Analyzing your BigQuery usage with Ocado Technology’s GCP Census
Marcin Kołda
Senior Software Engineer at Ocado Technology
Editor’s note: Today we hear from Google Cloud customer Ocado Technology, which created (and open sourced!) a program to give them at-a-glance insights about their data warehouse usage, by reading BigQuery metadata. Read on to learn about how they architected the tool, what kinds of questions it can answer—and whether it might be useful in your own environment.
Here at Ocado Technology, we use a wide range of Google Cloud Platform (GCP) big data products for data-driven decisions and machine learning. Notably, we use Google BigQuery as the main storage solution for data analytics in the Ocado Smart Platform, our proprietary solution for operating online retail businesses.
Because BigQuery is so central to the Ocado platform, we wanted an easy way to get a bird’s eye view of the data stored in it. So we created GCP Census a tool that collects metadata about BigQuery tables and stores it back into BigQuery for analysis.
To have a better overview of all the data stored in BigQuery, we wanted to ask:
- Which datasets/tables are the largest or the most expensive?
- How many tables/partitions do we have?
- How often are tables/partitions updated over time?
- How are our datasets/tables/partitions growing over time?
- Which tables/datasets are stored in a specific location?
Our BigQuery domain
We store petabytes of data in BigQuery, divided into multiple GCP projects and hundreds of thousands of tables. BigQuery has many useful features for enterprise cloud data warehouses, especially in terms of speed, scalability and reliability. One example is partitioned tables rather than daily tables, which we recently adopted for their numerous benefits. At the same time, partitioned tables increased the complexity and scale of our BigQuery environment, and BigQuery offers limited ways of analysing metadata:- overall data size per project (from billing data)
- single table size (from BigQuery UI or REST API)
- __TABLES_SUMMARY__ and __PARTITIONS_SUMMARY__ provide only basic information, like list of tables/partitions and last update time
GCP Census architecture
The resulting tool, GCP Census, is a Google App Engine app written in Python that regularly collects metadata about BigQuery tables and stores it in BigQuery.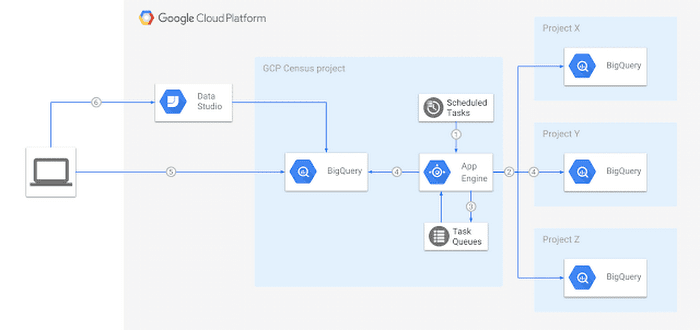
Here's how it works:
- App Engine cron triggers a daily run
- GCP Census crawls metadata from all projects/datasets/tables to which it has access
- It creates a task for each table and schedules it for execution in App Engine Task Queue
- A task worker then retrieves table metadata using the REST API and streams it into the metadata tables. In case of partitioned tables, GCP Census also retrieves the partitions’ summary by querying the partitioned table and stores the metadata in partition_metadata table
Using GCP Census
There are several benefits to using GCP Census. Now you can get answers to all the questions by querying BigQuery from the UI or the API.You can find below a few examples of how you can query GCP Census metadata.
- Count all data to which GCP Census has access
SELECT sum(numBytes) FROM
`YOUR-PROJECT-ID.bigquery_views.table_metadata_v1_0` - Count all tables and partitions
SELECT count(*)
FROM `YOUR-PROJECT-ID.bigquery_views.table_metadata_v1_0`
SELECT count(*) FROM `YOUR-PROJECT-ID.bigquery_views.partition_metadata_v1_0` - Select top 100 largest datasets
SELECT projectId, datasetId, sum(numBytes) as totalNumBytes
FROM `YOUR-PROJECT-ID.bigquery_views.table_metadata_v1_0`
GROUP BY projectId, datasetId ORDER BY totalNumBytes DESC LIMIT 100 - Select top 100 largest tables
SELECT projectId, datasetId, tableId, numBytes
FROM `YOUR-PROJECT-ID.bigquery_views.table_metadata_v1_0`s
ORDER BY numBytes DESC LIMIT 100 - Select top 100 largest partitions
SELECT projectId, datasetId, tableId, partitionId, numBytes
FROM `YOUR-PROJECT-ID.bigquery_views.partition_metadata_v1_0`
ORDER BY numBytes DESC LIMIT 100
Below you can find a screenshot with one of our dashboards (all real data has been redacted).
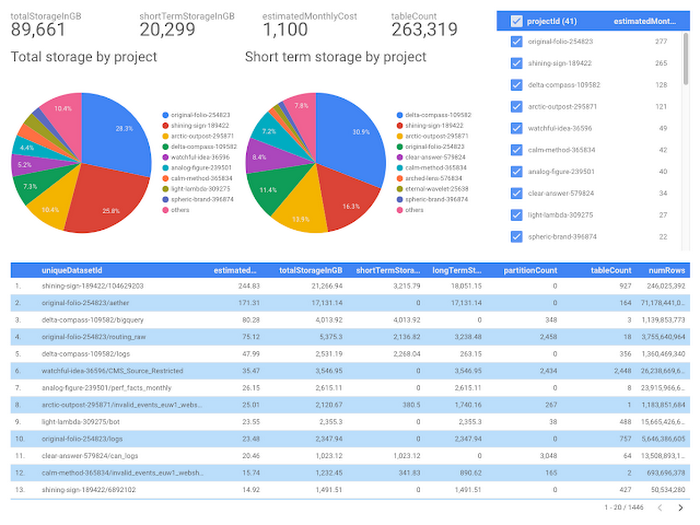
With GCP Census, we’ve learned some of the characteristics of our data; for example, we now know which data is modified daily or which historical partitions have been modified recently. We were also able to identify potential cost optimization areas—huge temporary tables that no one uses but that were incurring significant storage costs. All in all, we’ve learned a lot about our operations, and saved a bunch of money!
You can find the source code for GCP Census at Github at https://github.com/ocadotechnology/gcp-census, plus the required steps needed for installation and setup. We look forward to your ideas and contributions!



