Getting started with Feast on Google Cloud
Danny Chiao
Engineering Lead, Tecton
Kavitha Rajendran
AI Specialist, Solutions Architect
This post is the second in a short series of blog posts about Feast on Google Cloud. In this post, we’ll provide an introductory tutorial for building an ecommerce reranking model for product recommendations using Feast on Google Cloud.
Overview
Open-source approaches provide organizations with the flexibility to deploy—and, if necessary, migrate—critical workloads to, across, and from public cloud platforms. The same applies to artificial intelligence (AI) and machine learning (ML).
Every organization and ML project has unique requirements, and Google Cloud provides multiple solutions to address different needs, including a variety of open-source options. For example, some customers choose Vertex AI, Google Cloud’s fully-featured AI/ML platform to train, test, tune, and serve ML models, including gen AI solutions and support for open-source frameworks and models. Others choose to build a custom ML platform by combining open-source technologies with Google Cloud managed services for additional flexibility.
Feast, an ML feature store, is one such open-source technology. It helps store, manage, and serve features for machine learning models across the key stages of the ML model development process. It also integrates with multiple database backends and ML frameworks that can work across or off cloud platforms.
The first installment of this series described what a feature store does and what makes Feast a good choice for organizations who prefer the flexibility of open source on Google Cloud. In this second installment, we’ll focus on using Feast to build an ecommerce recommendation system.
Building recommendation systems
Recommendation systems suggest products or services to users based on their past behavior. Similar systems are used by a wide variety of different businesses in retail, streaming media, social media, and digital marketing to personalize the customer experience.
One common approach to building a recommendation system is to use a multi-stage process. In many of these systems, the two most important stages consist of the following:
- Candidate generation: This step generates a list of potential products or services that a given user (say, a customer using a retailer’s mobile app) might be interested in. This can be done using a variety of methods, such as collaborative filtering or content-based filtering.
- Reranking: This step takes the list of candidate products or services and reranks them based on the user’s past behavior, such as their recent purchase history or items they’ve viewed. Ranking can be done using a variety of machine learning models, such as linear regressions or deep learning. For example, a recommendation system might predict the likelihood that a given user, such as a user of a mobile shopping app, will interact with that candidate product.
In this post, we'll explore the second reranking stage and cover how Feast makes it easier to build a reranking model for product recommendations.
Other critical components for product recommendations
The first step to building a recommendation system is to define the ML features that will be used. These features can be divided into three categories:
- User features: These features describe the recipient of the recommendations (i.e., the user), such as their age, gender, location, and purchase history.
- Product features: These features describe the products available for sale, including their price, rating, and category.
- Combined features: These features combine user and product features, such as the number of times a user has viewed a product or the last five product categories a user has purchased.
Feast makes it easy to store, manage, and serve features for machine learning models. It provides a unified API for accessing features from a variety of data sources, such as BigQuery and Google Cloud Storage. Typically, Feast users generate these features upstream; for example, they will run a Kubernetes CronJob or a BigQuery scheduled query.
In addition, Feast provides a variety of capabilities that make it ideal for building recommendation systems. Some of these capabilities include:
- Feature definitions: Feast allows you to define features in a declarative way. This makes it easy to keep track of the features that are used by your recommender system and enables feature reuse across the organization.
- Training data generation: Feast provides a feature retrieval method that generates a point-in-time correct training dataset. This can be useful in training a reranking model while minimizing differences between ML model outputs during training and deployment.
- Online feature serving: Feast provides a variety of ways to make serving features easier, abstracting away much of the complexity in writing and reading feature values. For example, in this tutorial, we will leverage Cloud Bigtable to serve the latest feature values at low latency.
For batch training and model serving at scale, you’ll also need offline compute and an online data store. With Feast, you can plug into your existing Google Cloud infrastructure.
Offline compute is essential in batch systems since it powers both training data generation and materialization workflows. Feast leverages the power of BigQuery to rapidly process large amounts of data and feature values to generate point-in-time correct feature data. It also uses BigQuery to pre-compute batch features, which can then be loaded into a low-latency online store to power model inference.
In order to serve feature data in real time to users, Feast needs a low-latency online store like Cloud Bigtable. Real-time applications often require feature data to be available in single-digit milliseconds to surface suggestions to users in a timely manner. As a managed service that provides excellent write throughput and low-latency reads, Cloud Bigtable is a good choice. It’s also highly scalable and can meet the needs of the most demanding applications. What’s more, its performance characteristics also make it ideal for ML models that require online training. Feast also supports Memorystore for Redis as an online store option.
Key concepts in Feast
When using Feast for product recommendations, you’ll need to understand the following key concepts.
Concept 1: Feature view
A feature view is a grouping of time-series features that originate from the same data source. A feature view can come from a table in your data warehouse, an SQL query, or request payloads issued by your applications.
Feature views consist of zero or more entities, one or more features, and a timestamped data source. Feature views allow Feast to model your existing feature data in a consistent way in both your offline environment (i.e., training and inference) and your online (i.e., serving) environment.
Timestamps play an important role in Feature views because Feast generates point-in-time correct feature data. This means that if you're creating a training example for a user purchase one month ago, you’ll want feature values from the same period to avoid data leakage, which can take place when you train models with data that differs from the data that will be available to the model in production. Data leakage in your training data sets can introduce skewed model performance between training and serving and cause your app to issue poor-performing product recommendations.
Concept 2: Entity
Feast’s Entity concept represents the entities that your features describe. In Feast, Entities are the objects you use to reference these entities during the training and inference processes. If your model needs to generate features from multiple data sources, Feast will use Entities to identify which feature values should be joined together when retrieving features.
For example, in an ecommerce recommendation system, you may want to generate features for a given mobile app user and product pair. Here, the entities are user (i.e., users of your ecommerce mobile app) and product (i.e., the products available for sale in your app).
Concept 3: Materialization
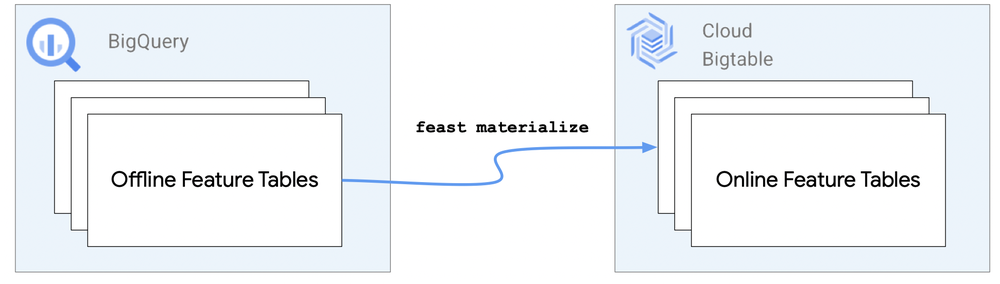
Materialization is the process of creating a snapshot of the latest feature values from the offline store and storing them in the online store. This allows Feast to serve the latest features to machine learning models in a timely manner to improve the accuracy and performance of your models and ensure the best results for your users.
When writing a new feature, users will leverage Feast to ingest online features from historical data. Then they will, on a schedule, incrementally update feature data, generally at a regular cadence, to keep the online store up-to-date. Feast supports two kinds of materialization:
feast materialize <start-time> <end-time>: Processes all feature values from the offline store within a given time range.feast materialize-incremental <end-time>: Tracks what time ranges were already processed, so you only process new data.
How to use Feast for product recommendations
The following tutorial will showcase how Feast works with BigQuery and Cloud Bigtable to power a re-ranking model built on the TheLook eCommerce public dataset, a fictitious eCommerce clothing site.
In the tutorial, you’ll learn how to:
- Configure Feast to use BigQuery and Cloud Bigtable
- Generate features with BigQuery
- Load data and regularly ingest features in Cloud Bigtable
- Retrieve offline features to generate training data and the latest online features
Follow along at Feast on Google Cloud!

Production Deployment
See also https://docs.feast.dev/how-to-guides/running-feast-in-production
There are several things to consider as you approach the process of taking a notebook-based system like this to a production environment:
Version control: While notebooks are a great tool for prototyping and validation, checking your ML features into a version-controlled repository is a more scalable solution if you plan to deploy them in production.
Data pipelines
Generating features for production deployment requires building and managing both batch and streaming pipelines to regularly ingest fresh features for your model training and inference systems.
Scaling materialization and feature serving
Feast users commonly scale up their Feast deployments using Google Kubernetes Engine (GKE). GKE provides a managed Kubernetes experience that allows users to overcome scaling limitations for two key components:
- Materialization: Feast uses an in-process materialization engine by default, which may not scale well for large data volumes. Users can leverage GKE to overcome this limitation by processing multiple ranges of data concurrently across different Kubernetes jobs. An example implementation is available in Feast using the Bytewax materialization engine.
- Feature serving: Feast provides a feature server to retrieve features from Cloud Bigtable. With GKE, users can easily scale the feature server up or down to accommodate changes in traffic.
Managing costs in production
After you’ve had the opportunity to review the performance of models in a real-world production setting, it’s important to manage your costs. Two common practices include:
- Building a caching layer for the Feast online store. This can help keep your product recommendations timely and relevant, especially in scenarios where online feature data does not need to change very frequently.
- Expiring feature values in the online store, such as by setting a garbage collection policy on Cloud Bigtable.
Congrats, you’ve made it to the end of the tutorial! We hope it has helped you understand how to power a simple product recommendation system using BigQuery, Cloud Bigtable, and Feast.
Next steps
For more information about using Feast, we recommend reviewing Feast’s documentation and reading the BigQuery guide and Cloud Bigtable guide.
If you’re looking for an off-the-shelf feature store solution, check out Vertex AI Feature Store, Google Cloud’s fully-managed feature store that provides a centralized repository for organizing, storing, and serving ML features and vector embeddings, that integrates directly with BigQuery and a broad range of industry-leading features and capabilities in Vertex AI.
Curious about what’s new with AI on Google Cloud? Read more about recent Vertex AI announcements at Google Cloud Next ‘23.




