up, create a Key Value pair using the
KVutility class. - Do a
GroupByKeyto create batches of the same key type to make the call against the database. - In the
DoFn, make a call out to the database for that key and then apply the value to all values by walking through the iterable. Follow best practices with client instantiation as described in "Calling external services for data enrichment".
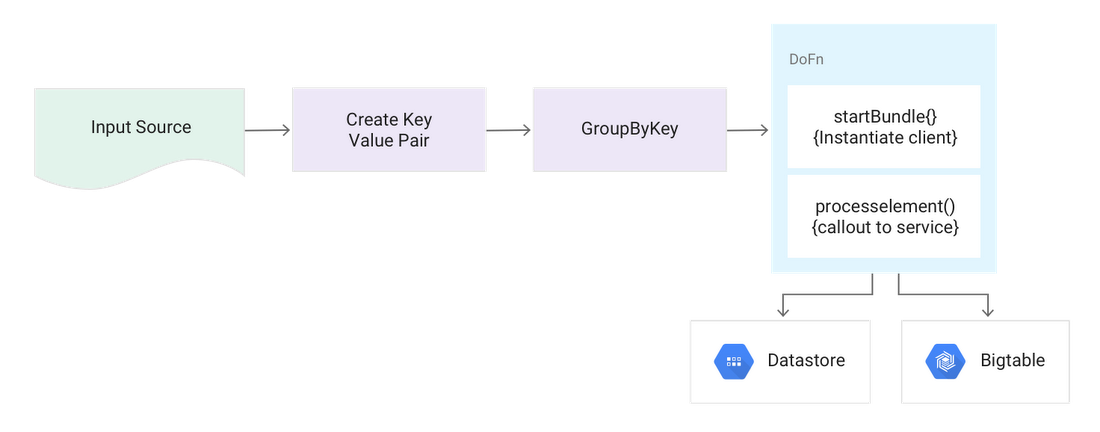
Pseudocode:
Pattern: Merging two streams with different window lengths
Description:Two streams are windowed in different ways — for example, fixed windows of 5 mins and 1 min respectively — but also need to be joined.
Example:
You have multiple IoT devices attached to a piece of equipment, with various alerts being computed and streamed to Cloud Dataflow. Some of the alerts occur in 1-min fixed windows, and some of the events occur in 5-min fixed windows. You also want to merge all the data for cross-signal analysis.
Solution:
To join two streams, the respective windowing transforms have to match. Two options are available:
- Similar to the "Pushing data to multiple storage locations" pattern, create multiple branches to support three different windowing strategies.
- Re-window the 1-min and 5-min streams into a new window strategy that's larger or equal in size to the window of the largest stream.
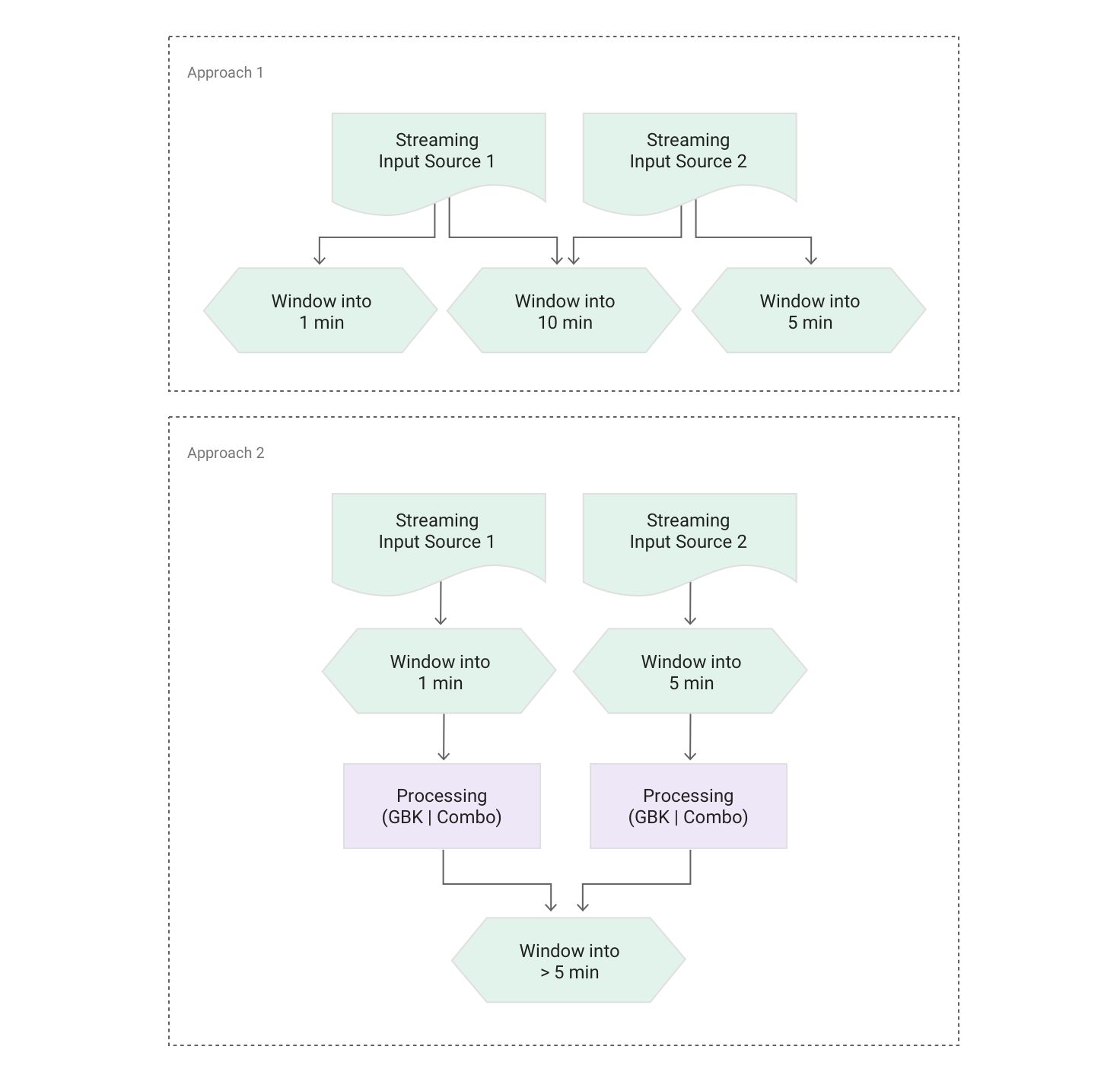
Pseudocode:
Pattern: Threshold detection with time-series data
Description:This use case — a common one for stream processing — can be thought of as a simple way to detect anomalies when the rules are easily definable (i.e., generate a moving average and compare that with a rule that defines if a threshold has been reached).
Example:
You normally record around 100 visitors per second on your website during a promotion period; if the moving average over 1 hour is below 10 visitors per second, raise an alert.
Solution:
Consume the stream using an unbounded source like PubSubIO and window into sliding windows of the desired length and period. If the data structure is simple, use one of Cloud Dataflow’s native aggregation functions such as AVG to calculate the moving average. Compare this AVG value against your predefined rules and if the value is over / under the threshold, and then fire an alert.
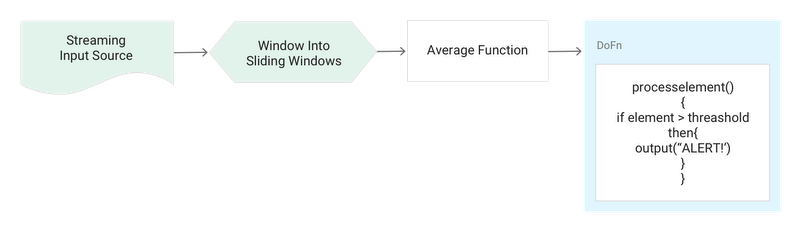
Pseudocode:




