Cloud SQL for PostgreSQL adds high availability and replication
Brett Hesterberg
Product Manager, Google Cloud Platform
Grace-Ann Baker
Product Manager
Cloud SQL for PostgreSQL users, we heard you loud and clear, and added support for high availability (HA) and read replicas, helping you ensure your database workloads are fault tolerant.
The beta release of high availability provides isolation from failures, and read replicas provide additional read performance — requirements for demanding workloads.
As a global retail company, who uses digital innovation and data collaboration to enrich consumers' experiences with retailers and venues, we have very high availability requirements and we trust Cloud SQL for PostgreSQL with our data.
— Peter McInerney, Senior Director of Technical Operations at Westfield Retail Solutions
We love Postgres and rely upon it for many production workloads. While our Compute Engine VMs running Postgres have never gone down, the added peace of mind provided by HA and read replicas combined with reduction in operations makes the decision to move to the new Cloud SQL for PostgreSQL a simple one.
— Jason Vertrees, CTO at RealMassive
Additional enhancements include database instance cloning and higher performance instances with up to 64 vCPU cores and 416GB of RAM. Cloud SQL for PostgreSQL is also now part of the Google Cloud Business Associates Agreement (BAA) for HIPAA covered customers. And in case you missed it, we added support for 19 extensions this summer.
Understanding the high availability configuration
The high availability configuration on Cloud SQL for PostgreSQL is backed by Google's new Regional Disks, which synchronously replicate data at the block-level between two zones in a region. Cloud SQL continuously health-checks HA instances and automatically fails over if an instance is not healthy. The combination of synchronous disk replication and automatic failover provides isolation from many types of infrastructure, hardware and software failures.
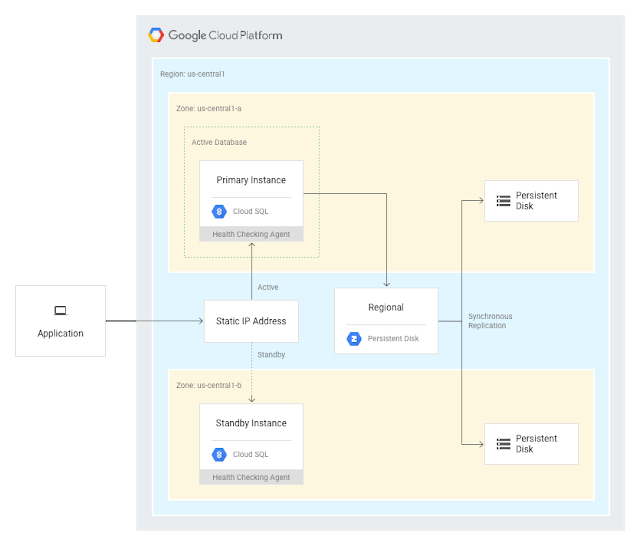
What triggers a failover?
Both primary and standby instances of Cloud SQL for PostgreSQL send a heartbeat signal, which is evaluated to define an availability state for the master instance. Cloud SQL monitors the heartbeats, and if it doesn’t detect multiple heartbeats from the primary instance (and the standby instance is healthy), starts a failover operation.
What happens during and after a failover?
During failover, Cloud SQL transfers the IP address and name of the primary instance to the standby instance and initializes the database. After failover, an application resumes connection to the new master instance without needing to change its connection string because the IP address moved automatically. Regional disks, meanwhile, ensure that all previously committed database transactions, right up to the time of the failure, were persisted and available after failover.
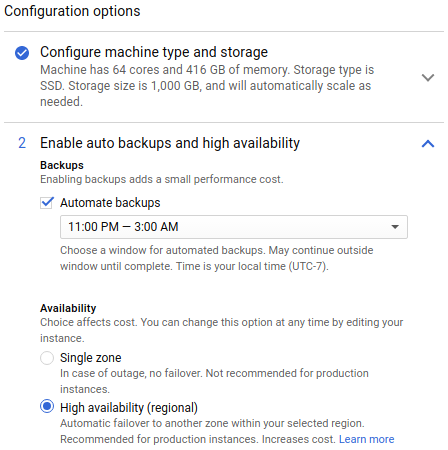
How to create a high availability instance
Creating a new HA instance is easy, as is upgrading existing Cloud SQL for PostgreSQL single instances. When creating or editing an instance, expand the "Configuration options" and select "High availability (regional)" in the Availability section:
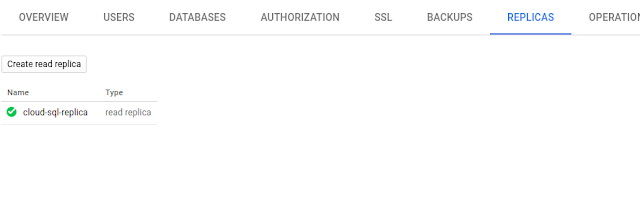
Quickly scale out with read replicas
Read replicas are useful for scaling out read load and for ad-hoc reporting. To create a read replica, select your primary Cloud SQL for PostgreSQL instance and click "Replicas" on the Instance details page.
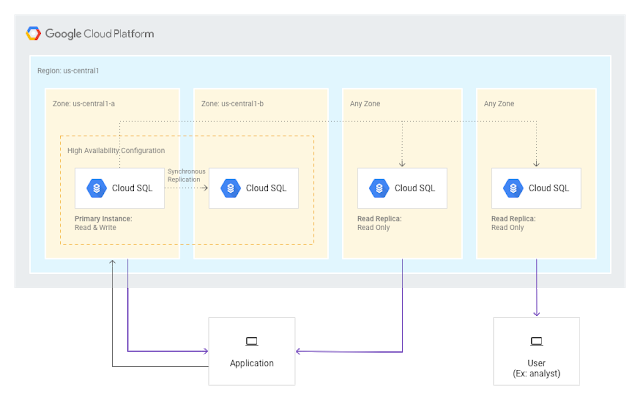
By combining high availability instances and read replicas, you can build a fault-tolerant, high performance PostgreSQL database cluster:
Get started
Sign up for a $300 credit to try Cloud SQL and the rest of GCP. Start with inexpensive micro instances for testing and development, and then, when you’re ready, you can easily scale them up to serve performance-intensive applications. As a bonus, everyone gets the 100% sustained use discount during the beta period, regardless of usage.
With Cloud SQL, we still feel like we’re just getting started. We hope you’ll come along for the ride and let us know what you need to be successful at Issue Tracker and by joining the Cloud SQL discussion group. Please keep the feedback coming!



