220,000 cores and counting: Mathematician breaks record for largest ever Compute Engine job
Alex Barrett
GCP Blog Editor, Google Cloud Platform Blog
Michael Basilyan
Product Manager, Compute Engine
Editor's Note: This post was updated on October 16, 2019.
An MIT researcher recently broke the record for the largest ever Compute Engine cluster, with 220,000 cores on Preemptible VMs, the largest known high-performance computing cluster to ever run in the public cloud.
Andrew V. Sutherland is a computational number theorist and Principal Research Scientist at MIT, and is using Compute Engine to explore generalizations of the Sato-Tate Conjecture and the conjecture of Birch and Swinnerton-Dyer to curves of higher genus. In his latest run, he explored 1017 hyperelliptic curves of genus 3 in an effort to find curves whose L-functions can be easily computed, and which have potentially interesting Sato-Tate distributions. This yielded about 70,000 curves of interest, each of which will eventually have its own entry in the L-functions and Modular Forms Database (LMFDB).
Sutherland published his findings in the Proceedings of the Thirteenth Algorithmic Number Theory Symposium.
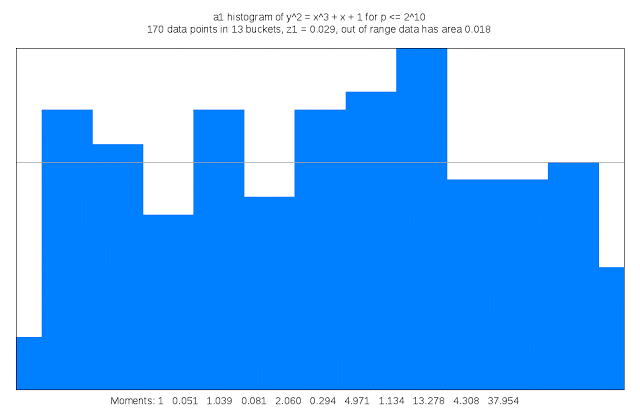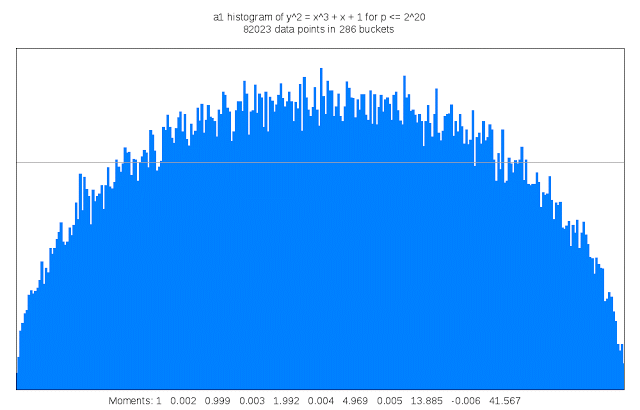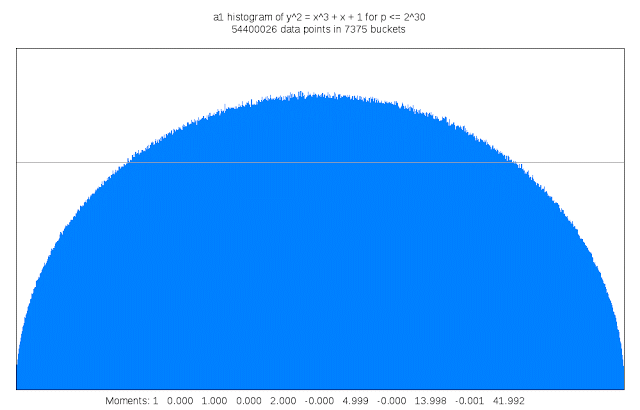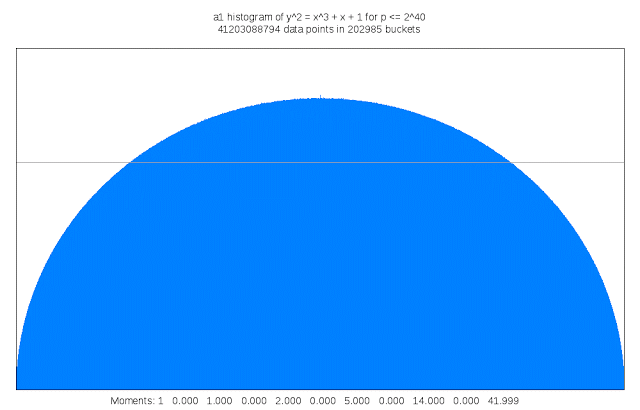
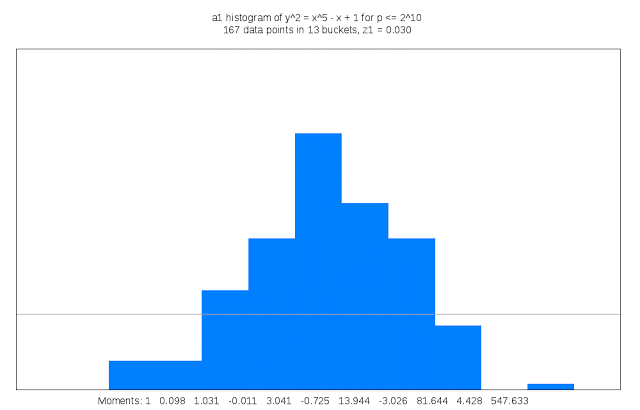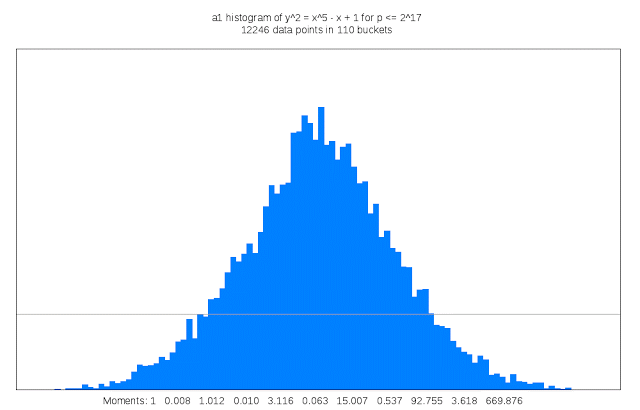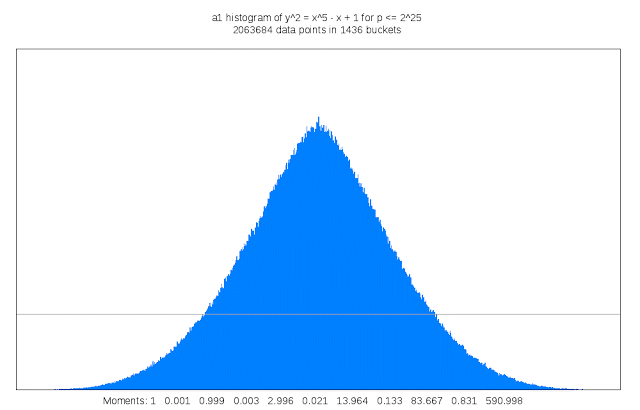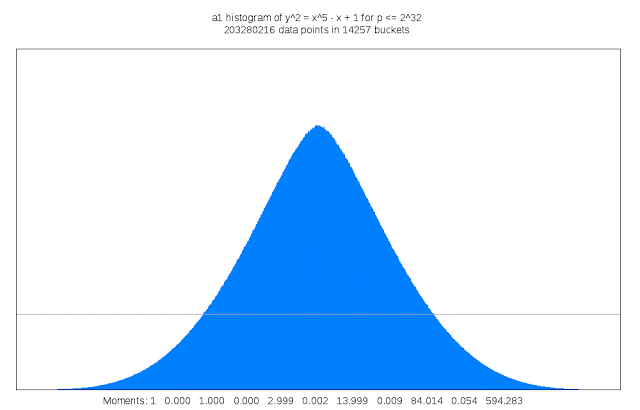
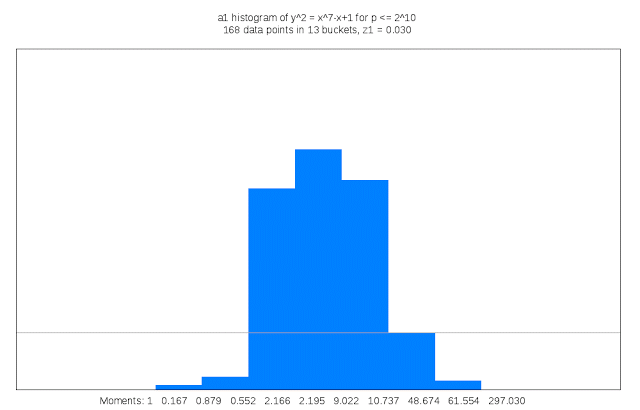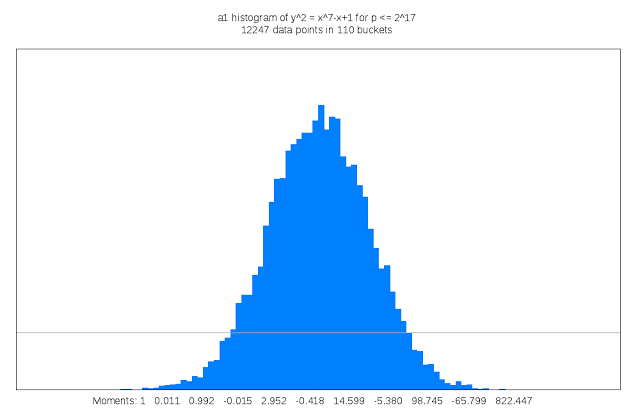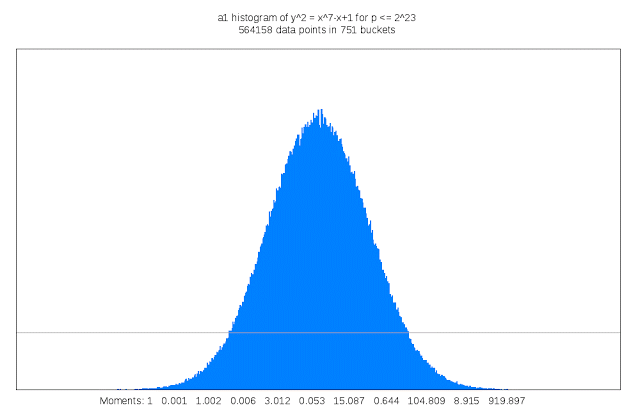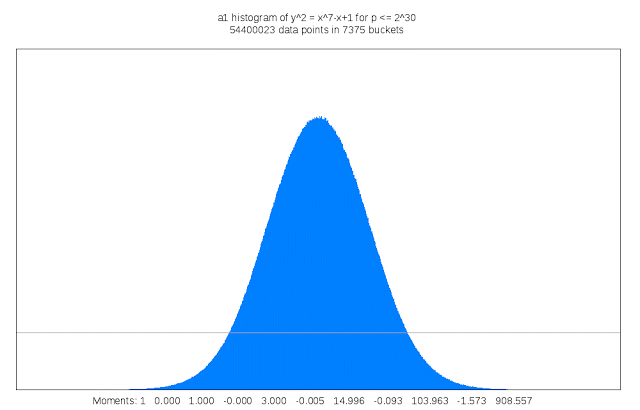
Finding suitable genus 3 curves “is like searching for a needle in a fifteen-dimensional haystack,” Sutherland said. “Sometimes I like to describe my work as building telescopes for mathematicians.”
It also requires a lot of compute cycles: For each curve that is examined its discriminant must be computed; the discriminant of a curve serves as an upper bound on the complexity of computing its L-function. This task is trivial in genus 1, but in genus 3 may involve evaluating a 50 million term polynomial in 15 variables. Each curve that is a candidate for inclusion in the LMFDB must also have many other of its arithmetic and geometric invariants computed, including an approximation of its L-function and Sato-Tate distribution, as well as information about any symmetries it may possess. The results can be quite large, and some of this information is stored as Cloud Storage nearline objects. Researchers can browse summaries of the results on the curve’s home page in the LMFDB, or download more detailed information to their own computer for further examination. The LMFDB provides an online interface to some 400 gigabytes of metadata housed in a MongoDB database that also runs on Compute Engine.
Sutherland began using Compute Engine in 2015. For his first-ever job, he fired up 2,250 32-core instances and completed about 60 CPU-years of computation in a single afternoon.
Before settling on Compute Engine, Sutherland ran jobs on his own 64-core machine, which could take months, or wrangled for compute time on one of his institution’s compute clusters. But getting the number of cores he needed often raised eyebrows, and he was limited by the software configurations he could use. By running on Compute Engine, Sutherland can install exactly the operating system, libraries, and applications he needs, and thanks to root access, he can update his environment at will.
Specifically, Sutherland uses Compute Engine Preemptible VMs, full-featured instances that are priced up to 80% less than regular equivalents, but can be interrupted by Compute Engine. That was fine with Sutherland. His computations are embarrassingly parallel -- they can be easily separated into multiple, independent tasks -- and he grabs available instances across any and all Google Cloud Regions. An average of about 2-3% of his instances are typically preempted in any given hour, but a simple script automatically restarts them as needed until the whole job is complete.
To coordinate the instances working on a job, Sutherland uses a combination of Cloud Storage and Datastore. He used the python client API to implement a simple ticketing system in Datastore that assigns tasks to instances. Instances periodically checkpoint their progress on their local disks from which they can recover if preempted, and they store their final output data in a Cloud Storage bucket where it may undergo further post-processing once the job has finished.
All told, having access to the scale and flexibility of Compute Engine has freed Sutherland up to think much bigger with his research. For his next run, he hopes to expand his search to non-hyperelliptic curves of genus 3, breaking his own record with a 400,000-core cluster. “It changes your whole outlook on research when you can ask a question and get an answer in hours rather than months,” he said. “You ask different questions.”
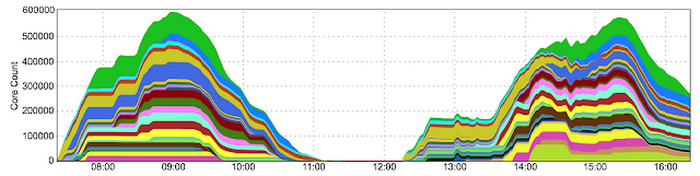
Update: June 12, 2017
We got word from Andrew that he ran a job this past weekend that hit 580,000 cores, breaking his own record from just two months ago. That’s roughly 300 years of core-years of compute time for $20,000 -- not bad for a lazy Sunday.
More and more researchers are using GCP for HPC jobs in the realms of mathematics, drug discovery, rendering, seismic exploration -- you name it. If you have big questions that need big compute, our free trial gives you $300 in credits to get started.


