Google Cloud Dataproc managed Spark and Hadoop service now GA
James Malone
Product Manager, Google Cloud
Today Google Cloud Dataproc, our managed Apache Hadoop and Apache Spark service, says goodbye to its beta label and is now generally available.
When analyzing data, your attention should be focused on insights, not your tools. Often, popular tools to process data, such as Apache Hadoop and Apache Spark, require a careful balancing act between cost, complexity, scale, and utilization. Unfortunately, this means you focus less on what is important — your data — and more on what should require little or no attention — the cluster processing it.
We created our managed Spark and Hadoop cloud service, Google Cloud Dataproc, to rectify the balance, so that using these powerful data tools is as easy as 1-2-3.
Since Cloud Dataproc entered beta last year, customers have taken advantage of its speed, scalability, and simplicity. We’ve seen them create clusters from three to thousands of virtual CPUs, using our Developers Console and Google Cloud SDK, without wasting time waiting for their cluster to be ready.
With integrations to Google BigQuery, Google Cloud Bigtable, and Google Cloud Storage, which provide reliable storage independent from Dataproc clusters, customers have created clusters only when they need them, saving time and money, without losing data. Cloud Dataproc can also be used in conjunction with Google Cloud Dataflow for real-time batch and stream processing.
While in beta, Cloud Dataproc added several important features including property tuning, VM metadata and tagging, and cluster versioning. In general availability, just like in beta, new versions of Cloud Dataproc, with new features, functionalities and software components, will be frequently released. One example is support for custom machine types, available today.
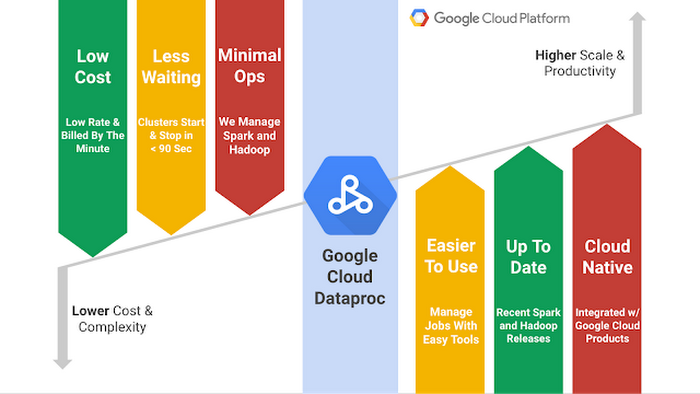
Cloud Dataproc minimizes two common and major distractions in data processing — cost and complexity by providing:
- Low-cost. We believe two things — using Spark and Hadoop should not break the bank and that you should pay for what you actually use. As a result, Cloud Dataproc is priced at only 1 cent per virtual CPU in your cluster per hour, on top of the other Cloud Platform resources you use. Moreover, with per-minute billing and a low 10-minute minimum, you pay for what you actually use, not a rounded (up) approximation.
- Speed. With Cloud Dataproc, clusters do not take 10, 15, or more minutes to start or stop. On average, Cloud Dataproc start and stop operations take 90 seconds or less. This can be a 2-10x improvement over other on-premises and IaaS solutions. As a result, you spend less time waiting on clusters and more time hands-on with data.
- Management. Cloud Dataproc clusters don't require specialized administrators or software products. Cloud Dataproc clusters are built on proven Cloud Platform services, such as Google Compute Engine, Google Coud Networking, and Google Cloud Logging to increase availability while eliminating the need for complicated hands-on cluster administration. Moreover, Cloud Dataproc supports cluster versioning, giving you access to modern, tested, and stable versions of Spark and Hadoop.
Cloud Dataproc makes two often problematic needs in data processing easy — scale and productivity by being:
- Easy. You can create, monitor, and delete Cloud Dataproc clusters and jobs directly through Google Developers Console and Cloud SDK. For more advanced use cases, you can use the Cloud Dataproc REST API with a programming language, such as Python, to programmatically interact with Cloud Dataproc without hassle.
- Modern. Cloud Dataproc is frequently updated with new image versions to support new software releases from the Spark and Hadoop ecosystem. This provides access to the latest stable releases while also ensuring backward compatibility. For general availability we're releasing image version 1.0.0 with support for Hadoop 2.7.2, Spark 1.6.0, Hive 1.2.1, and Pig 0.15.0. Support for other components, such as Apache Zeppelin (incubating) are provided in our GitHub repository for initialization actions.
- Integrated. Cloud Dataproc has built-in integrations with other Cloud Platform services, such as BigQuery, Cloud Storage, Cloud Bigtable, and Google Cloud Logging so you have more than just a Spark or Hadoop cluster — you have a complete data platform. You can also use Cloud Dataproc initialization actions to extend the functionality of your clusters.
Our growing partner ecosystem offers certified support from several third-party tools and service partners. We're excited to collaborate with technology partners including Arimo, Attunity, Looker, WANdisco, and Zoomdata to make working in Cloud Dataproc even easier. Service providers like Moser, Pythian, and Tectonic are on standby to provide expert support during your Cloud Dataproc implementations. Reach out to any of our partners if you need help getting up and running.
To learn more about Cloud Dataproc, visit the Cloud Dataproc site, follow our getting started guide, take a look at a code example of how you can predict keno outcomes with Cloud Dataproc, or submit your questions and feedback on Stack Overflow.


