Explore the Galaxy of images with Cloud Vision API
Kaz Sato
Developer Advocate, Cloud AI
Ray Sakai
Product Manager, Reactive Inc.
At GCP NEXT 2016, the biggest Google Cloud Platform event held this year in San Francisco, Jeff Dean, Google Senior Fellow, presented the Cloud Vision API with Cloud Vision Explorer. This amazing demo is now available for anyone and we warmly invite you to give it a try.
To recap, Cloud Vision API is an image analysis service that's part of Cloud Platform. It enables you to understand the content of images by encapsulating powerful machine learning models in an easy-to-use REST API. It quickly classifies images into thousands of categories, detects individual objects and faces within images, and finds and reads printed words contained within images. It can analyze images uploaded on request or integrate with your image storage on Google Cloud Storage. The Label detection feature costs $2 per 1,000 images, and other features cost $0.60 per 1,000 images (see pricing). Anyone can start using the API for free for 1,000 images per month.
Discover the Galaxy with Cloud Vision API and Explorer
When you access the demo and after clicking on the launch button, you'll discover the "Galaxy" on your Google Chrome (latest version required).
The Galaxy contains approximately 20-25 groups of images whose names (e.g., "Sea," "Snow" and "Vehicle") try to reflect accurately the content of its images.
When you scroll up in a group, you can see thousands of thumbnails of the images surrounding you.

From Wikimedia Commons (CC-BY/CC-BY-SA)
If you click on one thumbnail, you'll see on the right side what Google's machine intelligence system has detected. In the case of the cat image available below, the system is confident that it's seeing “Cat,” “Pet” and “British shorthair” with respective confidence levels of 99%, 99% and 93%.
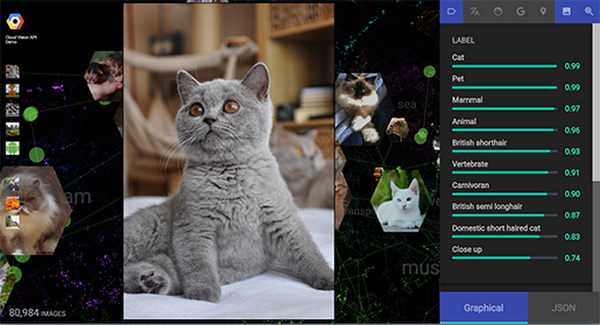
From Wikimedia Commons (CC-BY/CC-BY-SA)
Using Vision API to get insight from thousands of images
Where do the images in Explorer come from? The 80,984 images we used are taken from the Wikimedia Commons, one of the largest repositories of freely usable media. The Commons currently holds more than 650,000 uncategorized images. However, the absence of image description makes it difficult to locate and use these images. This is where Google Cloud Vision API comes into play. This broad, unordered and disparate set of images is a great dataset to demonstrate Vision APIs capabilities.The mechanics behind Galaxy
One of the challenges in building the demo was to create the Galaxy. This challenge consisted in finding suitable mapping between the output of the Vision API and a 3D space in which each data point represents one single image and belongs to a specific group, called a cluster. Inside this cloud of points, we expect similar images such as “cat” and “dog” to be closer, in comparison to other images such as “vehicle” or “playground.”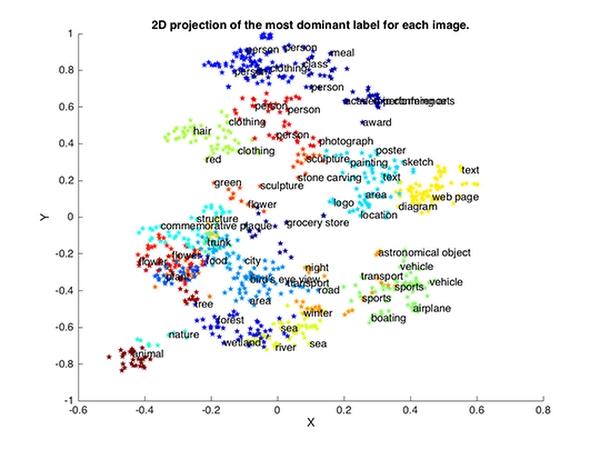
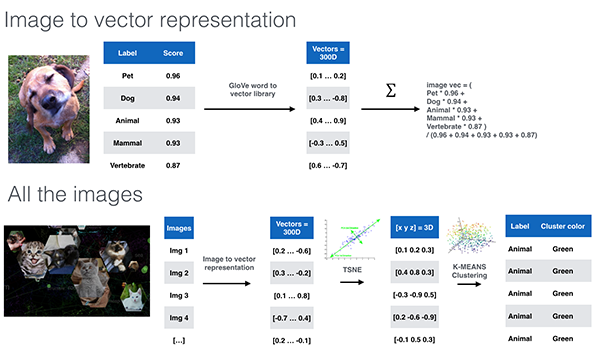
One idea is to define a vector representation of every image based on their labels and scores, and apply a dimensionality reduction to shrink the representations of the images into a 3D space. This vector representation consists of a high dimensional vectorization (i.e., usually more than 200 dimensions) of the labels “cat,” “dog,” etc, resulting from a word2vec dictionary called GloVe. The resulting vector for each image is a linear combination of the label word2vec vectors by the corresponding scores.
We now have as many vectors as we have images. In order to visualise this high-dimensional dataset, we used a dimensionality reduction technique called t-Distributed Stochastic Neighbor Embedding (t-SNE). This algorithm transforms each image vector into a 3D vector (x, y, z).
From Wikimedia Commons (CC-BY/CC-BY-SA)
Once the reduction has been performed, we want to detect any clusters (related to the categories: “person,” “chair,” “car” . . .) of the 3D points. To do that, we run a simple K-means algorithm with the Euclidean distance. Each cluster is associated with a color. It's also easy to detect the name of each cluster by taking the most common label among its points.
This model was implemented in Python and is based mostly in TensorFlow, the open source library for machine learning developed by Google.
Reaching a smooth experience with HTTP/2
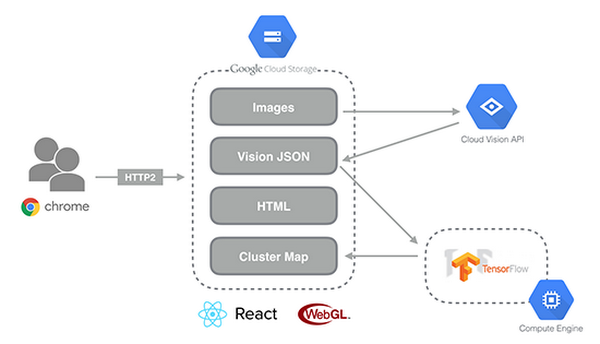
Another key feature of the Explorer experience is the smoothness of the UI. To make it possible with 100,000 images, the team adopted the successful combination of WebGL and React, backed by Google Cloud Storage.We integrated all the server logic into the JavaScript client and use only Cloud Storage as the backend service. We selected HTTP/2 protocol enabled by Cloud Storage to create the smooth thumbnails you can see when you zoom in with Explorer. Because we use Google Cloud Storage as the backend, the service is as scalable and available as the popular Google service without all the inconveniences of designing and operating the web service.
The source code has now been published on Reactive GitHub repository. Please feel free to fork it and contribute to this new open-source project!
Jeff Dean’s keynote speech showed that the combination of Cloud Vision API with dimensionality reduction and cluster analysis techniques works effectively to visualize the organization of thousands of images. This approach could be applied for various use cases to build a 3D catalog of an image repository, such as an interactive media explorer for photo libraries, for individuals and professionals. We can’t wait to see how you put it to use in your world.



