Google Cloud, HEPCloud and probing the nature of Nature
Paul Rossman
Google Cloud Developer Relations
Understanding the nature of the universe isn't a game for the resource-constrained. Today, we probe the very structure of matter using multi-billion dollar experimental machinery, hundreds of thousands of computing cores and exabytes of data storage. Together, the European Center for Nuclear Research (CERN) and partners such as Fermilab built the Large Hadron Collider (LHC), the world's largest particle collider, to recreate and observe the first moments of the universe.
Today, we're excited to announce that Google Cloud Platform (GCP) is now a supported provider for HEPCloud, a project launched in June 2015 by Fermilab’s Scientific Computing Division to develop a virtual facility providing a common interface to local clusters, grids, high-performance computers and community and commercial clouds. Following the recommendations from a 2014 report by the Particle Physics Project Prioritization Panel to the national funding agencies, the HEPCloud project demonstrates the value of the elastic provisioning model using commercial clouds.
The need for compute resources by the high-energy physics (HEP) community is not constant. It follows cycles of peaks and valleys driven by experiment schedules and other constraints. However, the conventional method of building data centers is to provide all the capacity needed to meet peak loads, which can lead to overprovisioned resources. To help mitigate this, Grid federations such as the Open Science Grid offer opportunistic access to compute resources across a number of partner facilities. With the appetite for compute power expected to increase over 100-fold over the next decade, so too will the need to improve cost efficiency with an “elastic” model for dynamically provisioned resources.
With Virtual Machines (VMs) that boot within seconds and per-minute billing, Google Compute Engine lets HEPCloud pay for only the compute it uses. Because the simulations that Fermilab needs to perform are fully independent and parallelizable, this workload is appropriate for Preemptible Virtual Machines. Without the need for bidding, Preemptible VMs can be up to 80% cheaper compared to regular VMs. Combined with Custom Machine Types, Fermilab is able to double the computing power of the Compact Muon Solenoid (CMS) experiment by adding 160,000 virtual cores and 320 TB of memory in a single region, for about $1400 per hour.
At SC16 this week, Google and Fermilab will demonstrate how high-energy physics workflows can benefit from the elastic Google Cloud infrastructure. The demonstration involves computations that simulate billions of particles from the CMS detector (see fig. 1) at the LHC. Using Fermilab’s HEPCloud facility, the goal is to burst CMS workflows to Compute Engine instances for one week.

The demonstration also leverages HTCondor, a specialized workload management system for compute-intensive jobs, to manage resource provisioning and job scheduling. HTCondor manages VMs natively using the Compute Engine API. In conjunction with the HEPCloud Decision Engine component, it enables the use of the remote resources at scale at an affordable rate (fig. 2). With half a petabyte of input data in Google Cloud Storage, each task reads from the bucket via gcsfuse, performs its computation on Preemptible VMs, then transports the resulting output back to Fermilab through the US Department of Energy Office of Science's Energy Sciences Network (ESnet), a high-performance, unclassified network built to support scientific research.
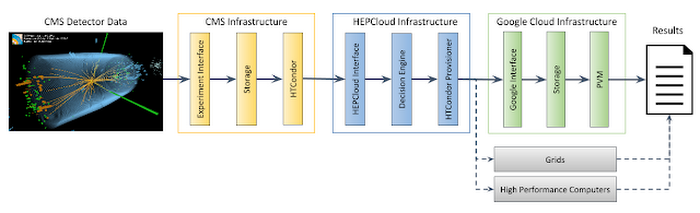
The demonstration shows that HTCondor, HEPCloud and GCP all work together to enable real HEP science to be conducted in a cost-effective burst mode at a scale that effectively doubles the current capability. The Fermilab project plans to transition the HEPCloud facility into production use by the HEP community in 2018.
Every year we have to plan to provision computing resources for our High-Energy Physics experiments based on their overall computing needs for performing their science. Unfortunately, the computing utilization patterns of these experiments typically exhibit peaks and valleys during the year, which makes cost-effective provisioning difficult. To achieve this cost effectiveness we need our computing facility to be able to add and remove resources to track the demand of the experiments as a function of time. Our collaboration with commercial clouds is an important component of our strategy for achieving this elasticity of resources, as we aim to demonstrate with Google Cloud for the CMS experiment via the HEPCloud facility at SC16.
— Panagiotis Spentzouris, Head of the Scientific Computing Division at Fermilab
If you're at SC16, stop by the Google booth and speak with experts on scalable high performance computing or spin up your own HTCondor cluster on Google Cloud Platform for your workloads.



